爬取京东商品评论
打开京东主页,找到需要爬取评论的商品:
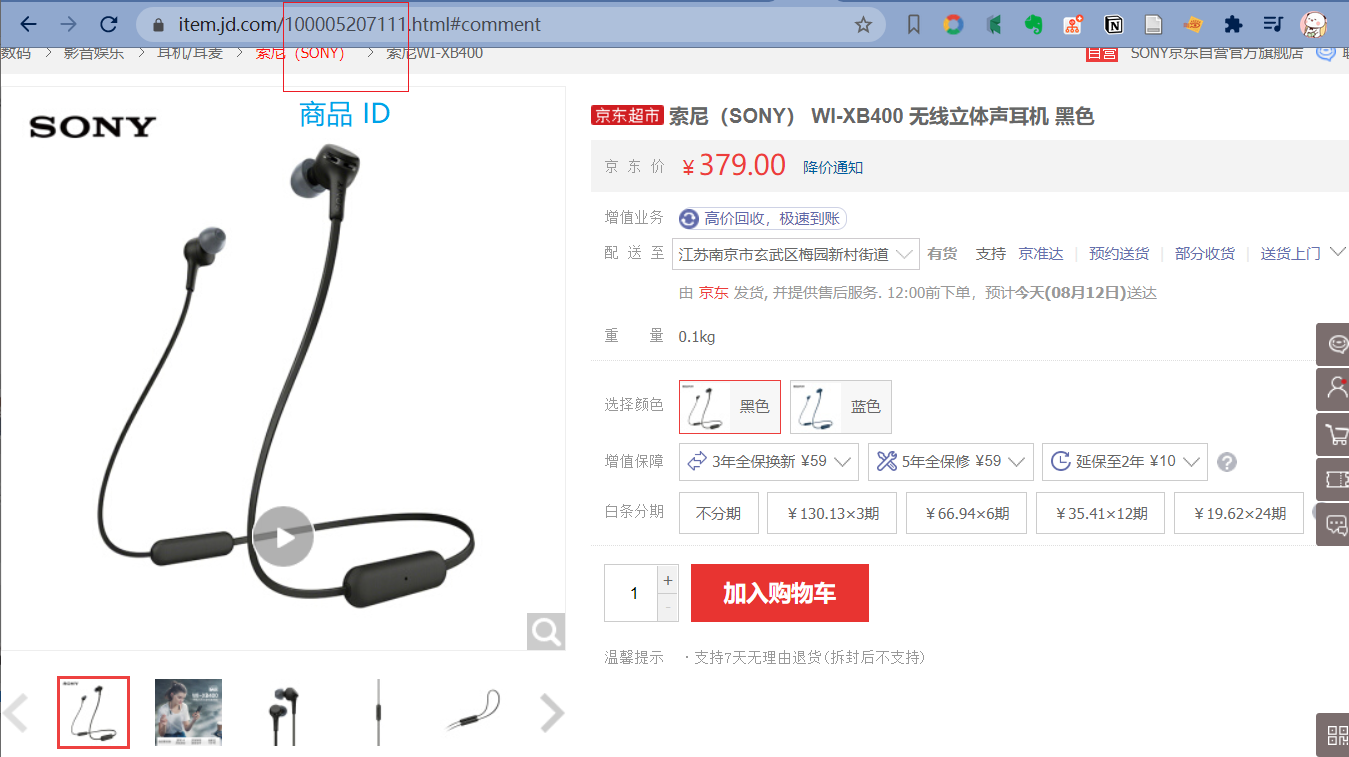
右键 检查网页,将记载的文件先清空,找到商品评论处 ,当切换不同页的评论时,可以看到加载出新的文件:
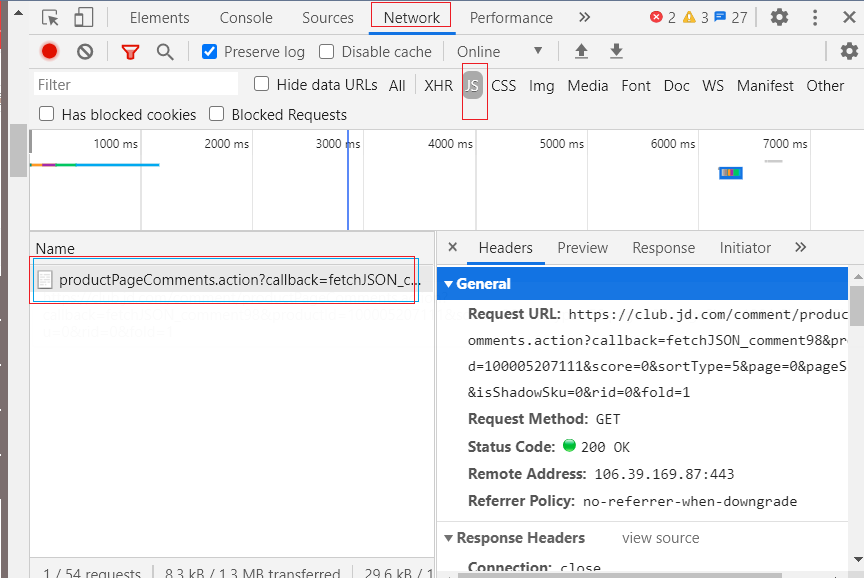
将 Request URL 复制到浏览器可以看到本页评论的内容;
url 分析:https://club.jd.com/comment/productPageComments.action? 后面的部分是请求所需的参数,在下面的 Query String Parameters 中也可以看到。在发送请求的时候 将 https://club.jd.com/comment/productPageComments.action? 作为 url, 后面的部分作为参数进行传递。
