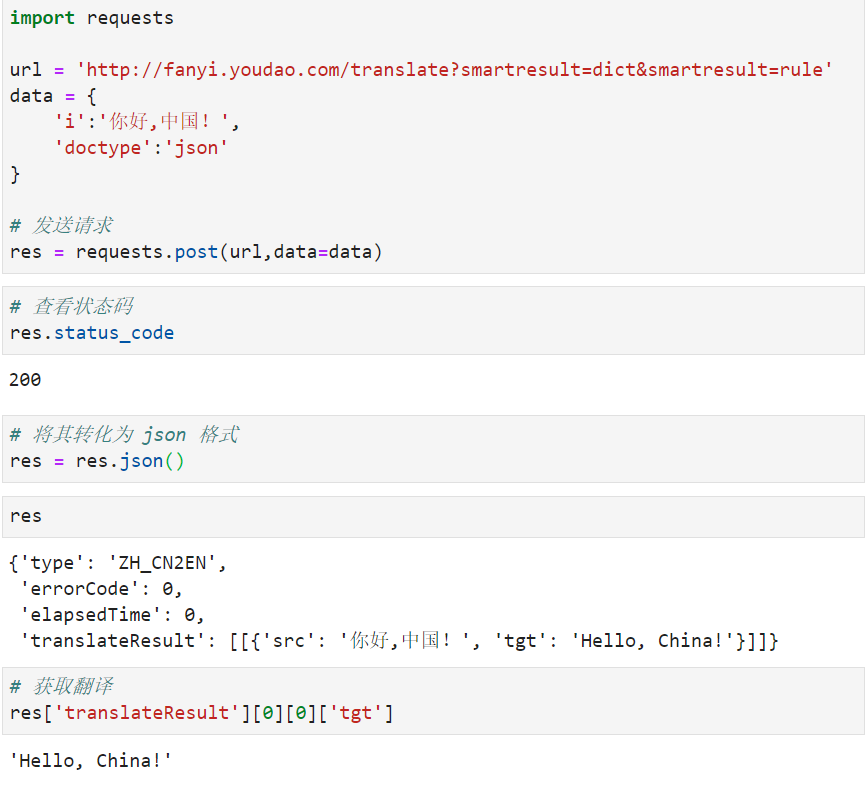
有道翻译案例
有道翻译界面:
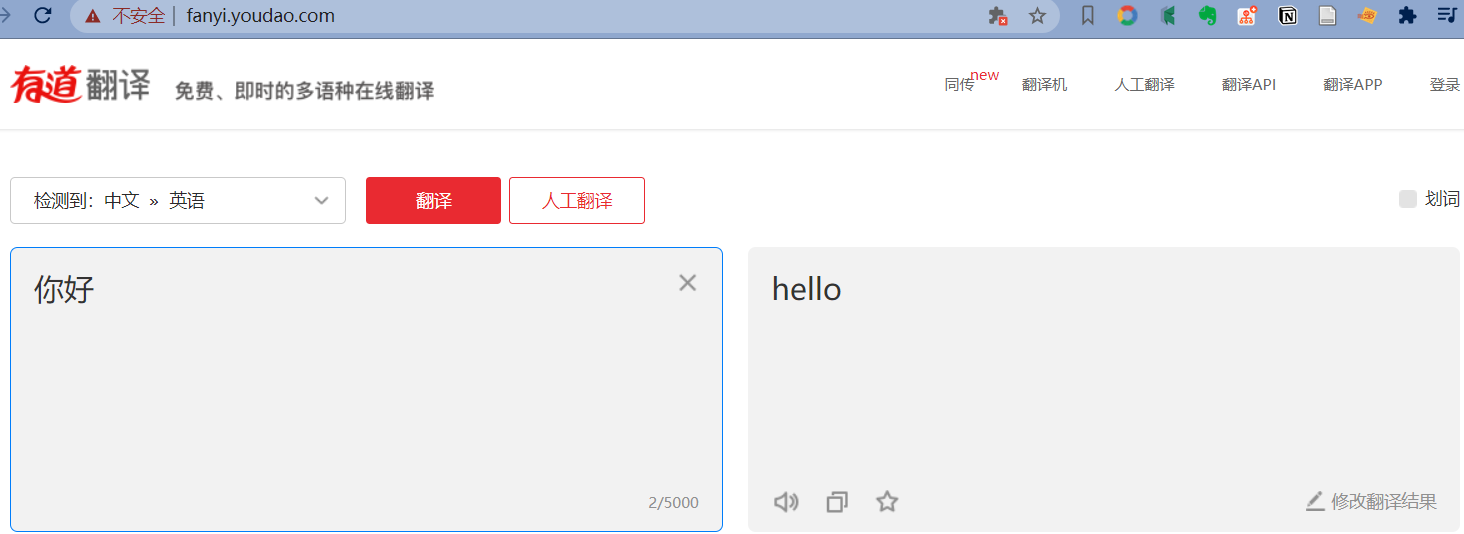
当我们进行语言翻译的时候,可以注意到浏览器的 url 并不会发生改变,这种是前端的 Ajax 技术。那么如何利用 python 爬虫解决这样的问题呢?
