在机器学习的算法评估中,尤其是分类算法评估中,我们经常听到精确率(precision)与召回率(recall),RoC曲线与PR曲线这些概念,那这些概念到底有什么用处呢?
1. 混淆矩阵(Confusion Matrix)
混淆矩阵是二分类问题的多维衡量指标体系,在样本不平衡时极其有用 。在混淆矩阵中,我们将少数类认为是正例,多数类认为是负例。在决策树,随机森林这些普通的分类算法里,即是说少数类是1,多数类是0。在 SVM 里,就是说少数类是1,多数类是-1。普通的混淆矩阵,一般使用{0,1}来表示 标准二分类的混淆矩阵,如图所示:

混淆矩阵中,永远是真实值在前,预测值在后。其实可以很容易看出,11和00的对角线就是全部预测正确的,01和10的对角线就是全部预测错误的。基于混淆矩阵,我们有六个不同的模型评估指标,这些评估指标的范围都在[0,1]之间,所有以11和00为分子的指标都是越接近1越好,所以以01和10为分子的指标都是越接近0越好。对于所有的指标,我们用橙色表示分母,用绿色表示分子。
2. 评价指标
基于混淆矩阵,我们学习了总共六个指标:准确率Accuracy,精确度Precision,召回率Recall,精确度和召回度的平衡指标F measure,特异度Specificity,以及假正率FPR
常用的标记:
- True Positives,TP:预测为正样本,实际也为正样本的特征数
- False Positives,FP:预测为正样本,实际为负样本的特征数
- True Negatives,TN:预测为负样本,实际也为负样本的特征数
- False Negatives,FN:预测为负样本,实际为正样本的特征数
2.1 准确率 (Accuracy )

模型整体效果:准确率Accuracy就是所有预测正确的所有样本除以总样本,通常来说越接近1越好
2.2 精确度Precision
又叫查准率

表示所有被我们预测为是少数类的样本中,真正的少数类所占的比例。 在支持向 量机中,精确度可以被形象地表示为决策边界上方的所有点中,红色点所占的比例。精确度越高,代表我们捕捉正确的红色点越多,对少数类的预测越精确。精确度越低,则代表我们误伤了过多的多数类。精确度是 ”将多数类判错后所需付出成本“ 的衡量 .

2.3 召回率Recall
又被称为敏感度(sensitivity),真正率,查全率

表示所有真实为1的样本中,被我们预测正确的样本所占的比例。在支持向量机中,召回率可以被表示为,决策边界上方的所有红色点占全部样本中的红色点的比例。召回率越高,代表我们尽量捕捉出了越多的少数类,召回率越低,代表我们没有捕捉出足够的少数类
注意召回率和精确度的分子是相同的(都是11),只是分母不同。而召回率和精确度是此消彼长的,两者之间的平衡代表了捕捉少数类的需求和尽量不要误伤多数类的需求的平衡。究竟要偏向于哪一方,取决于我们的业务需求:究竟是误伤多数类的成本更高,还是无法捕捉少数类的代价更高
2.4 F1 -measure
为了同时兼顾精确度和召回率,我们创造了两者的调和平均数作为考量两者平衡的综合性指标,称之为F1 measure。两个数之间的调和平均倾向于靠近两个数中比较小的那一个数,因此我们追求尽量高的F1 measure,能够保证我们的精确度和召回率都比较高。F1 measure在[0,1]之间分布,越接近1越好

2.5 假负率(False Negative Rate)
从Recall延申出来的另一个评估指标叫做假负率(False Negative Rate),它等于 1 - Recall,用于衡量所有真实为1的样本中,被我们错误判断为0的,通常用得不多。
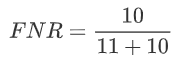
2.6 特异度(Specificity)

表示所有真实为0的样本中,被正确预测为0的样本所占的比例。在支持向量机中,可以形象地 表示为,决策边界下方的点占所有紫色点的比例 。
特异度衡量了一个模型将多数类判断正确的能力,而1 - specificity就是一个模型将多数类判断错误的能力,这种能力被计算如下,并叫做假正率(False Positive Rate)
2.7 假正率(False Positive Rate)

3. RoC曲线和PR曲线
以 TPR 为y轴,以 FPR 为x轴,我们就直接得到了 RoC曲线。从FPR和TPR的定义可以理解,TPR越高,FPR越小,我们的模型和算法就越高效。也就是画出来的RoC曲线越靠近左上越好。如下图左图所示。从几何的角度讲,RoC曲线下方的面积越大越大,则模型越优。所以有时候我们用RoC曲线下的面积,即 AUC(Area Under Curve)值来作为算法和模型好坏的标准。

以精确率为y轴,以召回率为x轴,我们就得到了PR曲线。仍然从精确率和召回率的定义可以理解,精确率越高,召回率越高,我们的模型和算法就越高效。也就是画出来的PR曲线越靠近右上越好。如上图右图所示。
使用RoC曲线和PR曲线,我们就能很方便的评估我们的模型的分类能力的优劣了。
- P-R曲线适合对比特定数据集下的模型预测效果好坏。
- ROC曲线适合对比数据集分布变动大时,对模型结果的对比。