B站弹幕爬取
主要的流程:
- 根据 BV(或av) 号获取 cid。
- 根据 cid 请求弹幕。
找到要爬取的视频,检查网页源代码:
找到如图所示的文件:可以获取到 视频的 cid
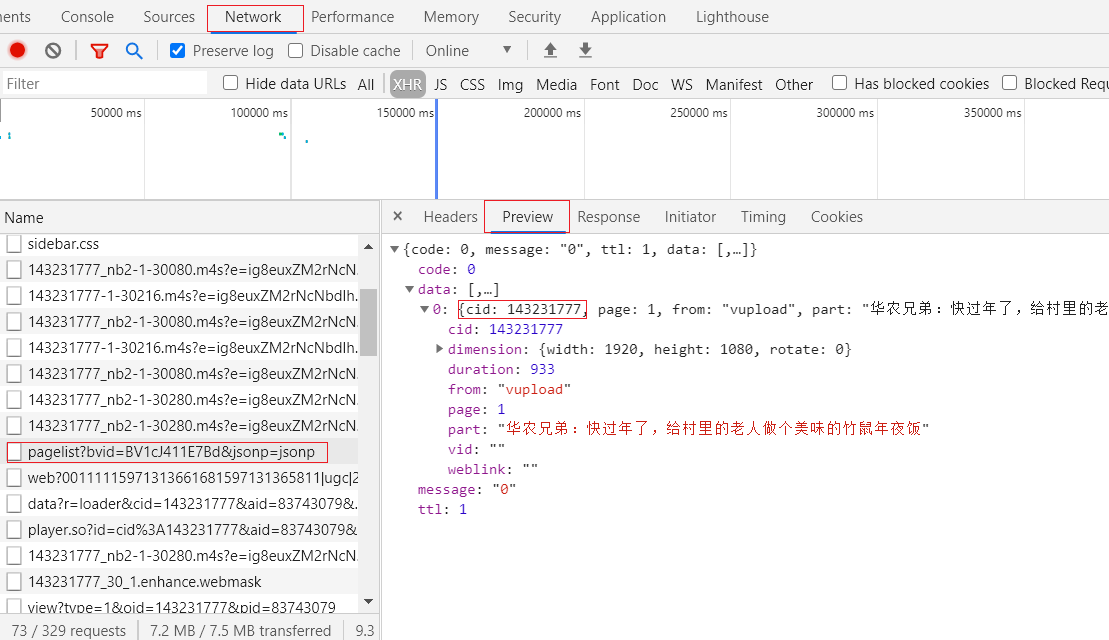
或者:
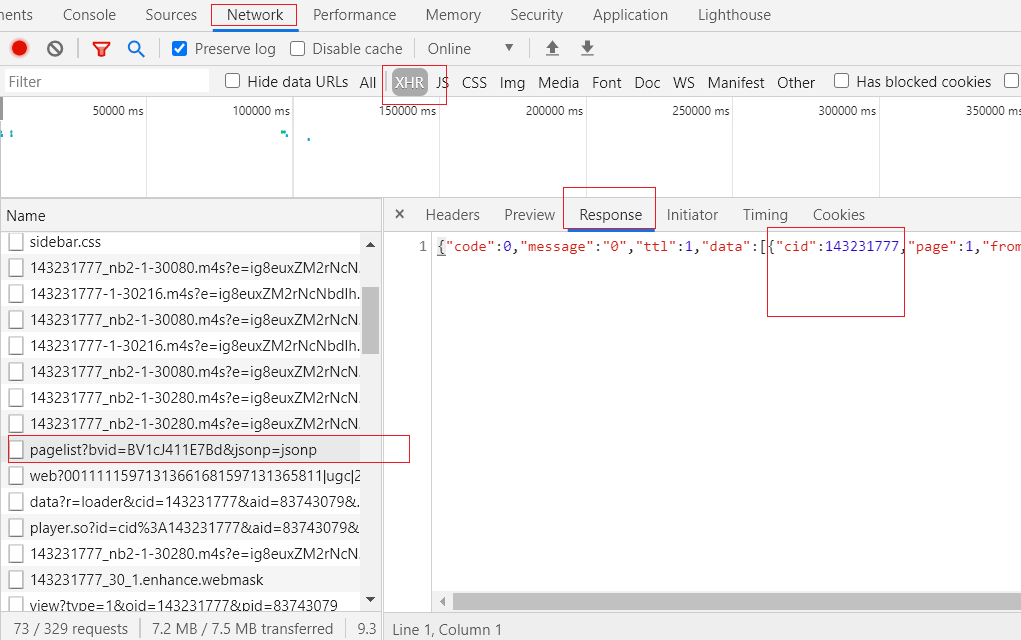
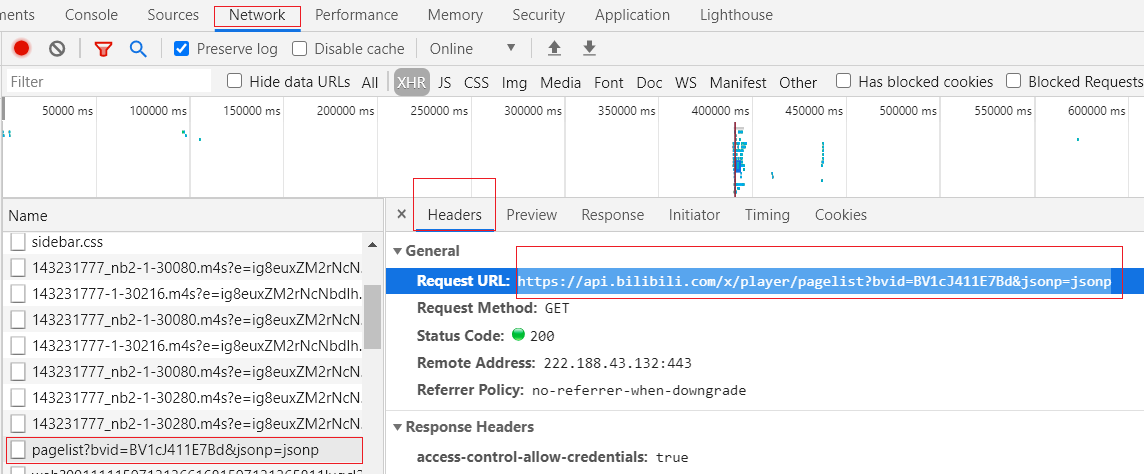
我们通过上面文件的 Request URL URL: 来发送请求获取相关的参数:
import requests
import re
import chardet
url ='https://api.bilibili.com/x/player/pagelist?bvid=BV1cJ411E7Bd&jsonp=jsonp'
page = requests.get(url)
page.text
结果:

获取视频的 cid
cid = re.findall(r'"cid":(\d+)',page.text)[0]