右键检查网页,Network 下面的 XHR (Xml Http Request)
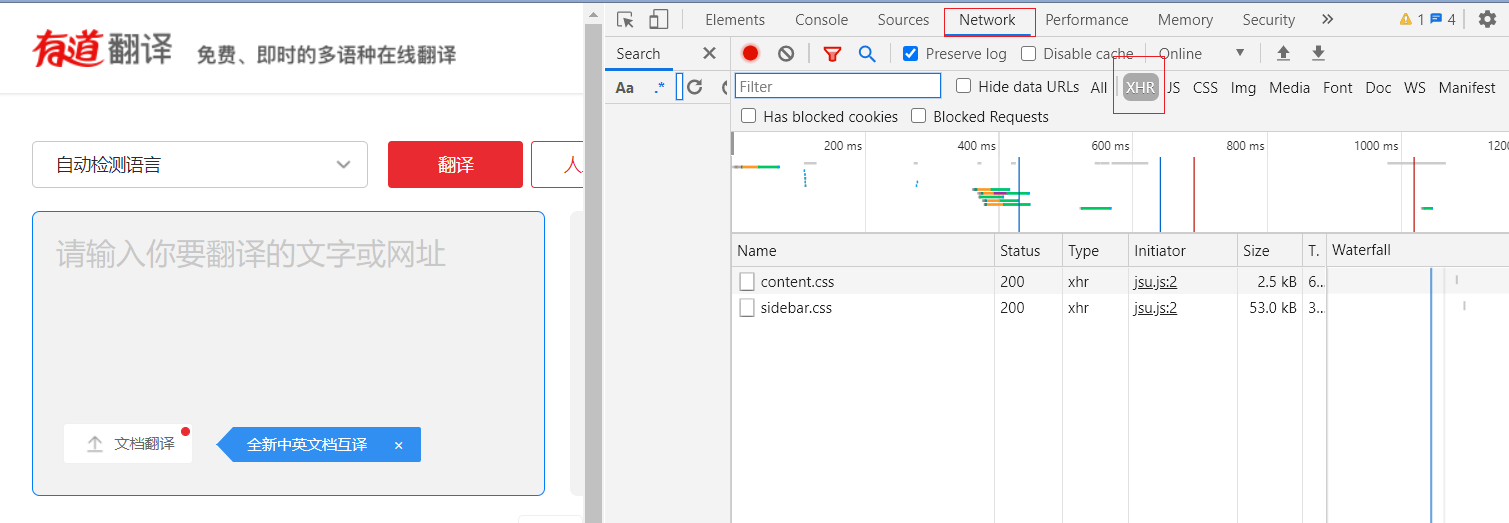
首先清空,在左侧的翻译处输入文字,观察右侧文件的变化;
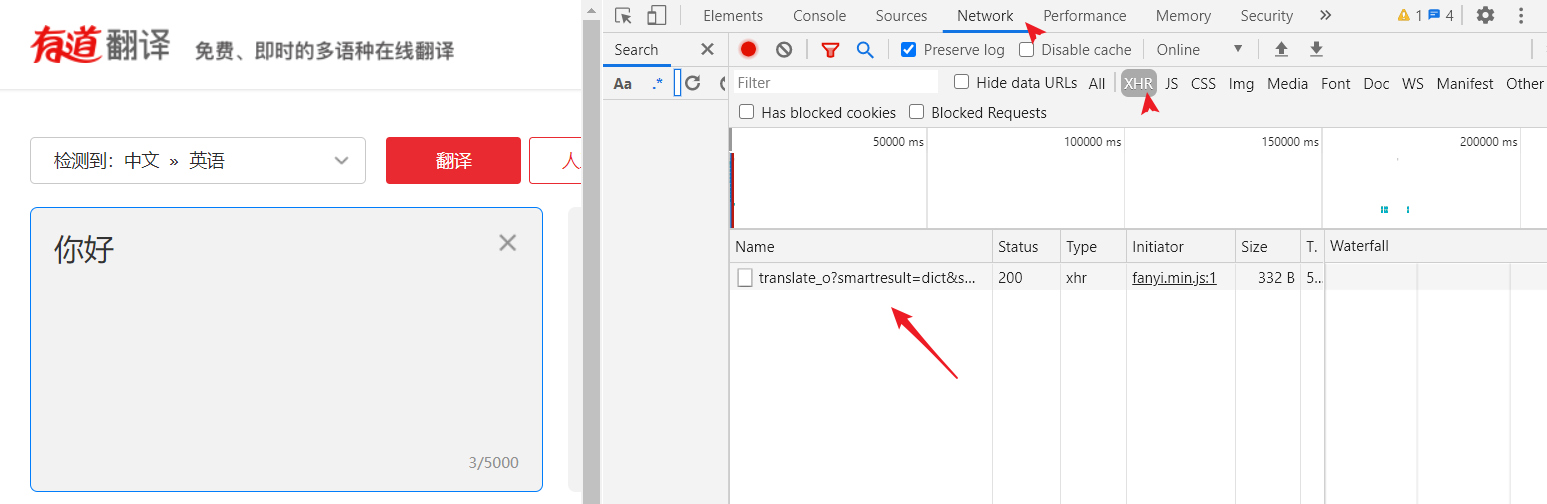
