利用 Pandas 进行数据分析时,确保使用正确的数据类型是非常重要的,否则可能会导致一些不可预知的错误发生。笔者使用Pandas已经有一段时间了,但是还是会在一些小问题上犯错误,追根溯源发现在对数据进行操作时某些特征列并不是Pandas所能处理的类型。因此本文将讨论一些小技巧如何将Python的基本数据类型转化为Pandas所能处理的数据类型。
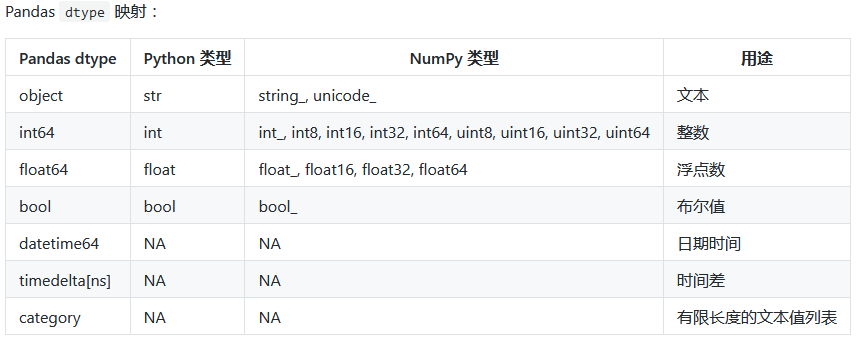
pandas与numpy之间的数据对应关系
引入实际数据进行分析
import numpy as np
import pandas as pd
data = pd.read_csv('data.csv', encoding='gbk') #因为数据中含有中文数据
data
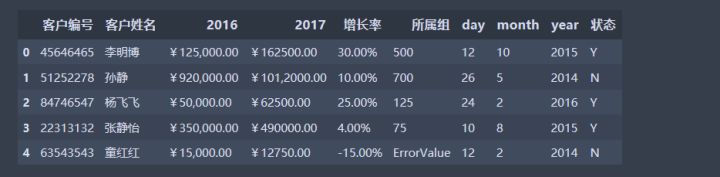
数据加载完毕,如果现在想要在该数据上进行一些操作,比如把数据列2016、2017对应项相加。
data['2016'] + data['2017'] #想当然的做法

从结果来看并没有像想象中那样数值对应相加,这是因为在Pandas中object类型相加等价于Python中的字符串相加。
data.info() #在对数据进行处理之前应该先查看加载数据的相关信息

在看到加载数据的相关信息后可以发现如下几个问题:
- 客户编号的数据类型是int64而不是object类型
- 2016、2017列的数据类型是object而不是数值类型(int64、float64)
- 增长率、所属组的数据类型应该为数值类型而不是object类型
- year、month、day的数据类型应该为datetime64类型而不是object类型
Pandas中进行数据类型转换有三种基本方法:
- 使用astype()函数进行强制类型转换
- 自定义函数进行数据类型转换
- 使用Pandas提供的函数如to_numeric()、to_datetime()
使用astype()函数进行类型转换
对数据列进行数据类型转换最简单的方法就是使用astype()函数
data['客户编号'].astype('object')
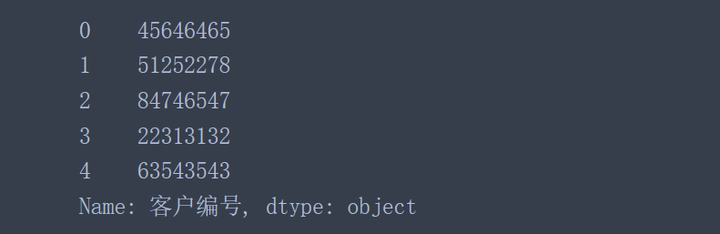
data['客户编号'] = data['客户编号'].astype('object') #对原始数据进行转换并覆盖原始数据列
上面的结果看起来很不错,接下来给出几个astype()函数作用于列数据但失效的例子
data['2017'].astype('float')
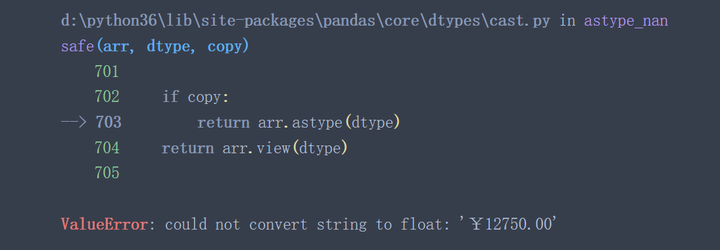
data['所属组'].astype('int')
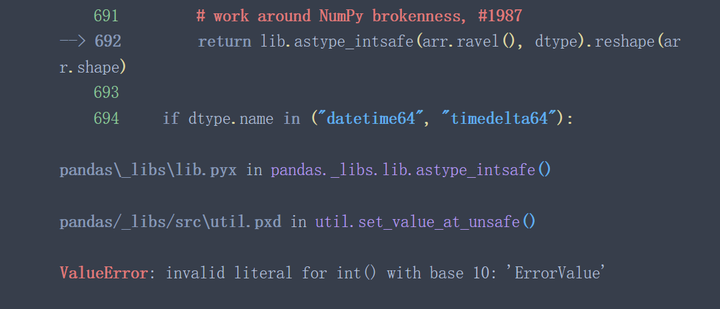
