“结巴”中文分词:做最好的 Python 中文分词组件,分词模块jieba,它是 python 比较好用的分词模块, 支持中文简体,繁体分词,还支持自定义词库。
jieba 分词的原理
Jieba分词依靠中文词库
- 利用一个中文词库,确定汉字之间的关联概率
-
汉字间概率大的组成词组,形成分词结果
- 除了分词,用户还可以添加自定义的词组
jieba 库使用说明
(1)、jieba 分词的三种模式
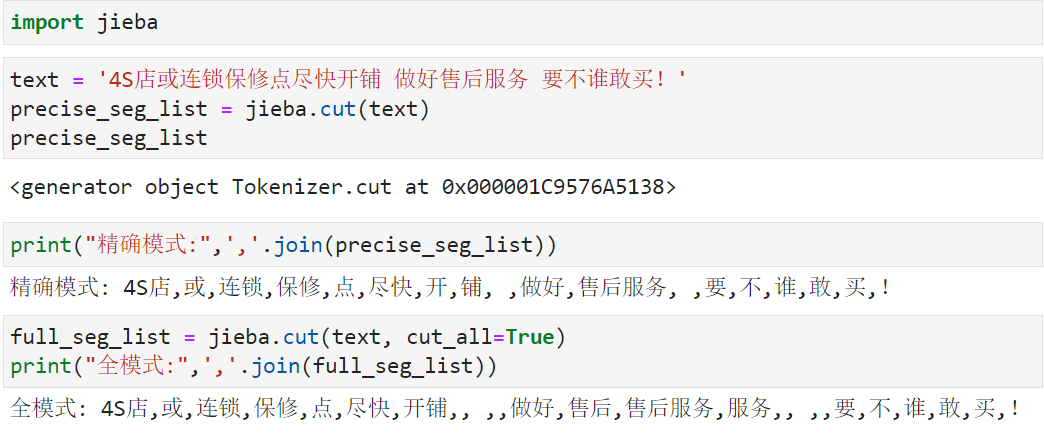
精确模式、全模式、搜索引擎模式
- 精确模式:把文本精确的切分开,不存在冗余单词
-
全模式:把文本中所有可能的词语都扫描出来,有冗余
- 搜索引擎模式:在精确模式基础上,对长词再次切分
(2)、jieba库常用函数
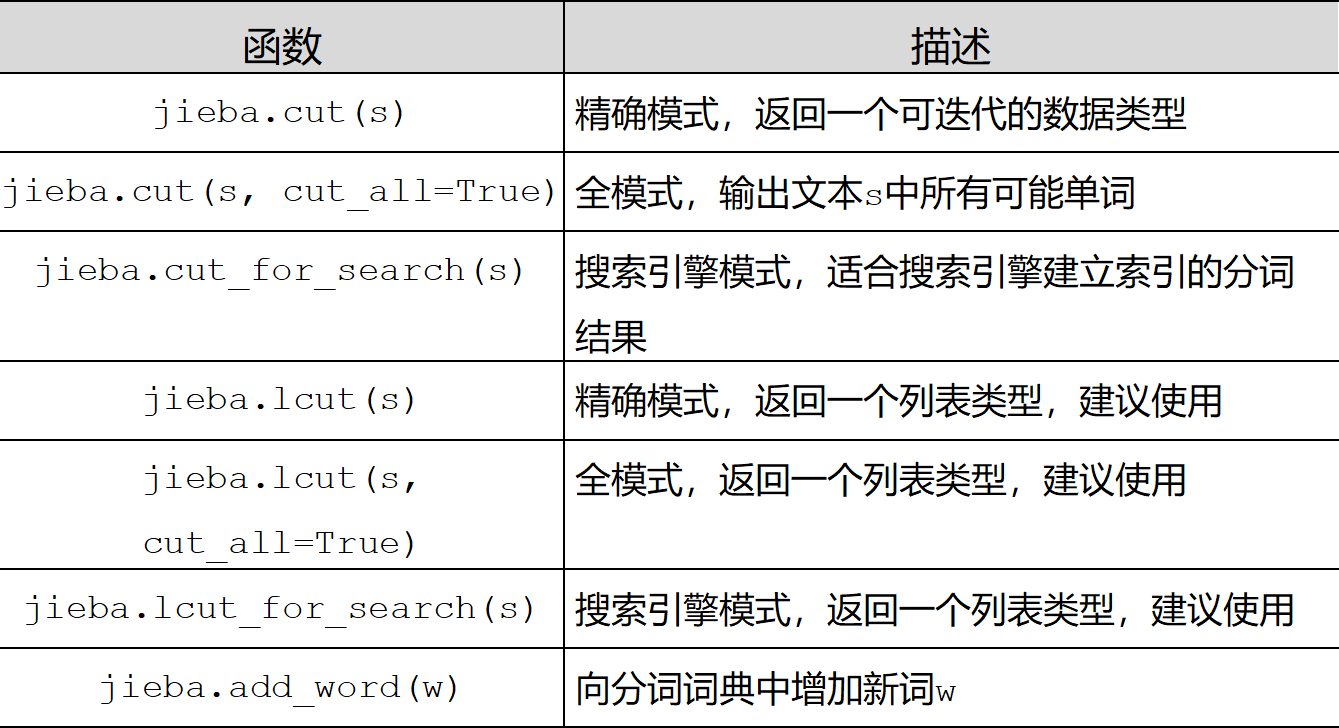
jieba.cut()
返回的是一个迭代器。参数cut_all是bool类型,默认为False,即精确模式,当为True时,则为全模式
jieba.lcut()
返回的是列表。

jieba.cut_for_search()
是搜索引擎模式

添加自定义词典
使用默认字典时,一些新的词汇无法正确分词
#添加自定义词典
text1 = '无妻徒刑,厉害炸了,卷积神经网络'
seg_list1 = jieba.cut(text1, cut_all=False)
print("/ ".join(seg_list1))
# 无妻/ 徒刑/ ,/ 厉害/ 炸/ 了/ ,/ 卷积/ 神经网络
将这三个新词加入字典后
jieba.load_userdict('myDict.txt') # file_name为自定义词典的路径
seg_list1 = jieba.cut(text1, cut_all=False)
print("/ ".join(seg_list1))
# 无妻徒刑/ ,/ 厉害炸了/ ,/ 卷积神经网络
在jieba中添加中文词语
这种方法也可以防止部分词被错分
jieba.add_word('路明非')
也可以添加自定义的字典文本文件
- 开发者可以指定自己自定义的词典,以便包含 jieba 词库里没有的词。虽然 jieba 有新词识别能力,但是自行添加新词可以保证更高的正确率
- 用法: jieba.load_userdict(file_name) # file_name 为文件类对象或自定义词典的路径
