分类数据图
在统计关系可视化教程中,我们学会了使用多种不同的方式来展示一个数据集中多个变量之间的关系。在一系列的例子中,我们聚焦于那些关系主要存在于两个数值型变量之间的情况。然而当其中一个变量是分类(离散)变量时,我们不妨使用更加有针对性的可视化方法。
在 seaborn 中,有多种不同的方式来展示包含了分类数据的变量关系。正如relplot()和scatterplot()/lineplot()之间的关系一样,我们可以使用catplot()函数来描述分类数据,也可以使用更多坐标轴级别的绘图函数来完成这些任务。catplot()提供了对这些axes-level的函数的整合,将他们放在了一个更高级别的统一的接口之中。
分类散点图
stripplot() #或catplot(kind="strip")
swarmplot() #或catplot(kind="swarm")
分类分布图
boxplot() #或 catplot(kind="box")
violinplot() #或 catplot(kind="violin")
boxenplot() #或 catplot(kind="boxen")
分类统计估计图
pointplot() # 或 catplot(kind="point")
barplot() # 或 catplot(kind="bar")
countplot() #或 catplot(kind="count")
这些分类从不同的粒度来展示数据。 catplot()提供的统一的API可以帮助我们轻松地在不同方法间切换并从不同的视角理解数据。
分类散点图 catplot
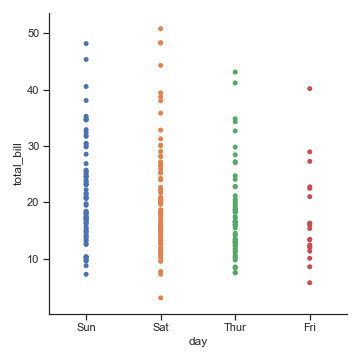
catplot() 默认的处理方式就是散点图。在绘制分类散点图时,我们会遇到一个挑战,当在同一个类别中出现大量取值相同或接近的观测数据时,他们会挤到一起。
seaborn 中有两种分类散点图,分别以不同的方式处理了这个问题。catplot() 使用的默认方式是 stripplot(),它给这些散点增加了一些随机的偏移量:
默认类型 stripplot
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style="ticks", color_codes=True)
tips = sns.load_dataset("tips")
sns.catplot(x="day", y="total_bill", data=tips)

参数 jitter
jitter 参控制着偏移量的大小,或者我们可以直接禁止他们偏移:
sns.catplot(x="day", y="total_bill", jitter=False, data=tips)
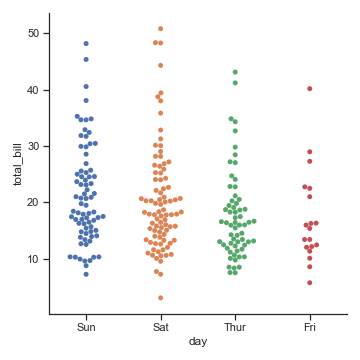
参数:kind="swarm"
第二种解决方式使用算法避免了散点之间的重合。它提供了更好的方式来呈现观测点的分布,但是它仅适用于较小的数据集。这种图被叫做蜂群图,在seaborn 中我们用swarmplot()或者 catplot(kind=“swarm”)来绘制它:
sns.catplot(x="day", y="total_bill", kind="swarm", data=tips)
参数:hue
与关系图(relplot())类似,我们也可以使用hue参数来增加一个新的维度(但是分类图不支持size和style)。不同的分类图对于hue 参数的处理不太一样,对于散点图而言,它仅仅控制散点的颜色就足够了:
sns.catplot(x="day", y="total_bill",
hue="sex",
kind="swarm",
data=tips)