从上面两个例子可以看出,当待转换列中含有不能转换的特殊值时(例子中¥,ErrorValue等) astype()函数将失效。有些时候 astype()函数执行成功了也并不一定代表着执行结果符合预期。
data['状态'].astype('bool')
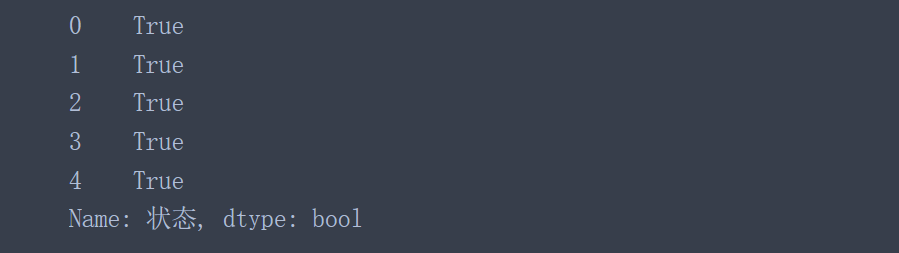
乍一看,结果看起来不错,但仔细观察后,会发现一个大问题。那就是所有的值都被替换为True了,但是该列中包含好几个N标志,所以astype()函数在该列也是失效的。
总结一下astype()函数有效的情形:
- 数据列中的每一个单位都能简单的解释为数字(2, 2.12等)
- 数据列中的每一个单位都是数值类型且向字符串object类型转换
如果数据中含有缺失值、特殊字符astype()函数可能失效。
使用自定义函数进行数据类型转换
该方法特别适用于待转换数据列的数据较为复杂的情形,可以通过构建一个函数应用于数据列的每一个数据,并将其转换为适合的数据类型。
对于上述数据中的货币,需要将它转换为float类型,因此可以写一个转换函数:
def convert_currency(value):
"""
转换字符串数字为float类型
- 移除 ¥ ,
- 转化为float类型
"""
new_value = value.replace(',', '').replace('¥', '')
return np.float(new_value)
现在可以使用Pandas的apply函数通过covert_currency函数应用于2016列中的所有数据中。
data['2016'].apply(convert_currency)
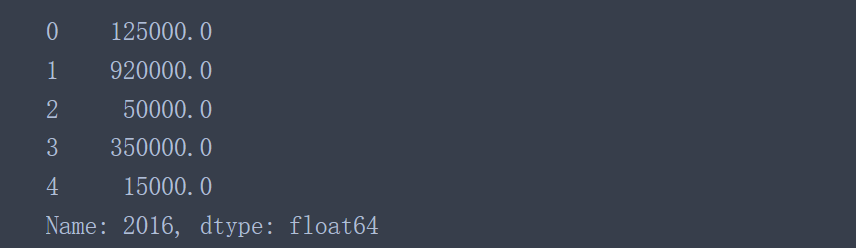
该列所有的数据都转换成对应的数值类型了,因此可以对该列数据进行常见的数学操作了。
如果利用lambda表达式改写一下代码
data['2016'].apply(lambda x: x.replace('¥', '').replace(',', '')).astype('float')
同样的方法运用于增长率,首先构建自定义函数
def convert_percent(value):
"""
转换字符串百分数为float类型小数
- 移除 %
- 除以100转换为小数
"""
new_value = value.replace('%', '')
return float(new_value) / 100
使用Pandas的apply函数通过covert_percent函数应用于增长率列中的所有数据中。
data['增长率'].apply(convert_percent)
使用lambda表达式:
data['增长率'].apply(lambda x: x.replace('%', '')).astype('float') / 100