参数解析:
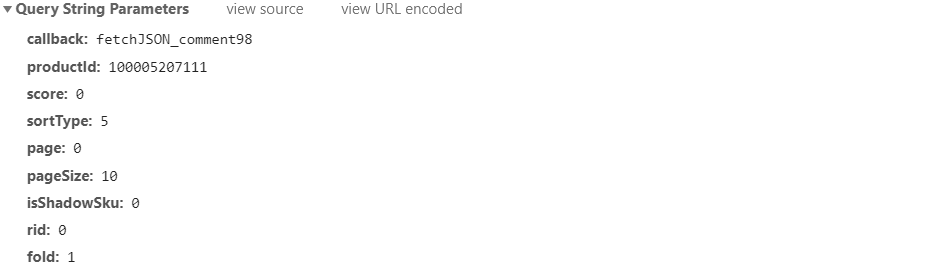
- callback: 固定参数
- productId: 商品 ID
- score: 不同的评价类型,
- 0 : 全部评价
- 1:差评
- 2:中评
- 3:好评
- sortType: 评论排序方式:推荐排序(5),时间排序(6)
- page: 评论页,通过改变评论页,可以实现不同页面评论的循环爬取
- pageSize: 固定参数
- isShadowSku:
- rid:
- fold:
测试:
import requests
import json
import re
import pandas as pd
import time
url = 'https://club.jd.com/comment/productPageComments.action?'