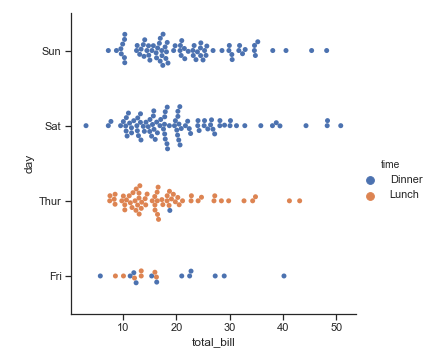
“分类坐标轴”,在这些例子中,我们的分类水平都与水平坐标轴绑定。但是有些时候我们把分类变量放在垂直坐标轴上会更有帮助(尤其是当分类名称较长或者分类较多时)。我们只需要交换x和y分配的变量即可:
sns.catplot(x="total_bill", y="day",
hue="time", kind="swarm", data=tips)
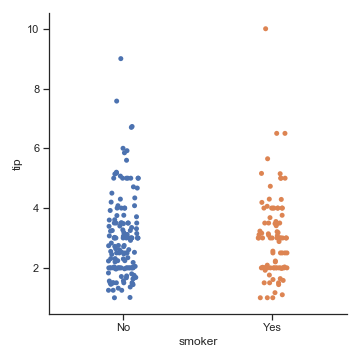
参数:order
我们还可以通过order参数指定分类的顺序,当我们需要绘制多个分类变量图时这一点会很重要:
sns.catplot(x="smoker", y="tip", order=["No", "Yes"], data=tips)
分类分布图
当数据集的大小越来越大,分类散点图在表现不同分类的观测值的分布信息时就越发显得捉襟见肘。此时,我们有一些方法,能以清晰明了的对比方式来总结不同分类下的观测值分布信息。
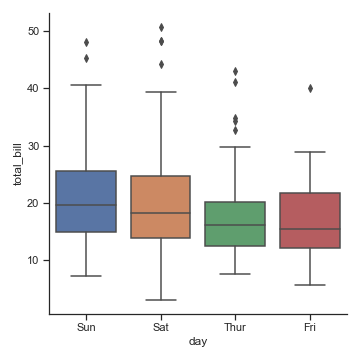
箱线图
boxplot(): 或 catplot(kind="box")
箱线图。它能在图中展现出数据的上下四分位数、中位数以及一些极值。箱体上下方的须线会分别向上和向下延伸1.5倍IQR(上下四分位数之间的距离),落在这个区域之外的点会单独显示为离群点(异常值)
sns.catplot(x="day", y="total_bill", kind="box", data=tips)
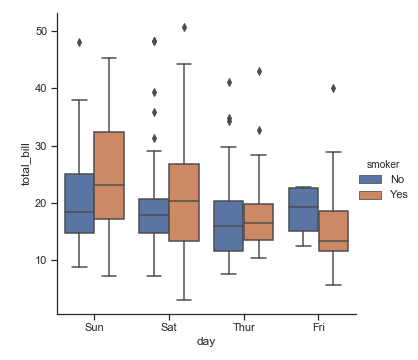
参数 hue
我们可以增加一个hue参数,这样就可以进一步增加一个维度来观察数据分布:
sns.catplot(x="day", y="total_bill",
hue="smoker", kind="box", data=tips)
参数:dodge
这种操作叫做“dodging”,它会默认保持打开,因为它假设 hue 参数对应的变量与坐标轴上的分类变量是相互嵌套的。假如事实并非如此,我们可以关闭“dodging”:
tips["weekend"] = tips["day"].isin(["Sat", "Sun"])
sns.catplot(x="day", y="total_bill", hue="weekend",
kind="box", dodge=False,data=tips)

