Pandas爬取表格数据
table型表格
我们在网页上会经常看到这样一些表格,比如:
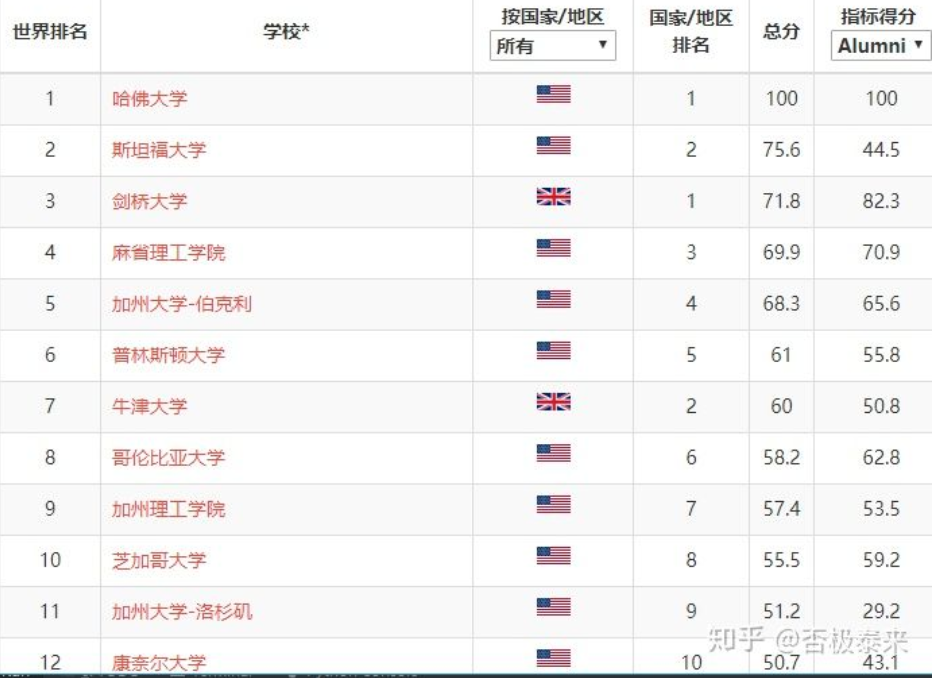
从中可以看到table类型的表格网页结构大致如下:
<table class="..." id="...">
<thead>
<tr>
<th>...</th>
</tr>
</thead>
<tbody>
<tr>
<td>...</td>
</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
...
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
<tr>...</tr>
</tbody>
</table>
先来简单解释一下上文出现的几种标签含义:
<table> : 定义表格
<thead> : 定义表格的页眉
<tbody> : 定义表格的主体
<tr> : 定义表格的行
<th> : 定义表格的表头
<td> : 定义表格单元
这样的表格数据,就可以利用pandas模块里的read_html函数方便快捷地抓取下来。下面我们就来操作一下。
快速抓取
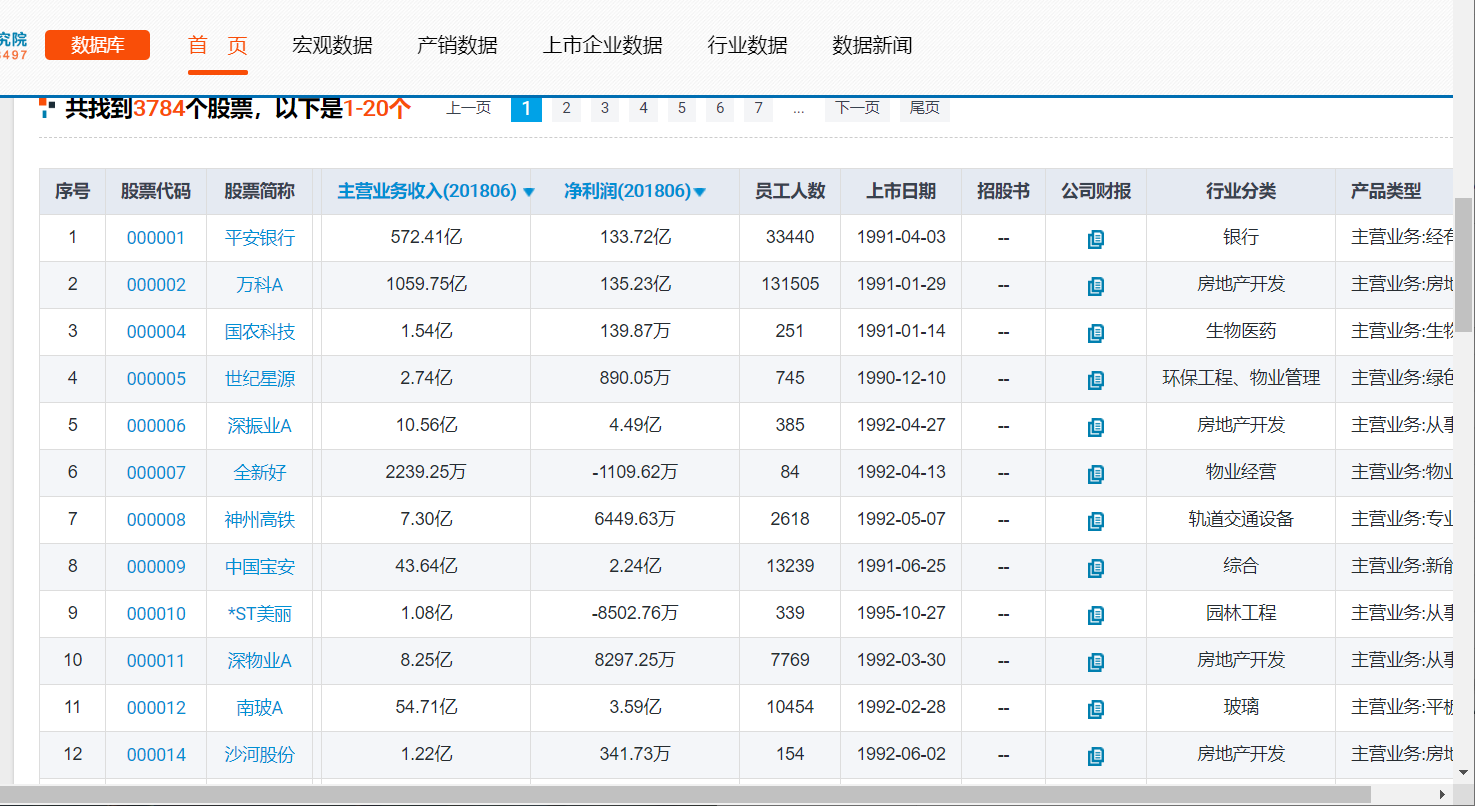
下面以中国上市公司信息这个网页中的表格为例,感受一下read_html函数的强大之处。
import pandas as pd
writer = pd.ExcelWriter("股票.xlsx", engine='openpyxl', mode='a')
for i in range(1,178): # 爬取全部177页数据
url = 'http://s.askci.com/stock/a/?reportTime=2018-06-30&pageNum=%s' % (str(i))
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_excel(writer, sheet_name=str(i), index=False)
print('第'+str(i)+'页抓取完成')
writer.save()
writer.close()
只需不到十行代码,1分钟左右就可以将全部178页共3535家A股上市公司的信息干净整齐地抓取下来。比采用正则表达式、xpath这类常规方法要省心省力地多。如果采取人工一页页地复制粘贴到excel中,就得操作到猴年马月去了。
详细代码实现
read_html函数
先来了解一下read_html函数的api:
def read_html(
io,
match=".+",
flavor=None,
header=None,
index_col=None,
skiprows=None,
attrs=None,
parse_dates=False,
thousands=",",
encoding=None,
decimal=".",
converters=None,
na_values=None,
keep_default_na=True,
displayed_only=True,
):
r"""
Read HTML tables into a ``list`` of ``DataFrame`` objects.