# '143231777'
根据 cid 请求弹幕文件
这部分内容是参考别人的,可能是b站把这个文件给改掉了,找不到这个文件了,但是这个接口还是可以用的
bilibili的弹幕是在xml文件里,每个视频都有其对应的 cid 和 aid,我们取到 cid 中的数字放入http://comment.bilibili.com/+cid+.xml,即可得到该视频对应的cid。
比如:打开这个链接http://comment.bilibili.com/143231777.xml,就可以看到:
之前查找请求弹幕 url 的方式:
首先找到网页请求弹幕的 url
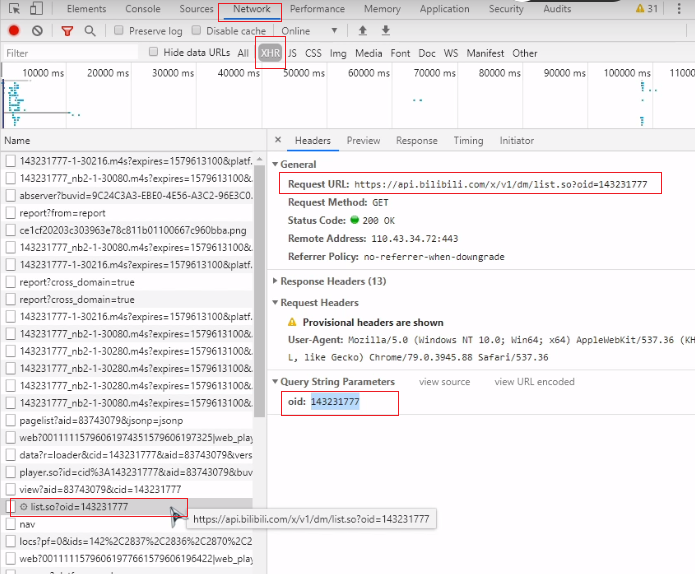
有了接口和 cid 后我们就可以发送请求,获取弹幕的 xml 文件。
dm_base_url = 'http://comment.bilibili.com/{}.xml'
dm_url = dm_base_url.format(cid)
dm_url