输入完文字回车后,可以看到右侧记载了一个新文件,点击查看文件
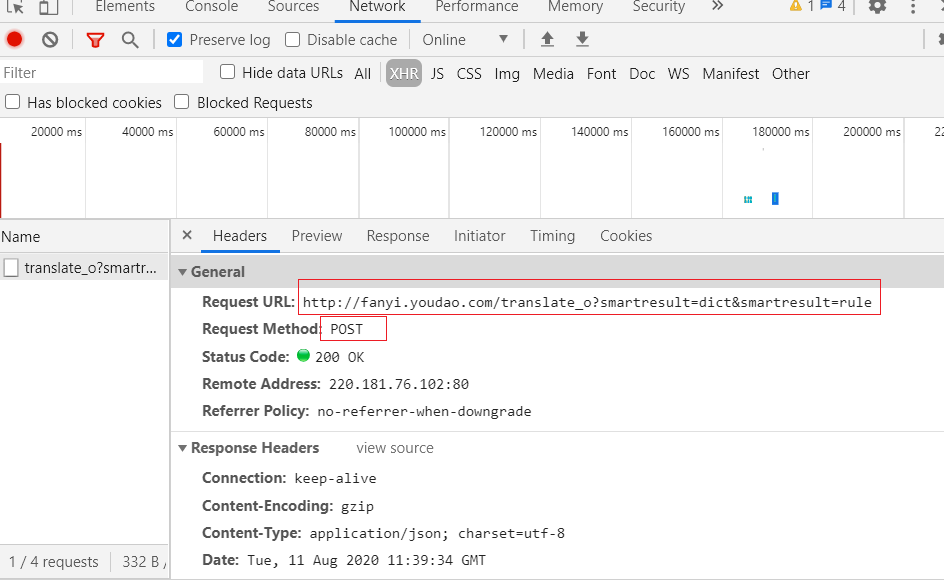
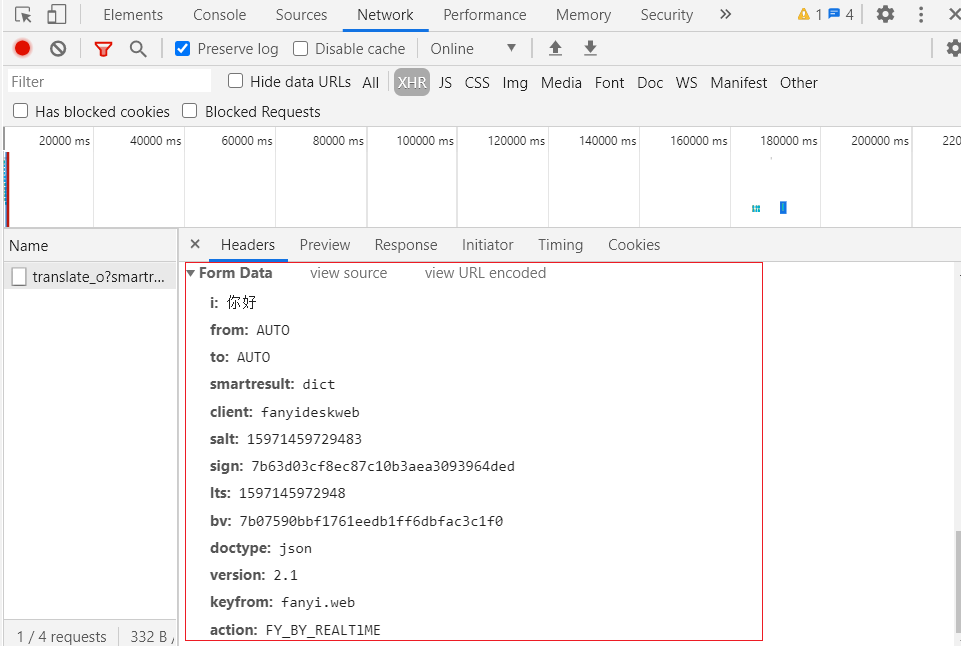
返回的内容
