线性关系展示
许多数据集含有多个定量变量(数值型变量),而我们分析的目的往往是将他们关联起来。我们曾讨论过通过两个变量的联合分布来实现这一点。然而,使用统计模型来为两组带有噪声数据的观测值评估出一个简单的关系可以是非常有用的。这一章节我们讨论的函数将会在线性回归的框架下实现这种预测。
seaborn中的回归图主要是为了在EDA(探索数据分析)阶段为发掘数据中存在的规律提供一些视觉指引,也就是说,seaborn本身并非是一个用于统计分析的库。想要得到关于回归模型拟合效果的一些量化指标,你需要使用statsmodels库。seaborn的终极目标就是让我们通过可视化快速、轻易地探索数据,毕竟对于探索数据来说,可视化的重要性不比得到一个统计表格低。
绘制线性回归模型
seaborn主要通过两个函数来展示通过回归得到的线性关系,regplot()和lmplot()。它们紧密相关,而且共享大多数的核心功能。但是弄清楚他们的区别非常重要,这样我们就可以在针对特定工作时快速判断哪个工具更适合。
在最基本的调用过程中,他们都会画出关于x、y两个变量的散点图,同时用数据拟合一个y ~ x的模型出来,并将对应的直线和95%的置信区间绘制出来:
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(color_codes=True)
tips = pd.read_csv("tips.csv")
sns.regplot(x="total_bill", y="tip", data=tips)
plt.savefig('r1.png')

sns.lmplot(x="total_bill", y="tip", data=tips)
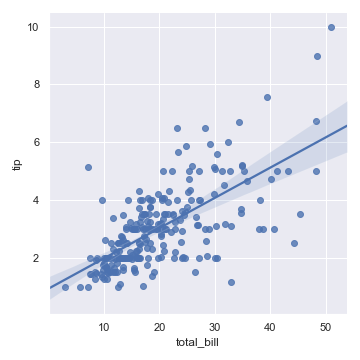
注意到除了图片的形状略有差异,其他地方都是一致的。需要知道的是,他们之间最主要的区别在于regplot()中的x, y参数接受多种数据类型,包括numpy数组、pandas序列(Series),或者将pandas DataFrame传递给data参数。作为对比,lmplot()的data参数是不能为空的,同时x和y参数必须以字符串形式指定。这种数据格式(这里是指regplot()支持而lmplot()不支持的类似一维数组的数据格式)被称为“long-form data”或“tidy data”。除了这一输入格式的灵活性以外,regplot()仅提供了lmplot()特性的一部分
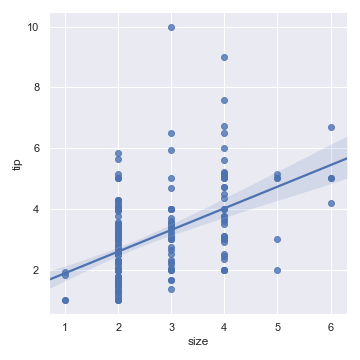
seaborn支持其中一个变量属于离散变量的情况,不过这种数据集产生的散点图效果往往一般:
sns.lmplot(x="size", y="tip", data=tips)
增加一些随机的偏移量会让这些分布看起来更清晰,需要注意的是这些偏移量仅仅会影响散点图的效果,不会对拟合的回归线产生干扰:
sns.lmplot(x="size", y="tip", data=tips, x_jitter=.05)

另一个选择是将每个离散桶内的观测值隐藏起来,用代表集中趋势的统计量以及置信区间作为替代
sns.lmplot(x="size", y="tip", data=tips, x_estimator=np.mean);
拟合不同的模型
简单线性回归的模型非常容易拟合,然而它并不适用于所有数据集。Anscombe's quartet数据集展示了一些例子,在这些例子中简单线性回归提供了变量间关系一致的估计,但是却与我们视觉上的直观判断存在一些差异。比如,在第一个例子中,线性回归是一个很不错的模型:
anscombe = pd.read_csv("anscombe.csv")
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),
ci=None, scatter_kws={"s": 80})
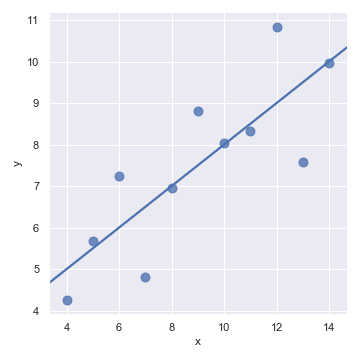
第二个数据集中有着同样的线性关系,但是我们瞬间就能判断线性回归并不是一个最佳的模型:
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
ci=None, scatter_kws={"s": 80})
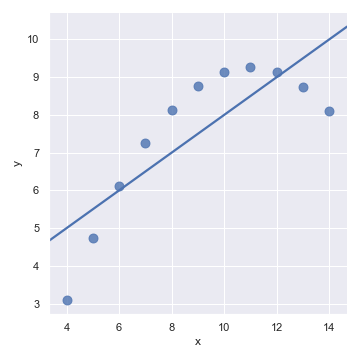
在展示这种更高阶的关系时,lmplot()和regplot()可以通过拟合多项式回归模型来应对数据集中的一些简单的非线性趋势:
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
order=2, ci=None, scatter_kws={"s": 80})

另一个问题是由异常观测点导致的,这些观测点明显偏离了我们想要得到的主要趋势关系
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
ci=None, scatter_kws={"s": 80})

在异常观测值存在时,我们可以拟合一个鲁棒回归(稳定回归),它使用了不同的损失函数,对较大的残差做了降权:
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
robust=True, ci=None, scatter_kws={"s": 80})
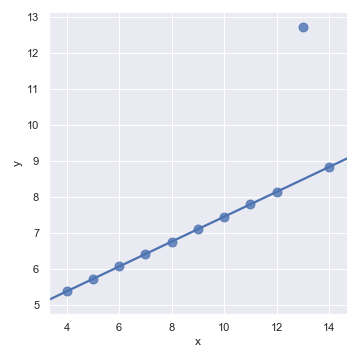
residplot()函数可以检查一个简单的回归模型对于某个数据集是否合适。它先拟合一个简单线性回归模型并移除它,然后将每个观测点与预测值的残差画出来。理想情况下,这些残差应该随机地分布在x轴上下方
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),
scatter_kws={"s": 80})
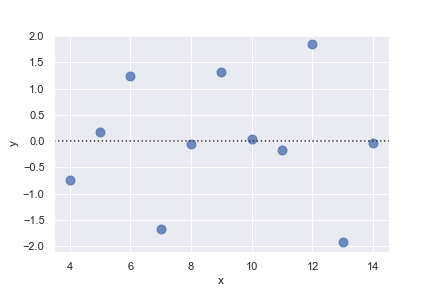
如果残差的分布具有某种规律,那说明简单线性回归或许并不是一个好的选择:
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
scatter_kws={"s": 80})
relplot()
它用散点图和线图两种常用的手段来表现统计关系。
relplot() 使用两个坐标轴级别的函数来结合了FacetGrid:
scatterplot():(使用kind="scatter",这是默认参数)lineplot():(使用`kind=“line”)
我们用的最多的是relplot()。这是一个图形级别的函数,它用散点图和线图两种常用的手段来表现统计关系。
relplot()使用两个坐标轴级别的函数来结合了FacetGrid:
scatterplot():(使用kind="scatter",这是默认参数)lineplot():(使用`kind="line")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="darkgrid")
用散点图展示相关变量
散点图是统计图形中的中流砥柱。它用一系列的散点将两个变量的联合分布描绘出来,其中每个点就是一个观测样本。这种描述方式可以让我们从视觉上推断出大量信息,来判断两个变量之间是否存在某种有意义的关系。
在seaborn中,我们有数种方法可以实现散点图的绘制。最基本的一种适用于两个变量都是数值型变量的情况,它就是scatterplot()。在分类可视化教程中,我们会看到如何绘制分类数据的散点图。
relplot()的默认类型(kind)就是scatterplot()(当然,我们也可以强制指定参数kind="scatter",这和不指定这一参数时效果是一样的)。
tips = sns.load_dataset("tips")
sns.relplot(x="total_bill", y="tip", data=tips)
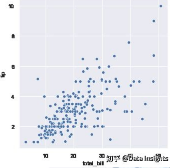
参数hue
当我们已经将散点绘制在二维的平面上时,我们还可以根据第三个变量来对这些点施以不同的颜色,从而引入一个新的维度。在seaborn中,我们用hue参数实现了这种想法,因为点的颜色是有意义的。

sns.relplot(x="total_bill", y="tip", hue="smoker", style="smoker", data=tips)

参数:style
我们也可以同时展示四个变量,只需要将hue和style参数单独调整到不同的分类变量即可。但是我们要谨慎使用这种方法,因为我们的眼睛对于形状的敏感性远远不如对颜色的敏感性。
sns.relplot(x="total_bill", y="tip", hue="smoker", style="time", data=tips)
 在上边这个例子中,
在上边这个例子中,hue参数对应的变量是分类型数据,因此seaborn自动为它应用了默认的定性(分类)调色板。如果hue参数对应的变量是数值型的(可转化为浮点数的),那么默认的颜色也会随之变为连续的定量调色板。
上述两种情况下(分类或连续数据),我们都可以自定义我们的调色板。有很多选项可以实现这一目的。下面,我们使用cubehelix_palette()的字符串接口来定制我们的连续调色板:
sns.relplot(x="total_bill", y="tip", hue="size",
palette="ch:r=-.5,l=.75", data=tips)