# http://comment.bilibili.com/143231777.xml
将上面的 url 复制到浏览器可以看到弹幕文件:
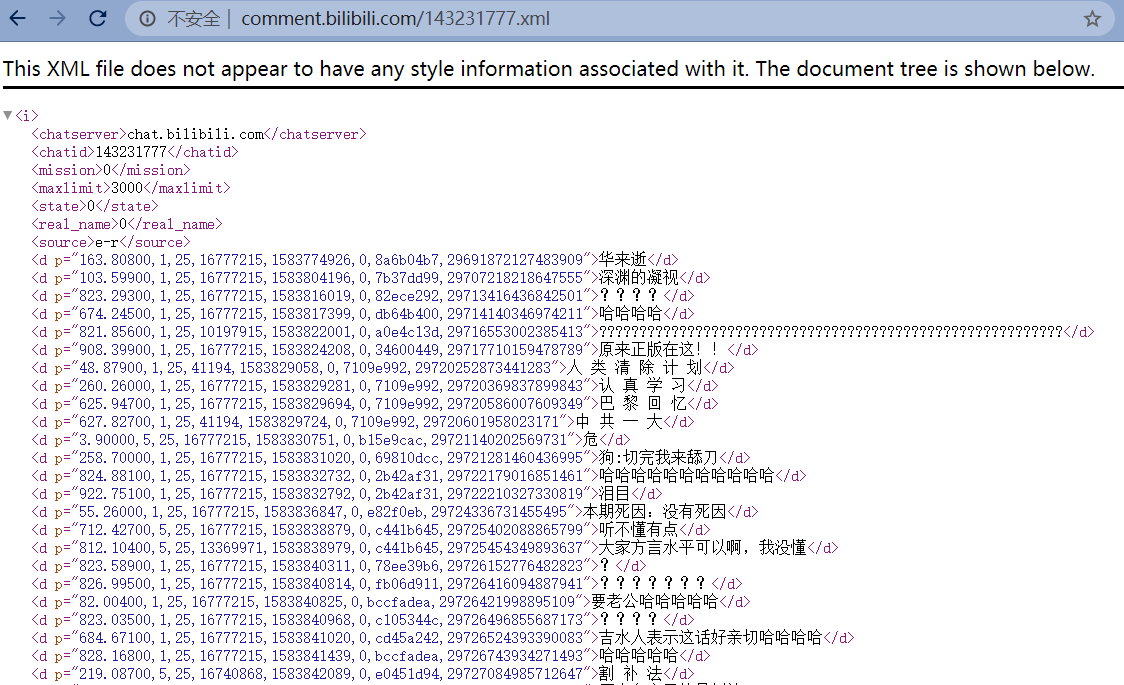
请求弹幕文件:
# 请求网页数据
dm_page = requests.get(dm_url)
# 将获取的文件进行解码
code = chardet.detect(dm_page.content)['encoding']
# 'utf-8'
dm=dm_page.content.decode(code)

提取弹幕
根据弹幕在浏览器中的显示我们可以看到,弹幕内容位于 d 标签内部。利用正则表达式来提取弹幕内容。
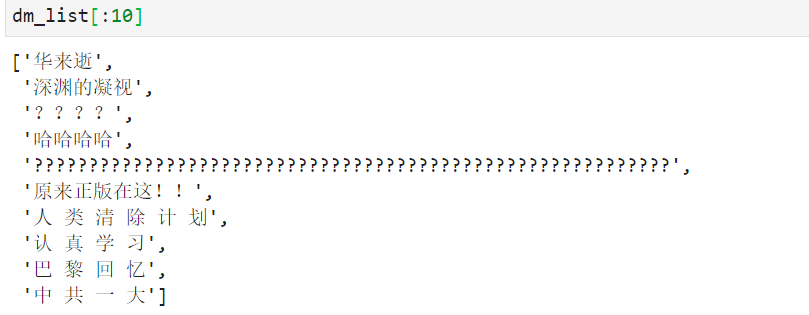
dm_list = re.findall(r'<d .*?>(.*?)</d>',dm)
dm_list[:10]
这个文件总的弹幕数:
len(dm_list)
# 3000
这里只是获取了 3000 条弹幕。
如何获取全部(历史)弹幕呢?