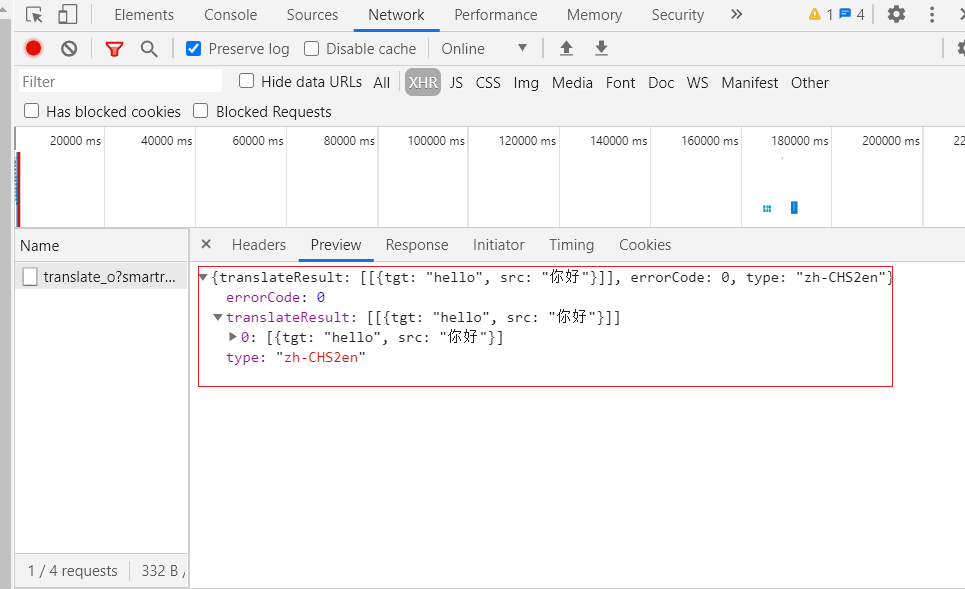
当我们输入完文字后,发送一个 POST 请求,返回的文件内容如上图所示,我们可以根据上面的 Request URL 和Form data 参数发送请求,接收并过滤返回的内容。
test :
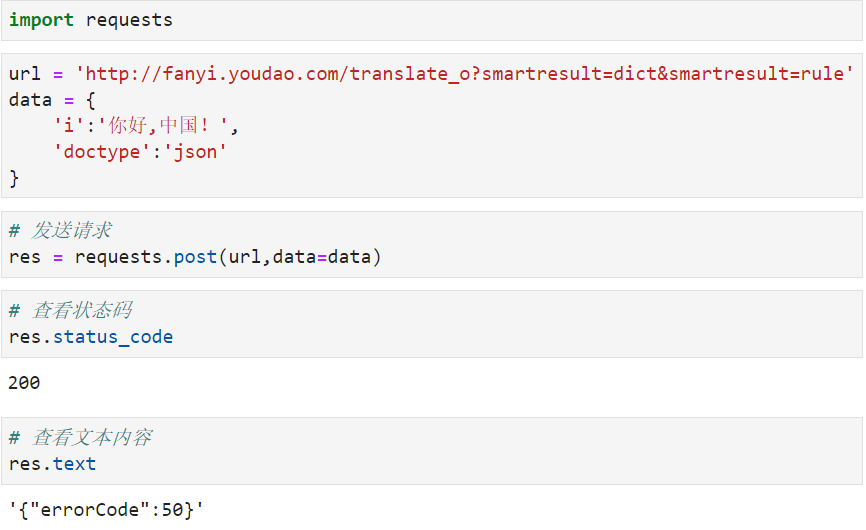
