最大熵模型(maximum entropy model, MaxEnt)也是很典型的分类算法了,它和逻辑回归类似,都是属于对数线性分类模型。在损失函数优化的过程中,使用了和支持向量机类似的凸优化技术。理解了最大熵模型,对逻辑回归,支持向量机以及决策树算法都会加深理解。
1. 熵和条件熵
熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
\[H(X) = -\sum\limits_{i=1}^{n}p_i logp_i\]其中 n 代表 X 的 n 种不同的离散取值。而 \(p_i\) 代表了X取值为i的概率,log为以2或者e为底的对数。
熟悉了一个变量X的熵,很容易推广到多个个变量的联合熵,这里给出两个变量X和Y的联合熵表达式:
\[H(X,Y) = -\sum\limits_{i=1}^{n}p(x_i,y_i)logp(x_i,y_i)\]有了联合熵,又可以得到条件熵的表达式 H(Y | X),条件熵类似于条件概率,它度量了我们的Y在知道X以后剩下的不确定性。表达式如下:
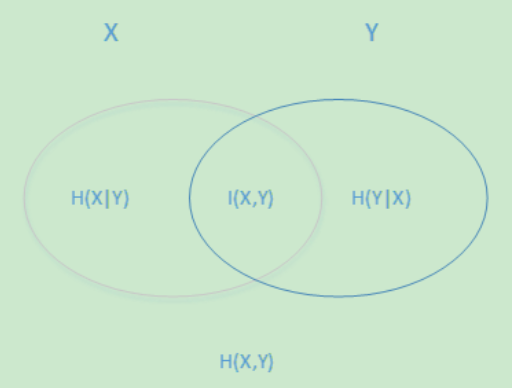
\[H(Y |X) = -\sum\limits_{i=1}^{n}p(x_i,y_i)logp(y_i|x_i) = \sum\limits_{j=1}^{n}p(x_j)H(Y|x_j)\]用下面这个图很容易明白他们的关系。左边的椭圆代表H(X),右边的椭圆代表H(Y),中间重合的部分就是我们的互信息或者信息增益 \(I\)(X,Y), 左边的椭圆去掉重合部分就是H(X |Y),右边的椭圆去掉重合部分就是H(Y|X)。两个椭圆的并就是H(X,Y)。
2. 最大熵模型的定义
最大熵模型假设分类模型是一个条件概率分布 $P(Y | X)$ ,X为特征,Y为输出。
给定一个训练集 \({(x^{(1)},y^{(1)}), (x^{(2)},y^{(2)}), ... ,(x^{(m)},y^{(m)})}\) 其中x为n维特征向量,y为类别输出。我们的目标就是用最大熵模型选择一个最好的分类类型。
在给定训练集的情况下,我们可以得到总体联合分布 \(P(X,Y)\) 的经验分布 \(\overline{P}(X,Y)\) , 和边缘分布 \(P(X)\) 的经验分布 \(\overline{P}(X)\) 。\(\overline{P}(X,Y)\) 即为训练集中 X , Y 同时出现的次数除以样本总数m,\(\overline{P}(X)\) 即为训练集中X出现的次数除以样本总数 m。
用特征函数 \(f(x,y)\) 描述输入x和输出y之间的关系。定义为:
\[f(x,y)= \begin{cases} 1& {x与y满足某个关系}\\ 0& {否则} \end{cases}\]可以认为只要出现在训练集中出现的 \((x^{(i)},y^{(i)})\) , 其 \(f(x^{(i)},y^{(i)}) = 1\) 同一个训练样本可以有多个约束特征函数。
特征函数 \(f(x,y)\) 关于经验分布 \(\overline{P}(X,Y)\) 的期望值,用 \(E_{\overline{P}}(f)\) 表示为:
\[E_{\overline{P}}(f) = \sum\limits_{x,y}\overline{P}(x,y)f(x,y)\]特征函数 \(f(x,y)\) 关于条件分布 $P(Y | X)$ 和经验分布 \(\overline{P}(X)\) 的期望值,用 \(E_{P}(f)\) 表示为:
\[E_{P}(f) = \sum\limits_{x,y}\overline{P}(x)P(y|x)f(x,y)\]如果模型可以从训练集中学习,我们就可以假设这两个期望相等。即:
\[E_{\overline{P}}(f) = E_{P}(f)\]上式就是最大熵模型学习的约束条件,假如我们有 M 个特征函数 \(f_i(x,y) (i=1,2...,M)\) 就有M个约束条件。可以理解为我们如果训练集里有 m 个样本,就有和这 m 个样本对应的 M 个约束条件。
这样我们就得到了最大熵模型的定义如下:
假设满足所有约束条件的模型集合为:
\[E_{\overline{P}}(f_i) = E_{P}(f_i) (i=1,2,...M)\]定义在条件概率分布 $P(Y | X)$ 上的条件熵为:
\[H(P) = -\sum\limits_{x,y}\overline{P}(x)P(y|x)logP(y|x)\]我们的目标是得到使 \(H(P)\) 最大的时候对应的 $P(y | x)$ ,这里可以对 \(H(P)\) 加了个负号求极小值,这样做的目的是为了使 \(-H(P)\) 为凸函数,方便使用凸优化的方法来求极值。
示例

在英汉翻译中,take有多种解释例如上文中存在7中,在没有任何限制的条件下,最大熵原理认为翻译成任何一种解释都是等概率的。
\[\mathrm{p}(\mathrm{t} 1 | \mathrm{x})=\mathrm{p}(\mathrm{t} 2 | \mathrm{x})=\ldots=\mathrm{p}(\mathrm{t} 7 | \mathrm{x})=1 / 7\]实际中总有或多的限制条件,例如t1,t2比较常见,假设满足
\[\mathrm{p}(\mathrm{t} 1 | \mathrm{x})+\mathrm{p}(\mathrm{t} 2 | \mathrm{x})=2 / 5\]同样根据最大熵原理,可以得出:
\[\begin{aligned} &\mathrm{p}(\mathrm{t} 1 | \mathrm{x})=\mathrm{p}(\mathrm{t} 2 | \mathrm{x})=1 / 5\\ &\mathrm{p}(\mathrm{t} 3 | \mathrm{x})=\mathrm{p}(\mathrm{t} 4 | \mathrm{x})=\mathrm{p}(\mathrm{t} 5 | \mathrm{x})=\mathrm{p}(\mathrm{t} 6 | \mathrm{x})=\mathrm{p}(\mathrm{t} 7 | \mathrm{x})=3 / 25 \end{aligned}\]实际的统计模型中,还需要引入特征提高准确率。例如take翻译为乘坐的概率小,但是当后面跟着交通工具的名词“bus”,概率就变得非常大。
用特征函数f(x,y)描述输入x,输出y之间的某一个事实,只有0和1两种值,称为二值函数。例如:
\[f(x, y)=\left\{\begin{array}{ll} {1} & {\text { if } y="乘坐" \text {and } \wedge \operatorname{next}(x)=^{\prime \prime} \text { bus" }} \\ {0} \end{array}\right.\]3 . 最大熵模型损失函数的优化
在上一节我们已经得到了最大熵模型的函数 \(H(P)\) 。它的损失函数 \(-H(P)\) 定义为:
\[\begin{equation} \underbrace{\min }_{P}-H(P)=\sum_{x, y} \bar{P}(x) P(y | x) \log P(y | x) \end{equation}\]约束条件为:
\[\begin{equation} E_{\bar{P}}\left(f_{i}\right)-E_{P}\left(f_{i}\right)=0 \qquad(i=1,2, \dots M) \end{equation}\] \[\sum\limits_yP(y|x) = 1\]由于它是一个凸函数,同时对应的约束条件为仿射函数,根据凸优化理论,这个优化问题可以用拉格朗日函数将其转化为无约束优化函数,此时损失函数对应的拉格朗日函数 \(L(P,w)\) 定义为:
\[L(P,w) \equiv -H(P) + w_0(1 - \sum\limits_yP(y|x)) + \sum\limits_{i=1}^{M}w_i(E_{\overline{P}}(f_i) - E_{P}(f_i))\]其中 \(w_i(i=1,2,...m)\) 为拉格朗日乘子。如果大家也学习过支持向量机,就会发现这里用到的凸优化理论是一样的,接着用到了拉格朗日对偶也一样。
拉格朗日函数,即为凸优化的原始问题 : \(\underbrace{ min }_{P} \underbrace{ max }_{w}L(P, w)\)
其对应的拉格朗日对偶问题为: \(\underbrace{ max}_{w} \underbrace{ min }_{P}L(P, w)\)
由于原始问题满足凸优化理论中的 KKT 条件,因此原始问题的解和对偶问题的解是一致的。这样我们的损失函数的优化变成了拉格朗日对偶问题的优化。
求解对偶问题的第一步就是求 \(\underbrace{ min }_{P}L(P, w)\) , 这可以通过求导得到。这样得到的 \(\underbrace{ min }_{P}L(P, w)\) 是关于w的函数 。记为:
\[\psi(w) = \underbrace{ min }_{P}L(P, w) = L(P_w, w)\]\(\psi(w)\) 即为对偶函数,将其解记为:
\[P_w = arg \underbrace{ min }_{P}L(P, w) = P_w(y|x)\]具体的是求 \(L(P, w)\) 关于$P(y | x)$的偏导数:
\[P(y|x) = exp(\sum\limits_{i=1}^{M}w_if_i(x,y) +w_0 -1) = \frac{exp(\sum\limits_{i=1}^{M}w_if_i(x,y))}{exp(1-w_0)}\]由于 $\sum\limits_yP(y | x) = 1$ ,可以得到 $P_w(y | x)$ 的表达式如下:
\[P_w(y|x) = \frac{1}{Z_w(x)}exp(\sum\limits_{i=1}^{M}w_if_i(x,y))\]其中,\(Z_w(x)\) 为规范化因子 ,定义为:
\[Z_w(x) = \sum\limits_yexp(\sum\limits_{i=1}^{M}w_if_i(x,y))\]这样我们就得出了 $P(y | x)$ 和 $w$ 的关系,从而可以把对偶函数 $\psi(w)$ 里面的所有的$P(y | x)$替换成用 $w$ 表示,这样对偶函数 $\psi(w)$ 就是全部用 $w$ 表示了。接着我们对 $\psi(w)$ )求极大化,就可以得到极大化时对应的 $w$ 向量的取值,带入 $P(y | x)$ 和 $w$ 的关系式, 从而也可以得到 $P(y | x)$ 的最终结果。
对 $\psi(w)$ 求极大化,由于它是连续可导的,所以优化方法有很多种,比如梯度下降法,牛顿法,拟牛顿法都可以。对于最大熵模型还有一种专用的优化方法,叫做改进的迭代尺度法(improved iterative scaling, IIS)。
4. 最大熵模型小结
最大熵模型在分类方法里算是比较优的模型,但是由于它的约束函数的数目一般来说会随着样本量的增大而增大,导致样本量很大的时候,对偶函数优化求解的迭代过程非常慢,scikit-learn甚至都没有最大熵模型对应的类库。但是理解它仍然很有意义,尤其是它和很多分类方法都有千丝万缕的联系。
最大熵模型的优点有:
a) 最大熵统计模型获得的是所有满足约束条件的模型中信息熵极大的模型,作为经典的分类模型时准确率较高。
b) 可以灵活地设置约束条件,通过约束条件的多少可以调节模型对未知数据的适应度和对已知数据的拟合程度
最大熵模型的缺点有:
a) 由于约束函数数量和样本数目有关系,导致迭代过程计算量巨大,实际应用比较难。