当一个视频都几个部分,如何获取弹幕呢?
获取历史弹幕需要登录用户账号
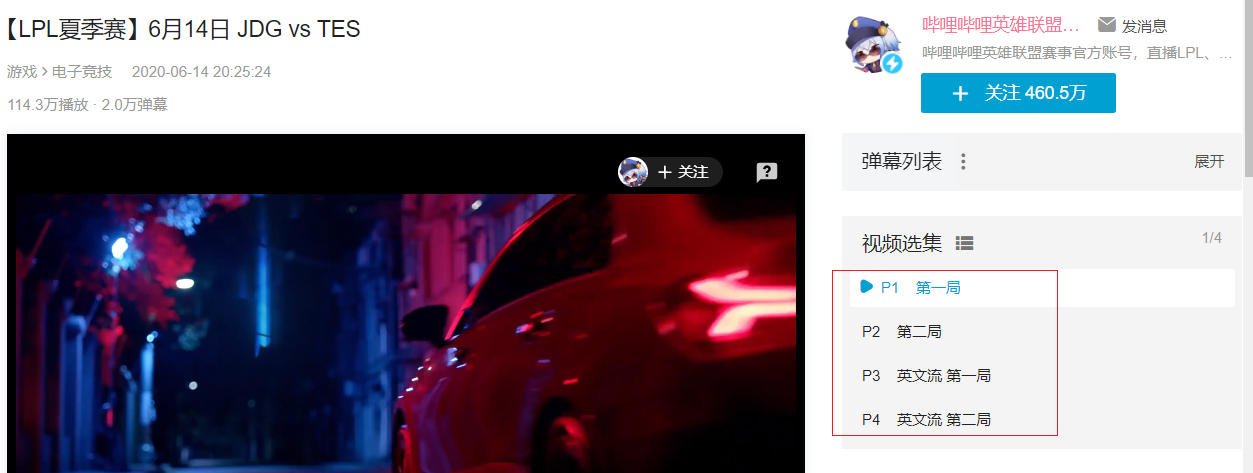
可以看到上面的视频包含 4 P,根据上面方式我们查看网页源代码,找相应的文件:
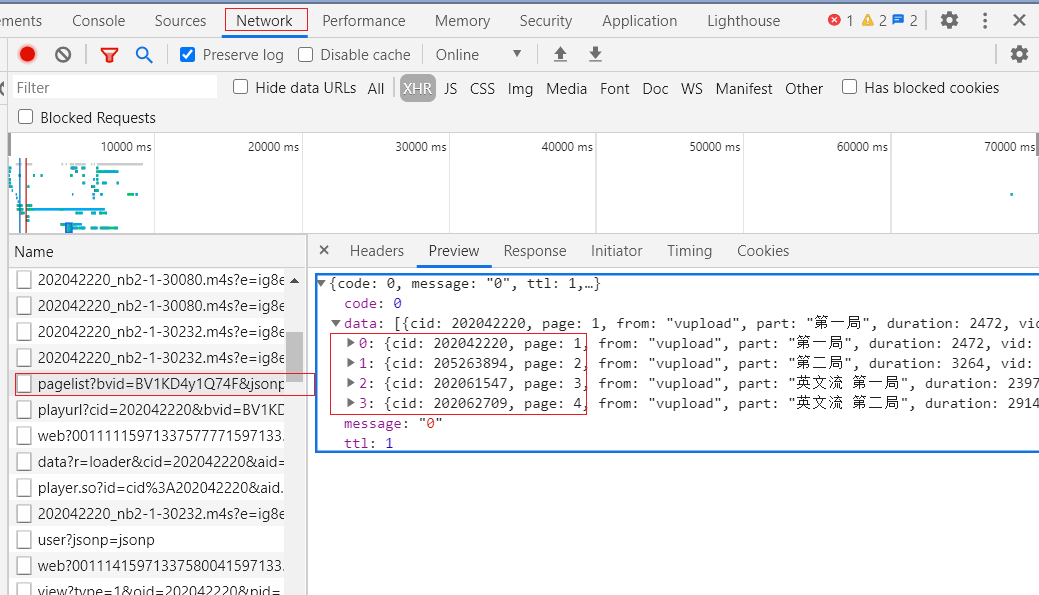
可以看到这四个视频分别对应四个 cid 。
根据不同的 cid 我们就可以获取不同视频对应的弹幕了。
默认爬取的是最近的 3000 条。但是如何获取历史弹幕呢?
