selenium静态数据爬取
网站:http://www.cmakjgl.cn/cglist.aspx
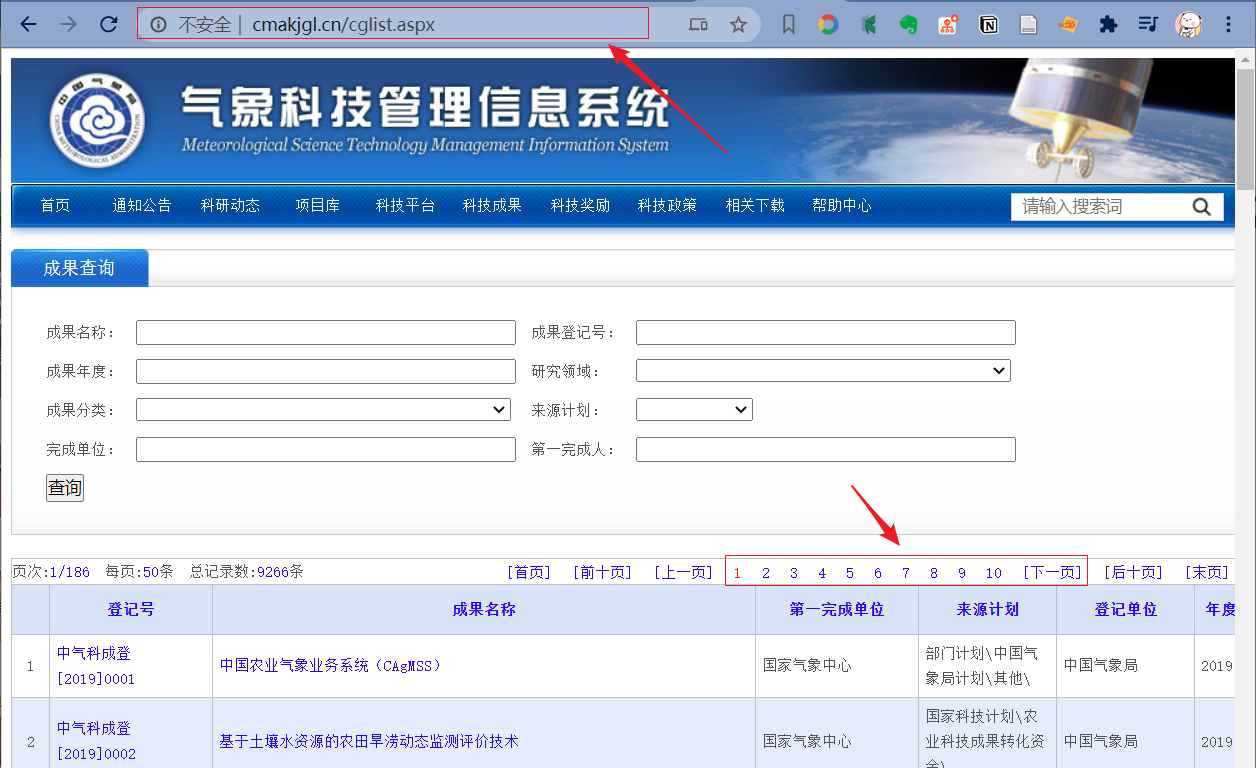
当我们切换不同页时,可以发现地址栏里的 url 是没有发生变化的,对于这样的网站我们可以分析数据接口
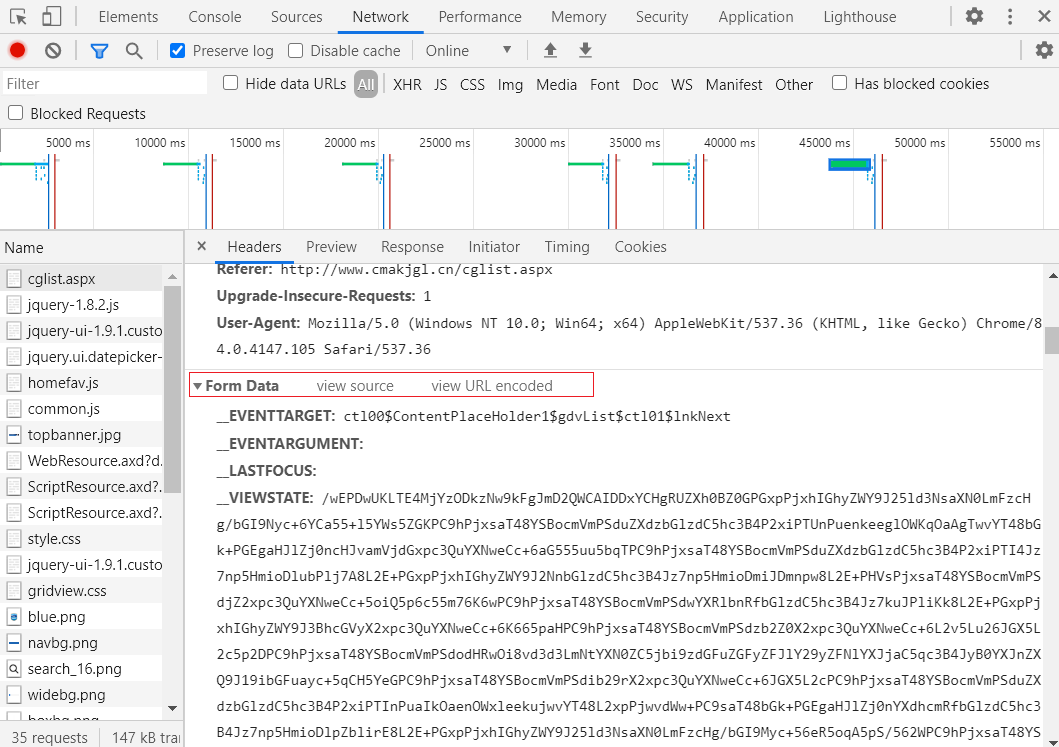
但传递的参数是进行加密的,无法正确解析所传递参数的含义,这是我们可以借助 selenium 进行数据的爬取;
代码:
import requests
import pandas as pd
import csv
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from lxml import etree
import time
from selenium.webdriver.chrome.options import Options
chrome_options=Options()
#设置chrome浏览器无界面模式
chrome_options.add_argument('--headless')
# 启动浏览器驱动
driver = webdriver.Chrome(chrome_options=chrome_options)
url = 'http://www.cmakjgl.cn/cglist.aspx'
driver.get(url)
# 停止 2 秒,留足时间
time.sleep(2)
# 窗口最大化
# driver.maximize_window()
# 循环的进行爬取
for ii in range(186):
# 寻找网页元素
element = driver.find_element_by_class_name('dg')
tr_lists = element.find_elements_by_tag_name('tr')
# 获取页面的句柄值
window_2 = driver.current_window_handle
for i in range(len(tr_lists)-3):
# 定义空列表
data1 = []
# 记录是从当前表格的第三(i+2)行开始的,然后找到当前行的所有单元格
td_lists = tr_lists[i+2].find_elements_by_tag_name('td')