Parameters
----------
io : str, path object or file-like object
A URL, a file-like object, or a raw string containing HTML. Note that
lxml only accepts the http, ftp and file url protocols. If you have a
URL that starts with ``'https'`` you might try removing the ``'s'``.
match : str or compiled regular expression, optional
The set of tables containing text matching this regex or string will be
returned. Unless the HTML is extremely simple you will probably need to
pass a non-empty string here. Defaults to '.+' (match any non-empty
string). The default value will return all tables contained on a page.
This value is converted to a regular expression so that there is
consistent behavior between Beautiful Soup and lxml.
flavor : str or None
The parsing engine to use. 'bs4' and 'html5lib' are synonymous with
each other, they are both there for backwards compatibility. The
default of ``None`` tries to use ``lxml`` to parse and if that fails it
falls back on ``bs4`` + ``html5lib``.
header : int or list-like or None, optional
The row (or list of rows for a :class:`~pandas.MultiIndex`) to use to
make the columns headers.
index_col : int or list-like or None, optional
The column (or list of columns) to use to create the index.
skiprows : int or list-like or slice or None, optional
Number of rows to skip after parsing the column integer. 0-based. If a
sequence of integers or a slice is given, will skip the rows indexed by
that sequence. Note that a single element sequence means 'skip the nth
row' whereas an integer means 'skip n rows'.
attrs : dict or None, optional
This is a dictionary of attributes that you can pass to use to identify
the table in the HTML. These are not checked for validity before being
passed to lxml or Beautiful Soup. However, these attributes must be
valid HTML table attributes to work correctly. For example, ::
attrs = {'id': 'table'}
is a valid attribute dictionary because the 'id' HTML tag attribute is
a valid HTML attribute for *any* HTML tag as per `this document
<http://www.w3.org/TR/html-markup/global-attributes.html>`__. ::
attrs = {'asdf': 'table'}
is *not* a valid attribute dictionary because 'asdf' is not a valid
HTML attribute even if it is a valid XML attribute. Valid HTML 4.01
table attributes can be found `here
<http://www.w3.org/TR/REC-html40/struct/tables.html#h-11.2>`__. A
working draft of the HTML 5 spec can be found `here
<http://www.w3.org/TR/html-markup/table.html>`__. It contains the
latest information on table attributes for the modern web.
parse_dates : bool, optional
See :func:`~read_csv` for more details.
thousands : str, optional
Separator to use to parse thousands. Defaults to ``','``.
encoding : str or None, optional
The encoding used to decode the web page. Defaults to ``None``.``None``
preserves the previous encoding behavior, which depends on the
underlying parser library (e.g., the parser library will try to use
the encoding provided by the document).
decimal : str, default '.'
Character to recognize as decimal point (e.g. use ',' for European
data).
converters : dict, default None
Dict of functions for converting values in certain columns. Keys can
either be integers or column labels, values are functions that take one
input argument, the cell (not column) content, and return the
transformed content.
na_values : iterable, default None
Custom NA values.
keep_default_na : bool, default True
If na_values are specified and keep_default_na is False the default NaN
values are overridden, otherwise they're appended to.
displayed_only : bool, default True
Whether elements with "display: none" should be parsed.
- io:接收网址,文件,字符串。网址不接受https,尝试去掉s后爬取
- match:正则表达式,返回与正则表达式匹配的表格。默认".+"
- flavor:解析器。默认为(“lxml”,“bs4”)
- header:指定列标题所在的行
- index_col:指定行标题对应的列
- skiprows:跳过第n行
- attrs:传递一个字典,标示表格的属性值
- parse_dates:解析日期
- thousands:千位分隔符
- encoding:编码方式
- decimal:小数点指示,默认使用"."
- converters:转换某些列的函数的字典
- na_values:标示那些为NA的值
- keep_default_na:保持默认的NA值,与na_values一起使用
- displayed_only:是否应解析具有"display:none"的元素。默认为True
缺点:如果网站需要使用用户代理(User_Agent),那么read_html就无法爬取成功
参考