MySQL case when 实现行转列时为什么要用 max() 或者其他聚合函数
创建表
create table tb(
姓名 varchar(10),
课程 varchar(3),
分数 int(3)
);
insert into tb values ('张三','语文', 74),
('张三','数学', 83),
('张三','物理', 93),
('李四','语文', 74),
('李四','数学', 84),
('李四','物理', 94);
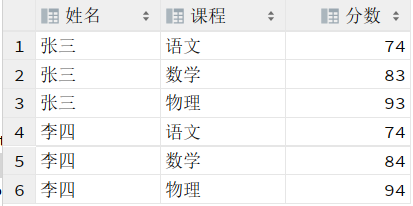
想要显示的结果是 :姓名 语文 数学 物理 这种形式的(就是行转列)
sql 语句1:
SELECT `姓名`,
(CASE `课程` WHEN '语文' THEN `分数` ELSE 0 END) '语文',
(CASE `课程` WHEN '数学' THEN `分数` ELSE 0 END) '数学',
(CASE `课程` WHEN '物理' THEN `分数` ELSE 0 END) '物理'
FROM TB
GROUP BY `姓名`;

这个结果是不对的
sql 语句2:
SELECT `姓名`,
MAX(CASE `课程` WHEN '语文' THEN `分数` ELSE 0 END) '语文',
MAX(CASE `课程` WHEN '数学' THEN `分数` ELSE 0 END) '数学',
MAX(CASE `课程` WHEN '物理' THEN `分数` ELSE 0 END) '物理'
FROM TB
GROUP BY `姓名`;

解析:
第一种 不加 max的时候
那么在不分组之前 SQL 为:
SELECT `姓名`,
CASE `课程` WHEN '语文' THEN `分数` ELSE 0 END '语文',
CASE `课程` WHEN '数学' THEN `分数` ELSE 0 END '数学',
CASE `课程` WHEN '物理' THEN `分数` ELSE 0 END '物理'
FROM TB;
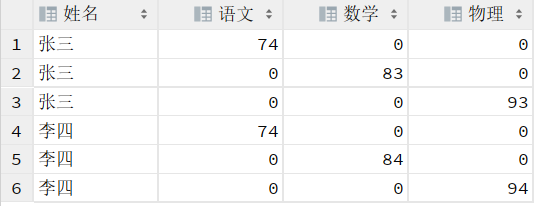
然后 group by 姓名;
执行 group by 姓名 时因为没有任何聚合函数, 那么会从基表里取group by后字段的第一条数据。即:
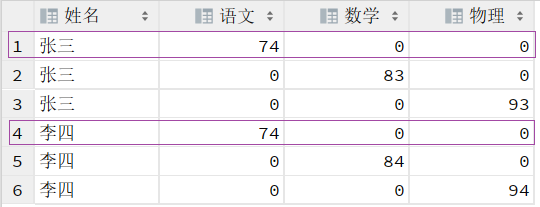
也就是第一条 SQL 执行的结果:
第二个 SQL。
分解下 SQL,执行MAX内CASE WHEN 及未GROUP BY 姓名时SQL:
SELECT `姓名`,
CASE `课程` WHEN '语文' THEN `分数` ELSE 0 END '语文',
CASE `课程` WHEN '数学' THEN `分数` ELSE 0 END '数学',
CASE `课程` WHEN '物理' THEN `分数` ELSE 0 END '物理'
FROM TB;
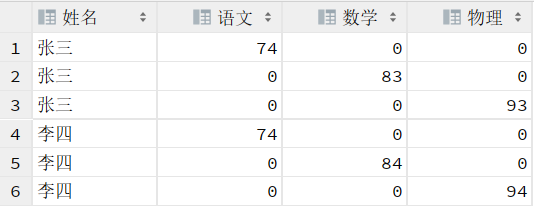
这个结果其实和第一个 SQL一样。
完整的第二个 SQL:
SELECT `姓名`,
MAX(CASE `课程` WHEN '语文' THEN `分数` ELSE 0 END) '语文',
MAX(CASE `课程` WHEN '数学' THEN `分数` ELSE 0 END) '数学',
MAX(CASE `课程` WHEN '物理' THEN `分数` ELSE 0 END) '物理'
FROM TB
GROUP BY `姓名`;
第二个 SQL 对分数进行了MAX函数操作同时又对姓名进行了分组。()
那么这个基表max()中因为case when 课程 取最大分数,再对姓名进行分组。
自然是取了每个姓名下每个学科的最高成绩。即:

自己的理解:
和 sql 语句的执行顺序有关,先执行 group by 将数据按姓名进行分组,之后对每个分组内的数据执行聚合函数 max
参考