# 获取单元格的内容
for td_list in td_lists:
data1.append(td_list.text)
# 获取表格的超链接
# 当前表格共 100个这样的链接,每行有两个,我们需要点击第二个,打开新的页面
abstract_buttons = driver.find_elements_by_xpath('//a[contains(@href,"cgview.aspx?id=")]')
abstract_buttons[0+i*2].click()
print('abstract_page ' + str(i+1)+ " has done")
# 等待三秒, 加载新的网页
time.sleep(3)
# 获取当前窗口的句柄
window_1 = driver.current_window_handle
# 获取所有窗口的句柄值
hand4 = driver.window_handles
# 获取所有窗口的句柄值, 并切换至当前窗口
for current_window in hand4:
if current_window != window_1:
driver.switch_to.window(current_window)
# 获取摘要信息,并显示
abstract = driver.find_element_by_xpath('//span[@id="ctl00_ContentPlaceHolder1_lblACHIVE_BRIEF"]')
data1.append(abstract.text)
# 关闭摘要信息窗口
driver.close()
# 切换回原窗口
driver.switch_to.window(window_2)
data2 = pd.DataFrame(data1).T
data2.to_csv('qixiang0.csv',header=False,index=False,mode='a+')
print('page '+ str(ii+1) +' has done')
next_page_button = driver.find_element_by_xpath('//a[@id="ctl00_ContentPlaceHolder1_gdvList_ctl01_lnkNext"]')
next_page_button.click()
程序的关键是模拟点击行为后,对网页进行循环的爬取。
参考
- B站 :龙王山小青椒 python爬虫-成名绝技selenium-所见即所得