参数size
我们还可以使用点的大小来引入第三个额外的变量:
sns.relplot(x="total_bill", y="tip", size="size", data=tips);

参数sizes
与matplotlib.pyplot.scatter()不同的是,这里并不是使用原始数据中的数值来为每个点选择面积大小,seaborn将原始数据归一化(正则化)到了某个范围,这个范围可以由我们来指定:
sns.relplot(x="total_bill", y="tip", size="size", sizes=(15, 200), data=tips)

二、使用线图表现连续性
在某些数据集中,我们可能想要理解某个变量随着时间的变化规律,或者想要理解某个连续型的变量。这种情况下,线图会是一个不错的选择。在seaborn中,我们可以通过lineplot()函数或者使用带有kind="line"参数的relplot()来实现线图的绘制。
df = pd.DataFrame(dict(time=np.arange(500), value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()

参数:sort
由于lineplot()假设用户在大多数情况下是在尝试描绘y相对于x的函数(变化规律),因此它在绘制之前会默认先对x做一个排序。不过我们可以禁止它。

参数:ci
在更多复杂的数据集中,会出现一个x轴变量对应了多个观测值(y)的情况。seaborn会默认将多个观测值聚合起来,并且将它们的均值以及95%的置信区间展示出来: ```python fmri = sns.load_dataset("fmri") sns.relplot(x="timepoint", y="signal", kind="line", data=fmri) ```  置信区间是通过`自助采样法(bootstrapping)`计算的,这在遇到大型数据集时可以帮助我们节省时间。当然,我们也可以禁止它。 另一个不错的选择是,我们可以用标准差替代置信区间来展示每个时间点下观测值的分布,当数据集比较大时这一选择尤其明智。 ```python sns.relplot(x="timepoint", y="signal", kind="line", ci="sd", data=fmri) ```  #### 参数:`ciestimator`如果想要关闭所有的聚合操作,我们可以设置estimator=None。不过当同一时间点存在多个观测值时,我们的图会看起来有些奇怪。
sns.relplot(x="timepoint", y="signal",
estimator=None,
kind="line",
data=fmri
)

通过参数映射可视化数据子集
lineplot()与scatterplot()一样具有很强的灵活性:它也可以通过hue、size和style参数来展示额外的三个变量。它和scatterplot()使用了相同的API,因此我们不需要停下来绞尽脑汁地思考哪些参数是用来控制线条、哪些参数是用来控制散点。
使用不同的参数会决定我们的数据如何聚合。比如,增加一个具有两个水平的分类变量作为hue参数,会将我们的图形分为两条线以及两个误差带,并分别施以不同的颜色来区分数据的分类归属。
sns.relplot(x="timepoint", y="signal", hue="event",
kind="line", data=fmri)

我们可以增加一个·style参数,以不同的线条样式来展示不同的分类:
sns.relplot(x="timepoint", y="signal", hue="region",
style="event", kind="line", data=fmri)

sns.relplot(x="timepoint", y="signal", hue="region",
style="event",
dashes=False, ##
markers=True,
kind="line",
data=fmri)
 跟散点图一样,我们要慎重使用这些参数来展示太多变量。有些时候它们会展示丰富的信息,但是有些时候它们会使图形太过复杂导致我们难以解析和解释它。然而当你仅打算考虑额外的一个变量时,同时修改它们的颜色和样式会很有帮助。
跟散点图一样,我们要慎重使用这些参数来展示太多变量。有些时候它们会展示丰富的信息,但是有些时候它们会使图形太过复杂导致我们难以解析和解释它。然而当你仅打算考虑额外的一个变量时,同时修改它们的颜色和样式会很有帮助。
sns.relplot(x="timepoint", y="signal",
hue="event",
style="event",
kind="line", data=fmri);
当我们需要应对重复测量的数据时,我们可以将不同的抽样单元(单次实验观测到的数据系列)分离开来展示,这并不需要我们使用一个语义参数(hue/style/size)。后者会导致图例看起来像一个灾难(想象一下几十个分类的情况):
sns.relplot(x="timepoint", y="signal", hue="region",
units="subject", estimator=None, kind="line",
data=fmri.query("event == 'stim'"));
 与
与scatterplot()类似,lineplot()默认的调色板以及图例处理方式也取决于hue对应的数据是分类型还是连续数值型。
ots = sns.load_dataset("dots").query("align == 'dots'")
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
kind="line", data=dots);
 当hue参数对应的变量的数据是均匀分布在对数刻度上的(即数据分布范围非常大,比如从1到1亿),即使是连续的调色板也无法很好地应对这种情况。但是我们可以
当hue参数对应的变量的数据是均匀分布在对数刻度上的(即数据分布范围非常大,比如从1到1亿),即使是连续的调色板也无法很好地应对这种情况。但是我们可以使用列表或者字典对每条线指定一个颜色。
palette = sns.cubehelix_palette(light=.8, n_colors=6)
sns.relplot(x="time", y="firing_rate",
hue="coherence", style="choice",
palette=palette,
kind="line", data=dots);

sns.relplot(x="time", y="firing_rate", size="coherence",
style="choice", kind="line", data=dots);

绘制时间序列数据
线图常用来描绘日期、时间相关的诗句。这些方法以原始格式传入更底层的matplotlib函数中,这样它们就可以利用matplotlib的能力来格式化日期数据。但是所有的时间格式化过程都是在matplotlib层实现的,想要知道更多实现的细节就需要去看一下matplotlib中关于这部分的文档:
df = pd.DataFrame(dict(time=pd.date_range("2017-1-1", periods=500),
value=np.random.randn(500).cumsum()))
g = sns.relplot(x="time", y="value", kind="line", data=df)
g.fig.autofmt_xdate()

三、用更多子图展示多重关系
前边我们已经强调过,虽然我们可以在一张图中展示数个不同的语义变量(通过hue/style/size参数),但是这么做并不是总会高效。那么当我们真的很想理解在某些额外变量的影响下两个变量之间的关系有什么不同时怎么办呢?
最好的办法就是画更多的图。由于relplot()是基于FacetGrid的,因此这很容易做到。当我们想要表现出一个额外变量的影响时,我们可以不用将它赋给前边提到的语义参数(hue/style/size),而是用它来将图形“面板”化。这意味着我们会创建多个坐标轴,分别用来绘制不同的子数据集:
参数:col
sns.relplot(x="total_bill", y="tip",
hue="smoker",
col="time",
data=tips);
我们还可以同时使用col(列)和row(行)参数来展示两个变量的影响。当我们在图中增加了更多的变量时(会有更多的子图),我们可能会想要调整图形的大小。要记住在FacetGrid中,我们用height(子图高度)和aspect(高宽比)来定制每个子图的大小:
sns.relplot(x="timepoint", y="signal",
hue="subject",
col="region",
row="event",
height=3,
kind="line",
estimator=None,
data=fmri)

参数:col_wrap
当我们想要检验某个具有大量水平的变量的影响时,我们可以将这个变量赋给col参数,同时我们通过col_wrap参数设置每行达到多少列就换行:
sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5,
height=3, aspect=.75, linewidth=2.5,
kind="line", data=fmri.query("region == 'frontal'"));
 这种常被叫做“格子图”或“small-multiples”的可视化方式,非常高效,因为它们呈现数据的方式使得我们很容易同时发现整体的模式以及不同模式之间的偏差。当你需要利用scatterplot()和relplot()的灵活性来表现更多信息时,一定要记住,多幅简单的图通常比一幅复杂的图更加高效。
这种常被叫做“格子图”或“small-multiples”的可视化方式,非常高效,因为它们呈现数据的方式使得我们很容易同时发现整体的模式以及不同模式之间的偏差。当你需要利用scatterplot()和relplot()的灵活性来表现更多信息时,一定要记住,多幅简单的图通常比一幅复杂的图更加高效。
散点图 scatterplot
seaborn.scatterplot(x=None, y=None, hue=None,
style=None, size=None, data=None,
palette=None, hue_order=None, hue_norm=None,
sizes=None, size_order=None, size_norm=None,
markers=True, style_order=None, x_bins=None,
y_bins=None, units=None, estimator=None,
ci=95, n_boot=1000, alpha='auto', x_jitter=None,
y_jitter=None, legend='brief', ax=None, **kwargs)
data: DataFrame
可选参数
x,y为数据中变量的名称;
作用:对将生成具有不同颜色的元素的变量进行分组。可以是分类或数字.
size:数据中的名称
作用:根据指定的名称(列名),根据该列中的数据值的大小生成具有不同大小的效果。可以是分类或数字。
style:数据中变量名称(比如:二维数据中的列名)
作用:对将生成具有不同破折号、或其他标记的变量进行分组。
palette:调试板名称,列表或字典类型
作用:设置hue指定的变量的不同级别颜色。
hue_order:列表(list)类型
作用:指定hue变量出现的指定顺序,否则他们是根据数据确定的。
hue_norm:tuple或Normalize对象
sizes:list dict或tuple类型
作用:设置线宽度,当其为数字时,它也可以是一个元组,指定要使用的最大和最小值,会自动在该范围内对其他值进行规范化。