requests库:代理proxies
当频繁请求一个网站时,对方会认为攻击或者盗取数据,禁用1p是反制的有效手段。 如何破解这个问题?
- 推荐方案就是降低爬虫请求的频率,不要对别人的服务器造成压力。
- 使用代理P
什么是代理:
代理相当于一个连接客户端和远程服务器的“中转站
当我们向服务器提出请求后,代理服务器先获取用户的请求,再将服务请求转交至远程服务器,并将远程服务器反馈的结果再转交给客户端。这就相当于,和服务端打交道的是代理服务器
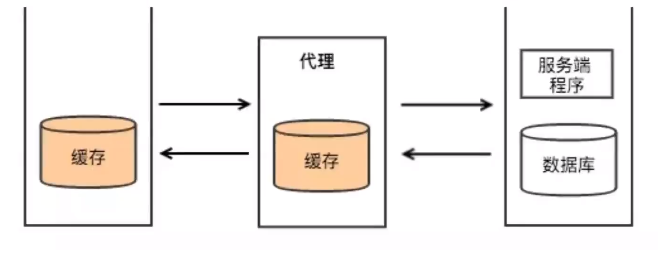
使用场景
- 目标网站会根据P的访问频度判断如果超过正常频度,就会限制该P,拒绝访问,这个时候就需要使用代理IP,来伪装真实 IP 身份
作用
- 使用代理之后,远程服务器只能探测到代理服务器的P地址而不是上网者的真实P,从而达到隐藏上网者IP地址的目的,保障了上网者的网络安全
代理的作用:
一般分为透明代理、普通匿名代理和高匿代理
- 透明代理:远程服务器可以知道你使用了代理,并且透明也会将本机真实的P发送至远程服务器,因此无法达到隐藏身份的目的
- 匿名代理:远程服务器可以知道你使用了代理,但不知道你的真实 IP
- 高匿代理:高匿名代理隐藏了你的真实 IP,同时访问对象也不知道你使用了代理,因此隐蔽度最高
代理网站:
西祠代理、快代理、豌豆代理、蘑菇代理等等。
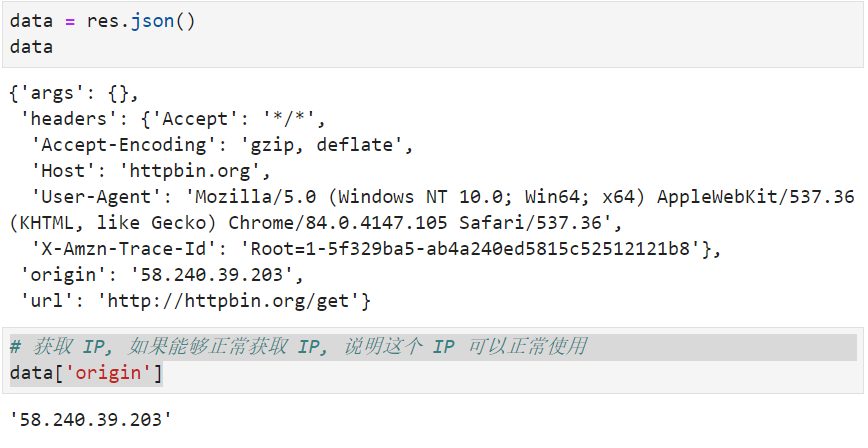
测试本机 IP
测试:
import requests
# 请求的 url, 可以查看本机 IP
url = "http://httpbin.org/get"
headers = {
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# 发送 get 请求
res = requests.get(url,headers=headers)
# 查看状态码
res.status_code
# 200
定义代理 IP
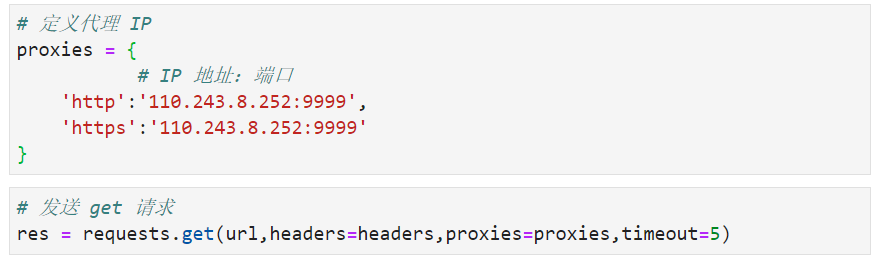
链接超时:

可以去代理网站重新找新的 IP (可以利用爬虫爬取,也可以使用代理提供的 API 进行获取)
直到获取可以访问的代理 IP
并查看其返回的状态码和 IP
# 查看状态码
res.status_code
data = res.json()
# 获取 IP, 如果能够正常获取 IP, 说明这个 IP 可以正常使用
data['origin']