python 正则表达式基础语法
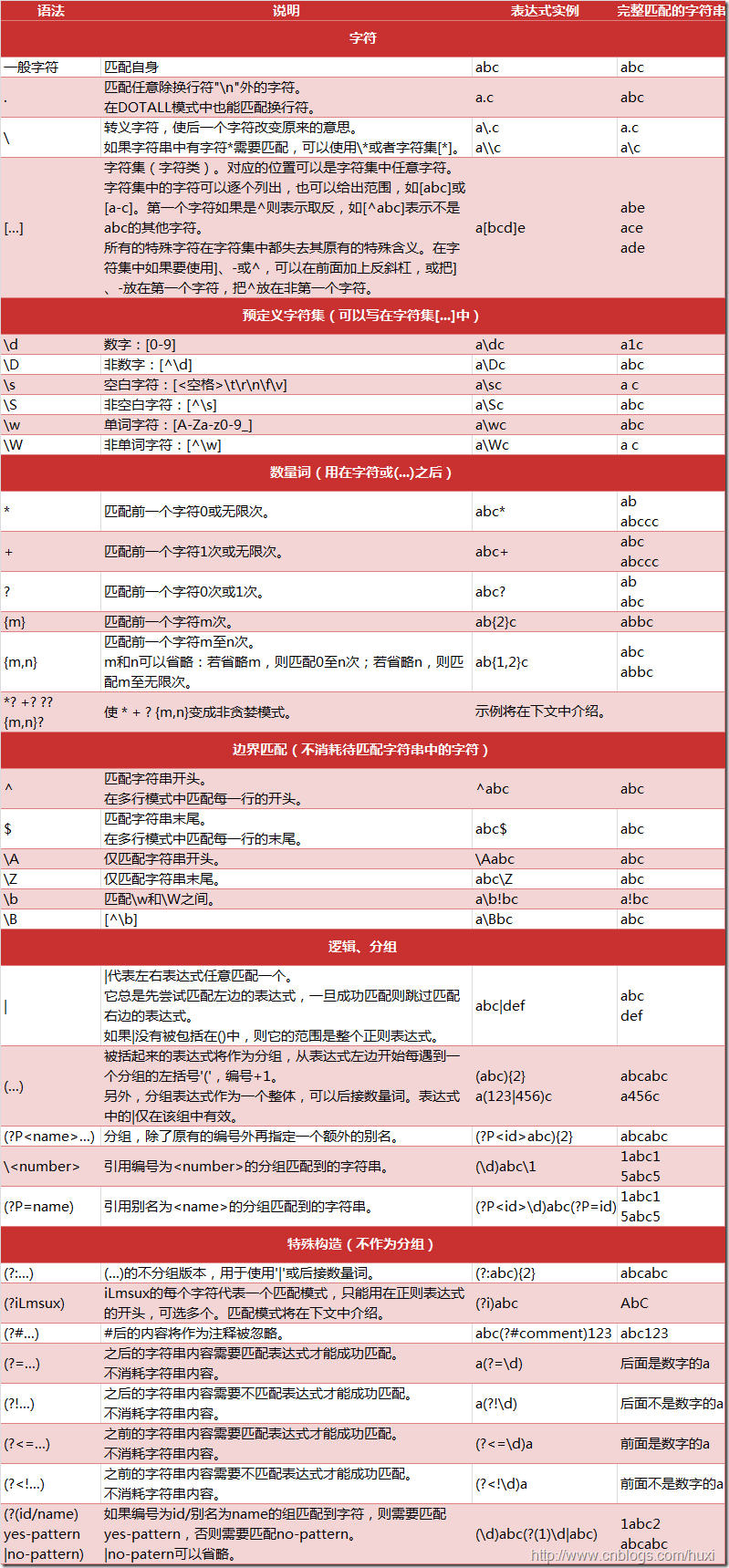
literal
功能:匹配文本字符串的字面值 literal
例子:foo
re1|re2
功能:匹配正则表达式 re1 或者 re2 例子:foo|bar
.
功能:匹配任何字符(除了\n 之外)
表达式:f.o
匹配:在字母“f”和“o”之间的任意一个字符;例如 fao、f9o、f#o 等
表达式:..
匹配:任意两个字符
^
功能:匹配字符串起始部分
表达式:^From
匹配:任何以 From 作为起始的字符串
$
功能:匹配字符串终止部分
表达式:/bin/*sh$
匹配:任何以/bin/tcsh 作为结尾的字符串
*
功能:匹配 0 次或者多次前面出现的正则表达式 例子:
表达式:5*
匹配:5 或 555 或 没有5
+
功能:匹配 1 次或者多次前面出现的正则表达式
表达式:[a-z]+\.com
匹配:a.com 或 abc.com
不匹配:.com
?
功能:匹配 0 次或者 1 次前面出现的正则表达式
表达式:goo?
匹配:goo 或 gooo
不匹配:goooo
{N}
功能:匹配 N 次前面出现的正则表达式
表达式:[0-9]{3}
匹配:123 或 999
不匹配:1234 或 12
{M,N}
功能:匹配 M~N 次前面出现的正则表达式
表达式:[0-9]{1,3}
匹配:1 或 12 或 123
不匹配:1234
[…]
功能:匹配来自字符集的任意单一字符
表达式:[aeiou]
匹配:a 或 e 或 i 或 o 或 u
不匹配:f 或 s 等
[…x−y…]
功能:匹配 x~y 范围中的任意单一字符
表达式:[0-9]
匹配:1 或 5 或 8 (0到9之间的单个数字)
不匹配:a
表达式:[A-Za-z]
匹配:A, F, h
不匹配:5
[^…]
功能:不匹配此字符集中出现的任何一个字符,包括某一范围的字符(如果在此字符集中出现)
表达式:[^aeiou]good
匹配:sgood
不匹配:agood 或 egood
(*|+|?|{})?
功能:用于匹配上面频繁出现/重复出现符号的非贪婪版本(*、+、?、{}) 解释:
贪婪模式:就是在整个表达式匹配成功的前提下,尽可能多的匹配,也就是所谓的“贪婪”,通俗点讲,就是看到想要的,有多少就捡多少,除非再也没有想要的了。 非贪婪模式:就是在整个表达式匹配成功的前提下,尽可能少的匹配,也就是所谓的“非贪婪”,通俗点讲,就是找到一个想要的捡起来就行了,至于还有没有没捡的就不管了。(带问号的)
字符串:'Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::1171590364-6-8'
表达式:.+(\d+-\d+-\d+)
结果:
Match 1
Full match 0-61 `Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::1171590364-6-8`
Group 1. 56-61 `4-6-8`
(Group1 匹配到的是`4-6-8`)
表达式:.+?(\d+-\d+-\d+) # 注意,在加号后面,加了"?"
结果:
Match 1
Full match 0-61 `Thu Feb 15 17:46:04 2007::uzifzf@dpyivihw.gov::1171590364-6-8`
Group 1. 47-61 `1171590364-6-8`
(Group1 匹配到的是`1171590364-6-8`)
字符串:aa<div>test1</div>bb<div>test2</div>cc
表达式:<div>.*</div>
结果:<div>test1</div>bb<div>test2</div>
表达式:<div>.*?</div>
结果:<div>test1</div>(这里指的是一次匹配结果,所以没包括<div>test2</div>)
例子
比如有一段html片段,<a>this is first label</a><a>the second label</a>,如何匹配出每个a标签中的内容,下面来看下最短与最长的区别。
>>> import re
>>> str = '<a>this is first label</a><a>the second label</a>'
>>> print re.findall(r'<a>(.*?)</a>', str) # 最短匹配
['this is first label', 'the second label']
>>> print re.findall(r'<a>(.*)</a>', str)
['this is first label</a><a>the second label']