for i in range(50):
# 请求参数
params = {
'callback': 'fetchJSON_comment98', # 固定值
'productId': '100005207111', # 产品 ID
'score': '0', # 0-5 分别对应不同的评价,好评、中评、全部评价等
'sortType': '5', # 排序方式
'page': i, # 当前的评论页
'pageSize': '10', # 每页评论的数量
'isShadowSku': '0',
'rid': '0',
'fold': '1'
}
headers = {
'Referer': 'https://item.jd.com/100005207111.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Cookie': '__jdu=1568007721111834248469; shshshfpa=6814de79-d912-fb65-2445-e0c1001418be-1568007725; shshshfpb=eK6h%2FTTG3UOQIjI3nubc4rg%3D%3D; pinId=uKm5zMomrBzAmLNKou2uKDqrJX175ugD; unpl=V2_ZzNtbRcFShclDkVTchwOAGIDR1VKV0EWcwxCBnobD1IzURFaclRCFnQUR11nGF4UZgsZX0RcQRNFCEVkexhdBGAAE19BVXMlRQtGZHopXAFgChNcRFFAFXUIRl15HF8AbgYVVXJnRBV8OHYfIl9VAmIAE1hAVEcldg1BUX8bbARXARNcQVBKFXwJRmQwd11IZwcVVENWRRN2CEZUexBeAGQGG1hFX3MVdAlHVXseXQZmMxE%3d; __jdv=122270672|google|tw6|cpc|not set|1596435399183; areaId=12; ipLoc-djd=12-904-3373-0; PCSYCityID=CN_320000_320100_0; __jdc=122270672; __jda=122270672.1568007721111834248469.1568007721.1596435399.1597198601.61; shshshfp=220f18c9406df7935c99c0b11d700617; 