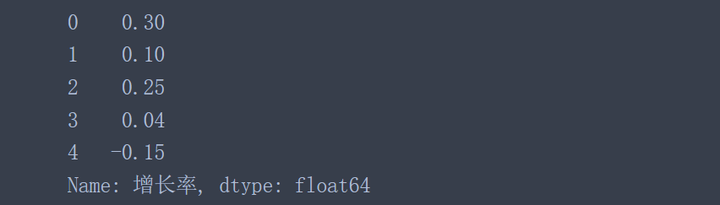
为了转换状态列,可以使用Numpy中的where函数,把值为Y的映射成True,其他值全部映射成False。
data['状态'] = np.where(data['状态'] == 'Y', True, False)
同样的你也可以使用自定义函数或者使用lambda表达式
利用Pandas的一些辅助函数进行类型转换
Pandas的astype()函数和复杂的自定函数之间有一个中间段,那就是Pandas的一些辅助函数。这些辅助函数对于某些特定数据类型的转换非常有用(如to_numeric()、to_datetime())
所属组数据列中包含一个非数值,用astype()转换出现了错误,然而用to_numeric()函数处理就优雅很多。
pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
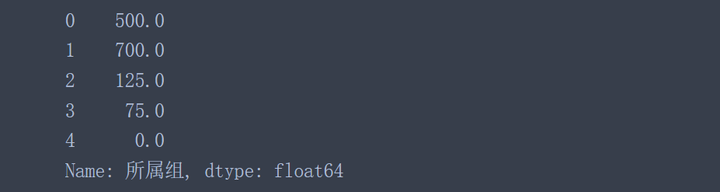
可以看到,非数值被替换成0.0了,当然这个填充值是可以选择的,具体文档见
使用to_numeric转为数值。默认情况下,它不能处理字母型的字符串’pandas’:
也可以结合 lambda 函数
df[['col2','col3']] = df[['col2','col3']].apply(pd.to_numeric)
Pandas中的to_datetime()函数可以把单独的year、month、day三列合并成一个单独的时间戳。
pd.to_datetime(data[['day', 'month', 'year']])
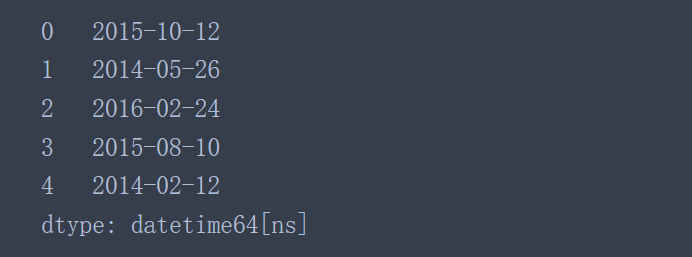
完成数据列的替换
data['new_date'] = pd.to_datetime(data[['day', 'month', 'year']]) #新产生的一列数据
data['所属组'] = pd.to_numeric(data['所属组'], errors='coerce').fillna(0)
在读取数据时就对数据类型进行转换,一步到位
data2 = pd.read_csv("data.csv",
converters={
'客户编号': str,
'2016': convert_currency,
'2017': convert_currency,
'增长率': convert_percent,
'所属组': lambda x: pd.to_numeric(x, errors='coerce'),
'状态': lambda x: np.where(x == "Y", True, False)
},
encoding='gbk')
或者
df = pd.read_csv("somefile.csv", dtype = {'column_name' : str})