增强箱图 Boxenplot
小提琴图
分类统计估计图
在某些应用场景中,相对于展示每个分类的数据分布,我们可能更想展示每个分类中数据的集中趋势估计(统计量,比如均值、中位数、方差等)。seaborn 有两种方式来展示此类信息。需要知道的是,这些函数基本的API与前边提到的那些绘图函数是一致的。
条形图
一种常见的图形是条形图。在seaborn中,barplot()函数在整个数据集上运行,并且应用一个函数来获得那些统计量(默认为均值)。当每个分类中有多个观测值时,它还可以通过 自助采样法 计算出一个置信区间,并且通过误差棒的方式绘制出来。
titanic = pd.read_csv('titanic.csv')
sns.catplot(x="sex", y="survived", hue="class",
kind="bar", data=titanic)

countplot
一个特例是我们想要展示每个分类下观测值(样本)的数量而非统计量。这就像是“属于分类变量而非连续变量的直方图”。在seaborn中,我们可以使用countplot()轻易地达成目的:
参数:kind=count
sns.catplot(x="deck", kind="count", palette="ch:.25", data=titanic)

barplot()和countplot()在调用的时候支持所有我们在上边讨论过的选项(参数),同时一些额外支持的参数在它们各自的详细文档中可以找到
sns.catplot(y="deck", hue="class", kind="count",
palette="pastel", edgecolor=".6",
data=titanic)

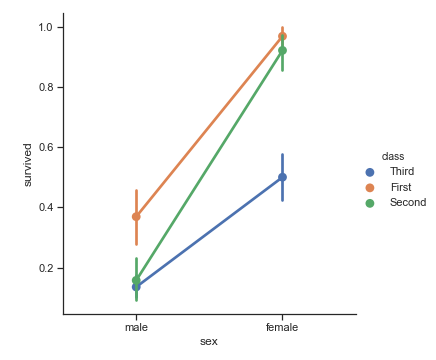
点图
我们也可以使用pointplot()来表现同样的信息。点图也使用高度来编码统计量,但是区别在于它不会画出一个完整的长条,而是用一个点以及置信区间来替代;另外,它还会将属于同一个hue分类的点连起来。这样,我们就可以很容易看到hue变量是如何影响坐标轴上的分类变量的(交互作用),因为不同线条的斜率简直是一目了然:
sns.catplot(x="sex", y="survived", hue="class", kind="point", data=titanic)
分类绘图函数是没有style这一参数的(在relplot()中有)。但是我们同样可以修改线条和点的样式,使得我们的图片更有可读性,甚至可以在黑白色调下表现分类信息(考虑到色盲读者时,黑白色调会很有帮助):
sns.catplot(x="class", y="survived", hue="sex",
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point", data=titanic)

使用子图展示多重关系
与relplot()一样,calplot()也是基于FacetGrid构建,这意味着我们可以轻易地通过更多子图来表现高维的关系:
sns.catplot(x="day", y="total_bill", hue="smoker",
col="time", aspect=.6,
kind="swarm", data=tips)
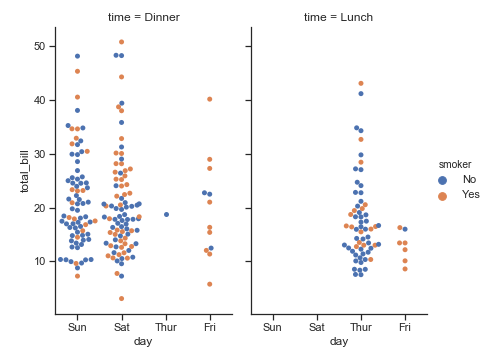
当我们想要定制更多细节时,我们就需要使用FacetGrid对象支持的方法了:
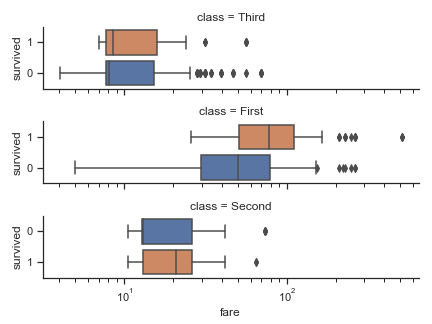
g = sns.catplot(x="fare", y="survived", row="class",
kind="box", orient="h", height=1.5, aspect=4,
data=titanic.query("fare > 0"))
g.set(xscale="log")