- 词典格式和
dict.txt一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。file_name若为路径或二进制方式打开的文件,则文件必须为 UTF-8 编码。 - 词频省略时使用自动计算的能保证分出该词的词频。
例如:userdict.txt
云计算 5
李小福 2 nr
创新办 3 i
easy_install 3 eng
好用 300
韩玉赏鉴 3 nz
八一双鹿 3 nz
台中
凱特琳 nz
Edu Trust认证 2000
import jieba
jieba.load_userdict("userdict.txt")
jieba.add_word('石墨烯')
jieba.add_word('凱特琳')
jieba.del_word('自定义词')
test_sent = (
"李小福是创新办主任也是云计算方面的专家; 什么是八一双鹿\n"
"例如我输入一个带“韩玉赏鉴”的标题,在自定义词库中也增加了此词为N类\n"
"「台中」正確應該不會被切開。mac上可分出「石墨烯」;此時又可以分出來凱特琳了。"
)
words = jieba.cut(test_sent)
print('/'.join(words))
利用jieba库统计三国演义中人物的出场次数
import jieba
txt = open("D:\\三国演义.txt", "r", encoding='utf-8').read()
words = jieba.lcut(txt) # 使用精确模式对文本进行分词
counts = {} # 通过键值对的形式存储词语及其出现的次数
for word in words:
if len(word) == 1: # 单个词语不计算在内
continue
else:
counts[word] = counts.get(word, 0) + 1 # 遍历所有词语,每出现一次其对应的值加 1
items = list(counts.items())#将键值对转换成列表
items.sort(key=lambda x: x[1], reverse=True) # 根据词语出现的次数进行从大到小排序
for i in range(15):
word, count = items[i]
print("{0:<5}{1:>5}".format(word, count))