3AB9D23F7A4B3C9B=IXUELWJK3WKMGCI6K6VNEMY5JTJRYFIN7UACHEU53PFRGL26M3Z4EPHTURYSBFSZOFLSHWLCALKBM2HL2Z6PVCSWZ4; jwotest_product=99; wlfstk_smdl=ehul02b6y6mrpp3c0io9rgen0mvqvz09; TrackID=1odMbOfz9qDnsQUriX0MI0xuEBMGOvndQJls-Cnyljpewp5cEF-8coPrSiWOAgRyjr8am57HCcwV9xQf_rr3xTPy5hoA-MhDYUFaH7zOoUlO458mlGY3vk0rpwZPB_jrZ; thor=E720FC5049F725A474B2F674576F76565C554ECB4F3557F926E8468A57A9F7319EE2F9D0A1DB99CB745E9A3DD4FB61D813FCC037D93474C5510BE4250A6DA7A54A946F6619D1239AE6A096341CF9A38620295216FAF185554394D80EC04D8B5A7B46EF7FC4618FA645AD46ED4BD7383928B3013693A6F5931E4F5AA7EFCBBA78; pin=%E4%B8%B6%E5%8C%97%E5%9F%8E%E9%B1%BC%E5%AE%89%E7%94%9F; unick=___%E6%A2%A6%E5%AF%90___; ceshi3.com=000; _tp=6KbAcOO79y3rwvtuJvHoHRBSFSbWIqCOxKNAM%2FSmxbwMBsbJ8KsKQWmVHGQC11rU1S2%2FwNGWzgqqKzflVhJMlw%3D%3D; _pst=%E4%B8%B6%E5%8C%97%E5%9F%8E%E9%B1%BC%E5%AE%89%E7%94%9F; shshshsID=8ed6a639183b7cc4d65115ddd4ec2c4b_5_1597199326879; __jdb=122270672.8.1568007721111834248469|61.1597198601; JSESSIONID=C4161CA90DF9781E4CF679DB423DF2D6.s1'