可以看到返回的状态是对的。但是文本内容是错的,正确返回应该是{"errorCode":50} , 是上面原因呢 ?
在网上查询之后

重新测试:
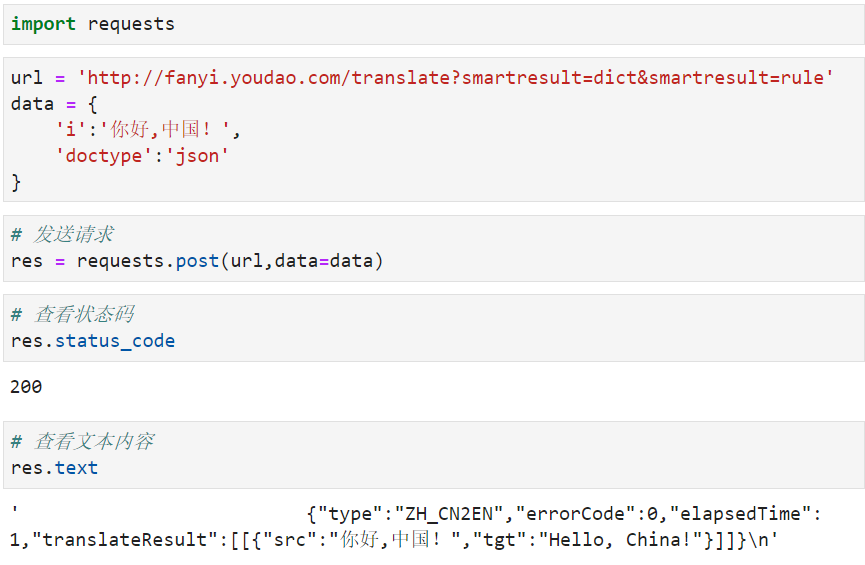
完全可以 !
完整代码: