拉钩网数据爬取
特别声明
众所周知,拉勾网的反爬机制更新较为频繁,本博客所分享的方法不一定永久有效,即具有时效性。研究该网站的反爬机制仅供交流学习,千万不要用于做违法的事情。
网站介绍
拉勾网是一个专业的互联网招聘平台,该网站上有很多公司的招聘信息,所以该网站也成了很多爬虫爬取的重点对象。
思路分析
本文以Python为例进行思路分析,首先,在搜索框中输入关键字Python,并点击搜索
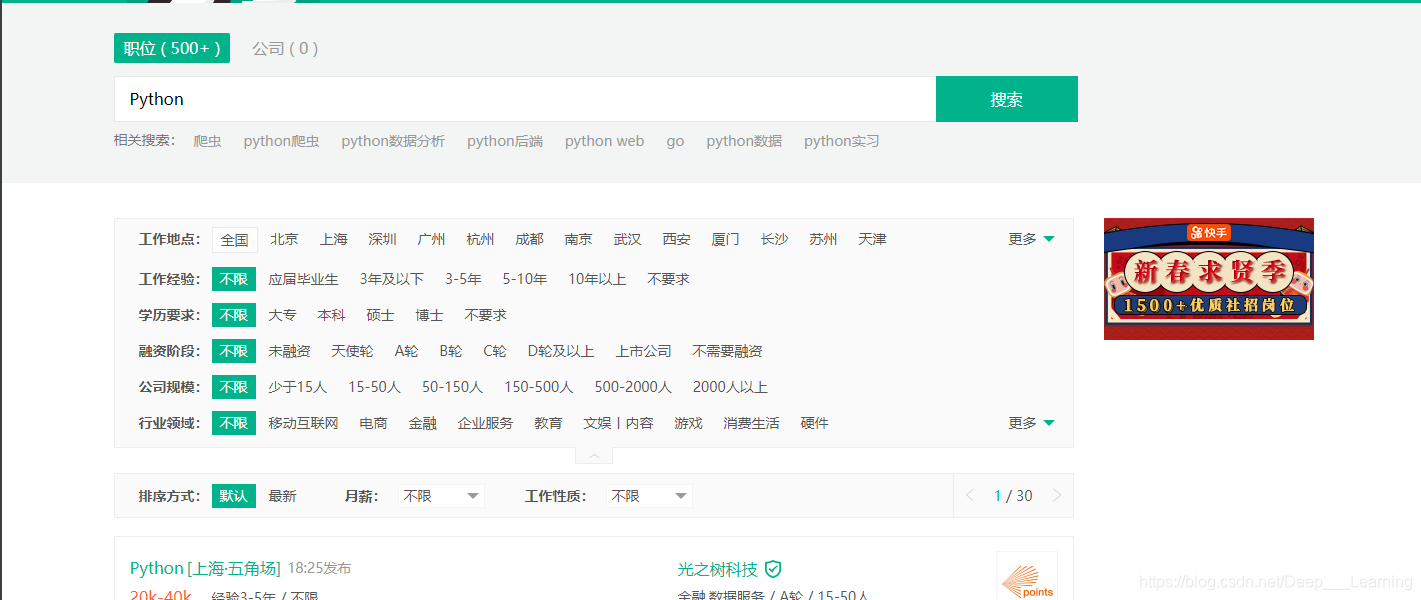
可以跳转到如上图所示的页面,我们要爬取的数据就是下面的职位信息
查看网页源代码,我们可以发现并没有我们想要的数据,由此可以判断数据通过其他的URL请求得到,下面进行抓包分析
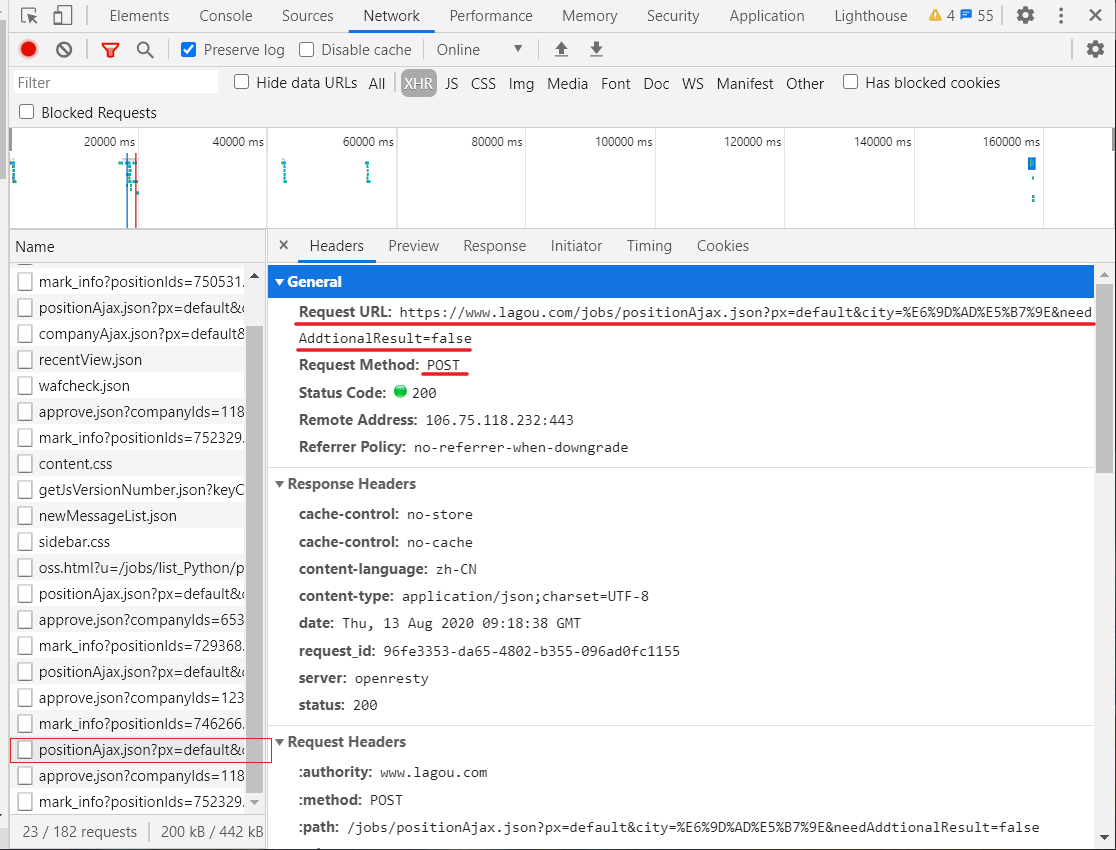
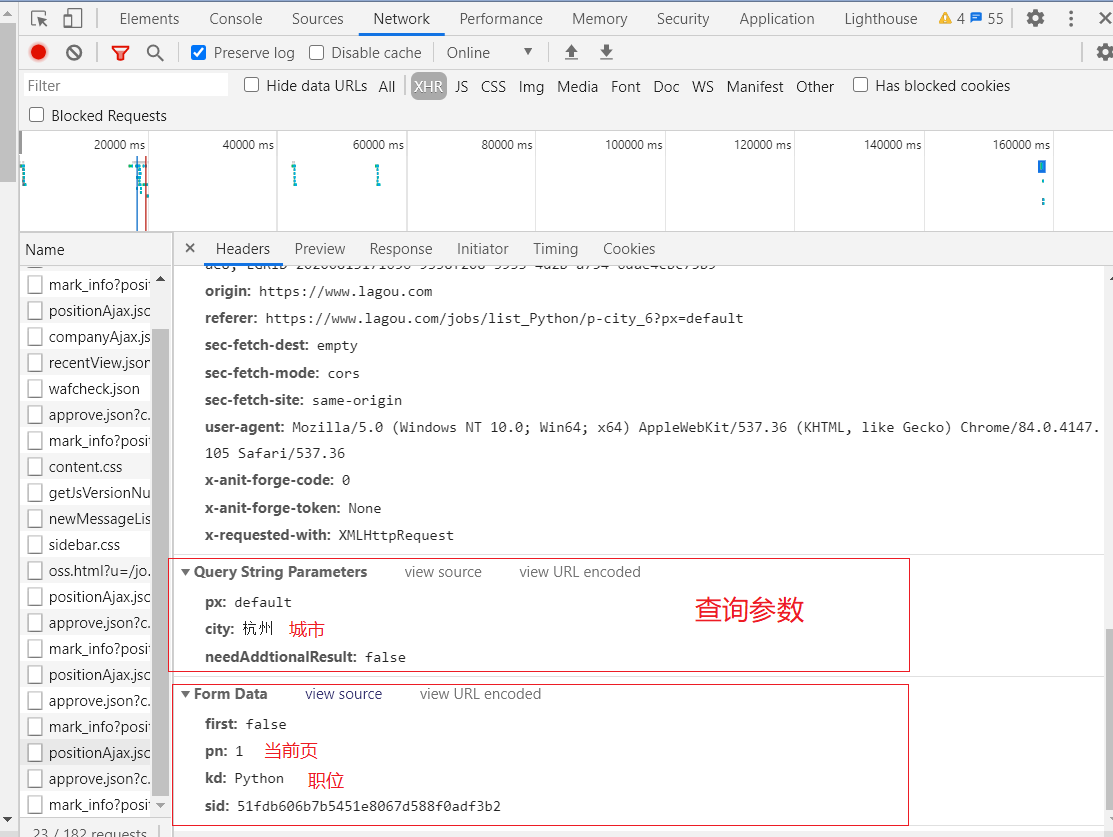
通过抓包,我们发现了请求的URL,请求方式为POST,但是,当我们直接用POST方式请求时,却不能获取到数据,直接给你返回“请求太频繁”(这个提示应该是假的),我尝试增加请求头中的信息,依旧没有用。后来,经过分析我知道了网站后台可能会判断你请求时的cookie,只有cookie正确,才给你返回信息,因此,我们的思路就很明确了,只要在请求之前拿到cookie,并且在请求时在加上cookie就行了。
核心思路:
为了能够拿到我们想要的职位信息,我们分两步走。 第一步,先用get的方式请求一开始的URL,即我们访问页面的URL,这一步的目的是为了能够得到cookie,为下一步请求做准备。 第一次请求的URL:https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput= 第二步,我们用第一步拿到的cookie来发送POST请求,请求的URL为: https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false
另外作为 POST 请求,在请求数据的时候,可以传递查询的参数和数据
具体实现
首先,我们可以用requests库中的session方法来创建一个session对象来存储cookie,然后再用这个cookie进行第二步中的请求即可。
代码
"""
拉勾网反爬机制分析:
通过两次请求来获取职位列表,
第一次请求原始页面获取cookie
第二次请求时利用第一次获取到的cookie
"""
import requests
# 第一次请求的URL
first_url = 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput='
# 第二次请求的URL
second_url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
# 伪装请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '25',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
# 创建一个session对象
session = requests.session()
# 请求的数据
data = {
'first': 'true',
'pn': '1',
'kd': 'Python'
}
session.get(first_url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
})
result = session.post(second_url, headers=headers, data=data, allow_redirects=False)
print(result.json())
分页爬取:
# -*- encoding: utf-8 -*-
import requests
import json
import jsonpath
import time
import pandas as pd
# 第一次请求的URL
first_url = 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput='
# 第二次请求的URL
second_url = 'https://www.lagou.com/jobs/positionAjax.json?'
# 伪装请求头
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '25',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.lagou.com',
'Origin': 'https://www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest'
}
# 创建一个session对象
session = requests.session()
session.get(first_url, headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.97 Safari/537.36'
})
# 可以自己改变城市
params = {
'px': 'default',
'city': '北京',
'needAddtionalResult': 'false'
}
page = 1
# 爬取 10 页
for i in range(10):
# 请求的数据
form_data = {
'first': 'false',
'pn': page,
'kd': 'python'
}
response = session.post(url=second_url
, headers=headers
, params=params
, data=form_data,
allow_redirects=False)
python_obj = json.loads(response.content)
result_list = jsonpath.jsonpath(python_obj, '$..result')[0]
for item in result_list:
po = dict()
po[u'positionName'] = item["positionName"]
po[u'city'] = item['city']
po[u'district'] = item['district']
po[u'skillLables'] = item['skillLables']
po[u'salary'] = item['salary']
po[u'jobNature'] = item['jobNature']
po[u'education'] = item['education']
po[u'companyFullName'] = item['companyFullName']
po[u'companySize'] = item['companySize']
po[u'createTime'] = item['createTime']
po = pd.DataFrame(po)
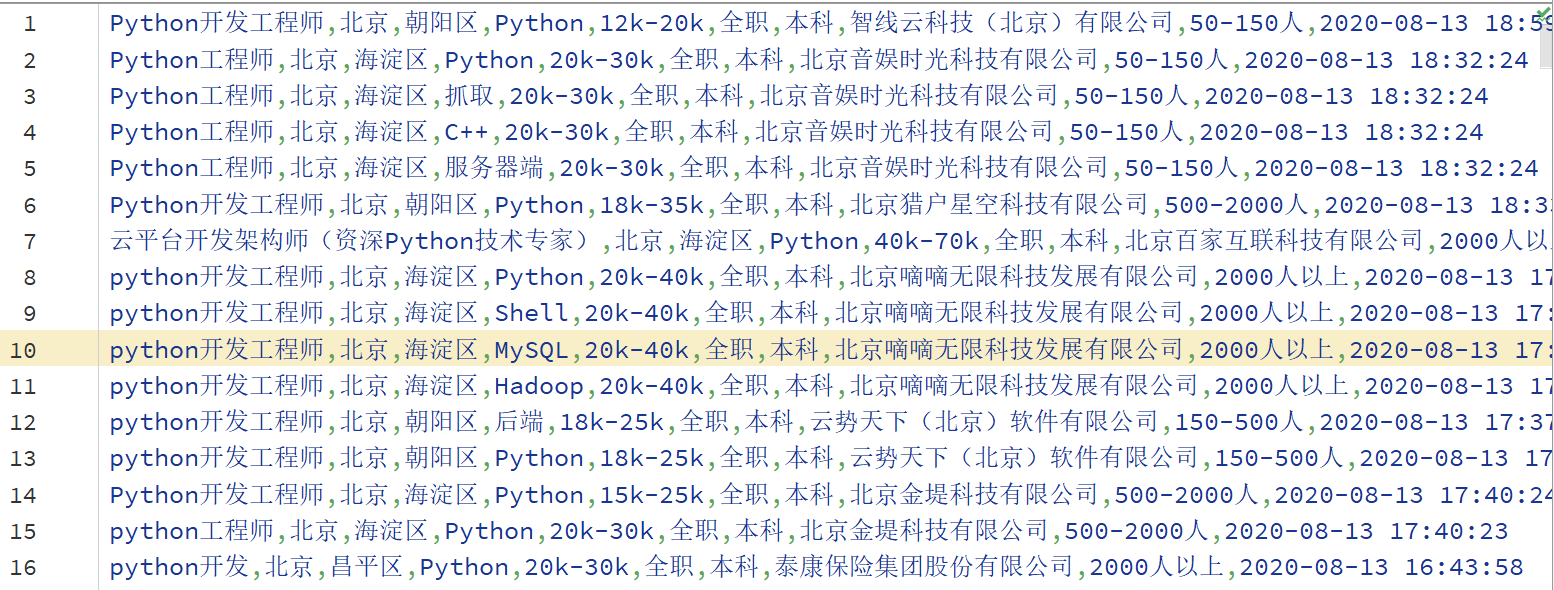
po.to_csv('LGW.csv', header=False, index=False, mode='a+')
page += 1
time.sleep(4)
参考