}
res = requests.get(url=url,params=params,headers=headers)
print(res.status_code)
# 返回的内容并不是规范的json 格式文件, 利用正则表达式将其转化为规范的 json 文件
html_json = re.search('(?<=fetchJSON_comment98\().*(?=\);)',res.text).group(0)
j = json.loads(html_json)
for jj in range(len(j['comments'])):
data1 = [j['comments'][jj]['content']]
data2 = pd.DataFrame(data1)
# print(data1)
data2.to_csv('jd.csv',header=False,index=False,mode='a+')
time.sleep(3)
print('page'+str(1+i)+' has done')
上面是商品的全部评价,当然也可以只爬取当前商品的评价;
刷新网页,检查,清空。 选择只看当前商品评价:
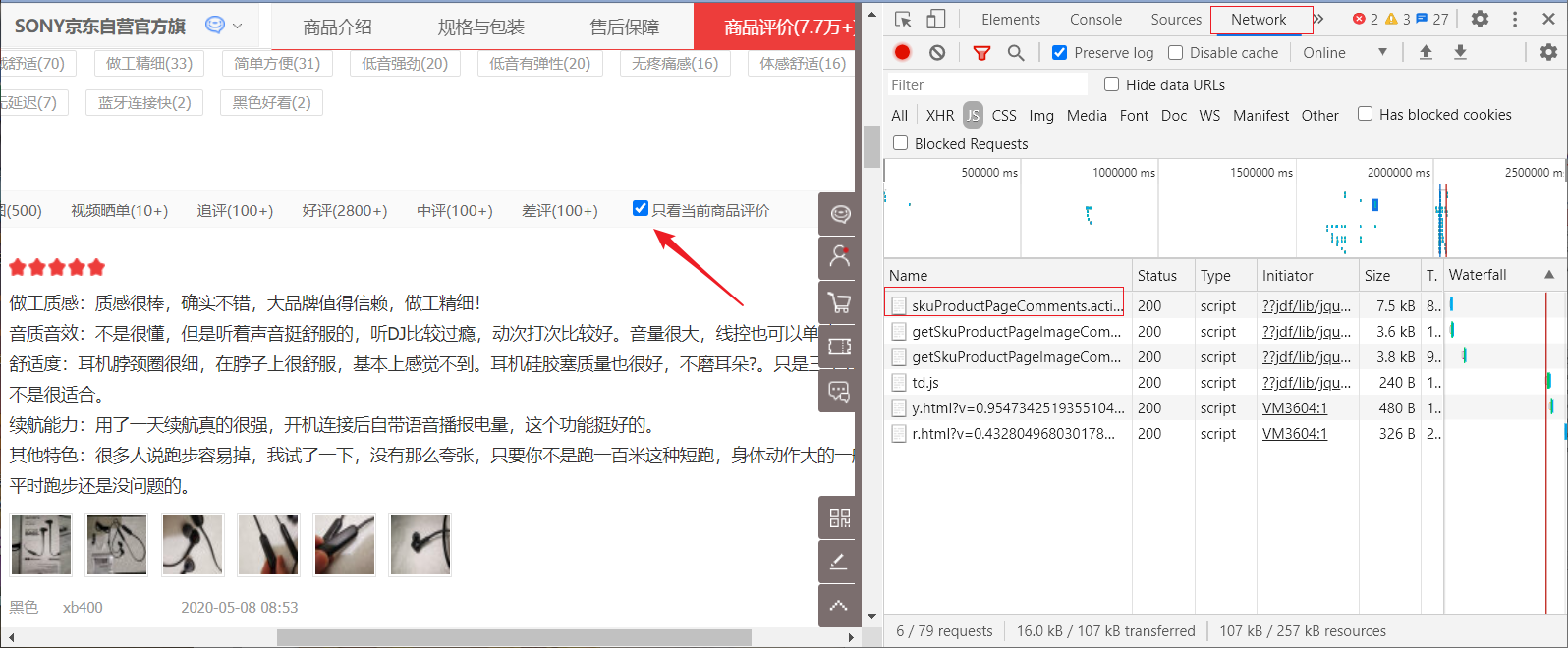
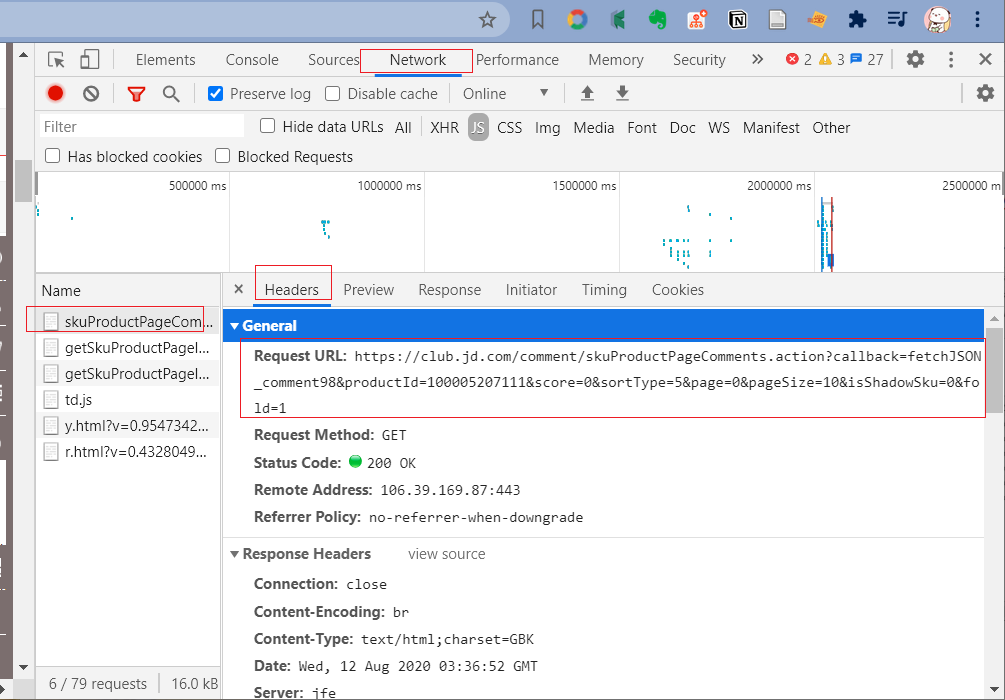
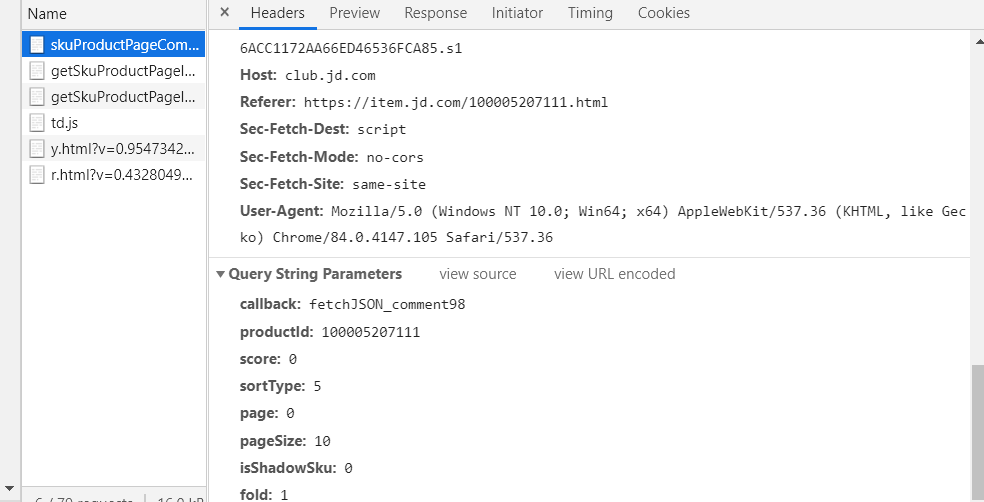
我们同样可以 发送Request URL 的 request 请求,并传递相应的参数获取评论。
测试:
# -*- encoding: utf-8 -*-
"""
@software: PyCharm
@file : jd2.py
@time : 2020/8/12
"""
import requests
import json
import re
import pandas as pd
import time
url = 'https://club.jd.com/comment/skuProductPageComments.action?'