例子中,模式r'(.\*?)' 的意图是匹配被和包含的文本,但是正则表达式中 * 操作符是贪婪的,因此匹配操作会查找出最长的可能。
但是在 *操作符后面加上 \?操作符,这样使得匹配变成非贪婪模式,从而得到最短匹配。
(…)
功能:匹配封闭的正则表达式,然后另存为子组 例子:([0-9]{3})?,f(oo|u)bar
\d
功能:匹配任何十进制数字,与[0-9]一致(\D 与\d 相反,不匹配任何非数值型的数字) 例子:data\d+.txt
\w
功能:匹配任何字母数字字符,与[A-Za-z0-9]相同(\W 与之相反) 例子:[A-Za-z]\w+
\s
功能:匹配任何空格字符,与[\n\t\r\v\f]相同(\S 与之相反) 例子:of\sthe
\b
功能:匹配任何单词边界(\B 与之相反)
表达式:\bThe\b
意思:仅仅匹配单词 the。
匹配:"a the b"
不区别:"fathe"
表达式:\Bthe
意思:任何包含但并不以 the 作为起始的字符串。
匹配:"fathe"
不区别:"a the b"
\N
功能:匹配已保存的子组 N(参见上面的(…)) 例子:price: \16
\c
功能:转义表达式用字符 例子: 表达式:data.txt 匹配:data.txt
\A(\Z)
功能:匹配字符串的起始(结束)(另见上面介绍的^和$) 例子:\ADear
(?#comment)
功能:此处并不做匹配,只是作为注释 (没看到哪里用过)
(?=)
解释 如果表达式为“(?=.com)”,意思是:一个字符串后面跟着“.com”才做匹配操作,并不使用任何目标字符串
(?!)
解释 如果表达式为“(?!.net)”,意思是:一个字符串后面不是跟着“.net”才做匹配操作
(?<=)
解释 如果表达式为“(?<=800-)”,意思是:字符串之前为“800-”才做匹配,假定为电话号码,同样,并不使用任何输入字符串
(?<!)
解释 如果表达式为“(?<!192.168.)”,意思是:一个字符串之前不是“192.168.”才做匹配操作,假定用于过滤掉一组 C 类 IP 地址
(?:)
功能 表示一个匹配不用保存的分组。
解释 当表达式中有圆括号“()”出现时,表示把匹配“()”内规则的字符串,保存成一个分组。保存成分组后,就可以使用 result.group(1) 来访问这个分组。当有多个分组时,就可以使用 result.group(N) 来访问第N个分组。 在分组内加“?:”的话(例如:(?:a) ),就表示匹配到“a”后,不把“a”保存到分组中。也就是说 result.group(1) 就取不到这个“a”了。
表达式:(?:https?|ftp)://([^/\r\n]+)(/[^\r\n]*)?
结果1:
Match "https://stackoverflow.com/"
Group 1: "stackoverflow.com"
Group 2: "/"
结果2:
Match "https://stackoverflow.com/questions/tagged/regex"
Group 1: "stackoverflow.com"
Group 2: "/questions/tagged/regex"
(?(id/name)Y|N )
功能: 如果分组所提供的 id 或者 name(名称)存在,就返回正则表达式的条件匹配 Y,如 果不存在,就返回 N;|N 是可选项。
解释 当有一个分组被保存后,就可以通过 result.group(1) 取得这个分组的值。在表达式中,可以“(1)”的方式,取出被保存的分组。“?(1)”表示,如果能取到“分组1”,就使用“Y”规则,否则就使用“X”规则。(当然,也可以使用“?(name)”的方式)
表达式:(?:x)y
结果1:
Match "xy"
Full match 0-2 `xy`
(没有group(1),也就是说“x”没有被保存到分组内)
.* 或.+
功能:".*" 是匹配所有字符,可以一个字符没有;".+" 是区别所有字符,必须有一个字符。
表达式:.*a
匹配:a 或 1a
不匹配:b
表达式:.+a
匹配:1a 或 aaaaa
不匹配:a
验证URL
text = "https://baike.baidu.com/item/Python/407313?fr=aladdin"
ret = re.match('(http|https|ftp)://[^\s]+',text) #[^\s]匹配非空白字符
print(ret.group())