for i in range(25):
# 请求参数, 与全部评价相比少了一个 'rid' 参数
params = {
'callback': 'fetchJSON_comment98', # 固定值
'productId': '100005207111', # 产品 ID
'score': '0', # 0-5 分别对应不同的评价,好评、中评、全部评价等
'sortType': '5', # 排序方式
'page': i, # 当前的评论页
'pageSize': '10', # 每页评论的数量
'isShadowSku': '0',
'fold': '1'
}
headers = {
'Referer': 'https://item.jd.com/100005207111.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'Cookie': '__jdu=1568007721111834248469; shshshfpa=6814de79-d912-fb65-2445-e0c1001418be-1568007725; shshshfpb=eK6h%2FTTG3UOQIjI3nubc4rg%3D%3D; pinId=uKm5zMomrBzAmLNKou2uKDqrJX175ugD; unpl=V2_ZzNtbRcFShclDkVTchwOAGIDR1VKV0EWcwxCBnobD1IzURFaclRCFnQUR11nGF4UZgsZX0RcQRNFCEVkexhdBGAAE19BVXMlRQtGZHopXAFgChNcRFFAFXUIRl15HF8AbgYVVXJnRBV8OHYfIl9VAmIAE1hAVEcldg1BUX8bbARXARNcQVBKFXwJRmQwd11IZwcVVENWRRN2CEZUexBeAGQGG1hFX3MVdAlHVXseXQZmMxE%3d; __jdv=122270672|google|tw6|cpc|not set|1596435399183; areaId=12; ipLoc-djd=12-904-3373-0; PCSYCityID=CN_320000_320100_0; __jdc=122270672; __jda=122270672.1568007721111834248469.1568007721.1596435399.1597198601.61; shshshfp=220f18c9406df7935c99c0b11d700617; 3AB9D23F7A4B3C9B=IXUELWJK3WKMGCI6K6VNEMY5JTJRYFIN7UACHEU53PFRGL26M3Z4EPHTURYSBFSZOFLSHWLCALKBM2HL2Z6PVCSWZ4; jwotest_product=99; wlfstk_smdl=ehul02b6y6mrpp3c0io9rgen0mvqvz09; TrackID=1odMbOfz9qDnsQUriX0MI0xuEBMGOvndQJls-Cnyljpewp5cEF-8coPrSiWOAgRyjr8am57HCcwV9xQf_rr3xTPy5hoA-MhDYUFaH7zOoUlO458mlGY3vk0rpwZPB_jrZ; thor=E720FC5049F725A474B2F674576F76565C554ECB4F3557F926E8468A57A9F7319EE2F9D0A1DB99CB745E9A3DD4FB61D813FCC037D93474C5510BE4250A6DA7A54A946F6619D1239AE6A096341CF9A38620295216FAF185554394D80EC04D8B5A7B46EF7FC4618FA645AD46ED4BD7383928B3013693A6F5931E4F5AA7EFCBBA78; pin=%E4%B8%B6%E5%8C%97%E5%9F%8E%E9%B1%BC%E5%AE%89%E7%94%9F; unick=___%E6%A2%A6%E5%AF%90___; ceshi3.com=000; _tp=6KbAcOO79y3rwvtuJvHoHRBSFSbWIqCOxKNAM%2FSmxbwMBsbJ8KsKQWmVHGQC11rU1S2%2FwNGWzgqqKzflVhJMlw%3D%3D; _pst=%E4%B8%B6%E5%8C%97%E5%9F%8E%E9%B1%BC%E5%AE%89%E7%94%9F; shshshsID=8ed6a639183b7cc4d65115ddd4ec2c4b_5_1597199326879; __jdb=122270672.8.1568007721111834248469|61.1597198601; JSESSIONID=C4161CA90DF9781E4CF679DB423DF2D6.s1'
}
res = requests.get(url=url,params=params,headers=headers)
print(res.status_code)
# 返回的内容并不是规范的json 格式文件, 利用正则表达式将其转化为规范的 json 文件
html_json = re.search('(?<=fetchJSON_comment98\().*(?=\);)',res.text).group(0)
j = json.loads(html_json)
for jj in range(len(j['comments'])):
data1 = [j['comments'][jj]['content']]
data2 = pd.DataFrame(data1)
# print(data1)
data2.to_csv('jd_dq.csv',header=False,index=False,mode='a+')
time.sleep(3)
print('page'+str(1+i)+'has done')

参考
- B站 :龙王山小青椒 python京东评论抓取-分词-词云展示