查网页源代码
点击一个左边的一个日期:
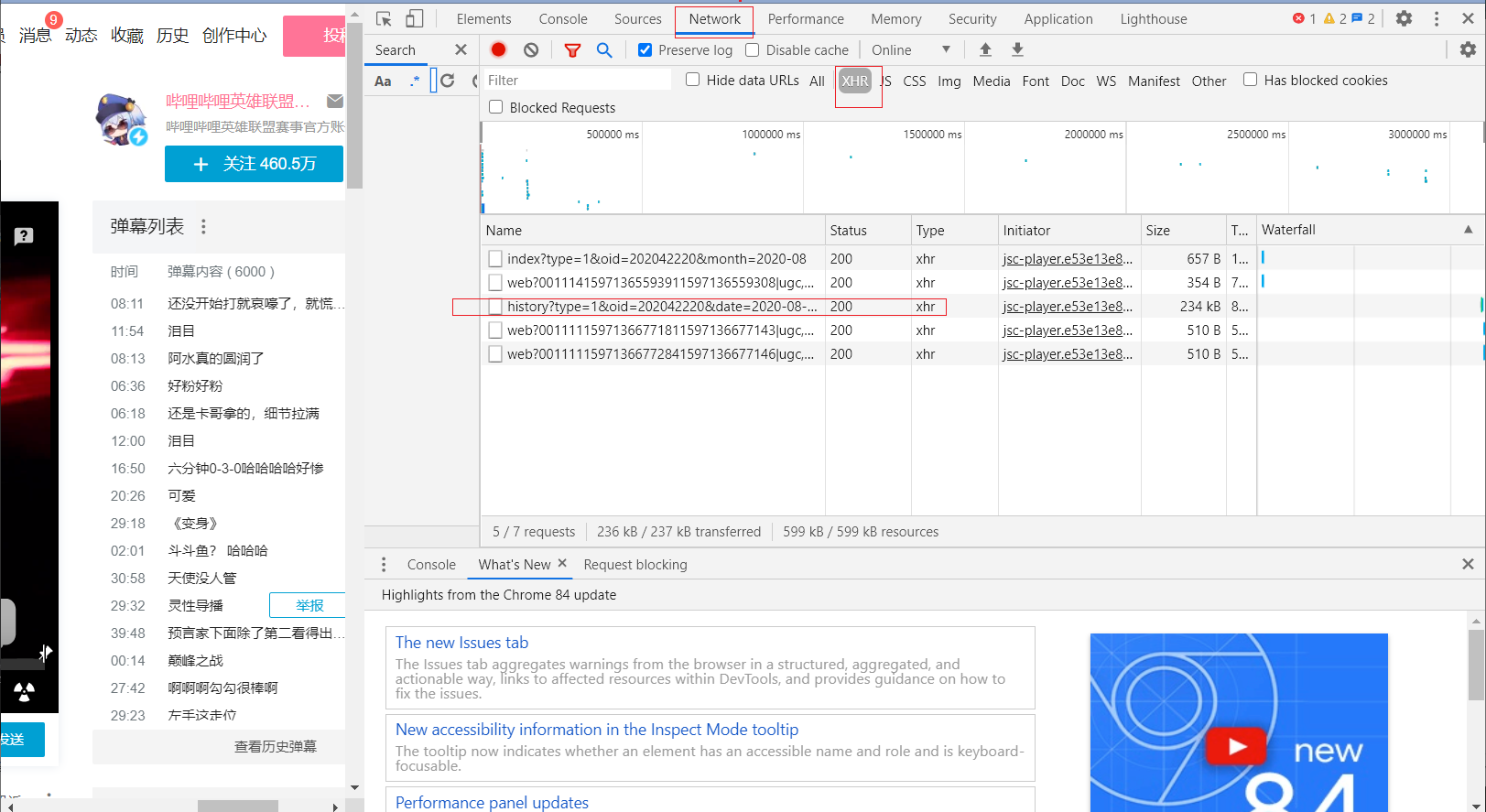
可以看到新加载一个  的文件。
的文件。
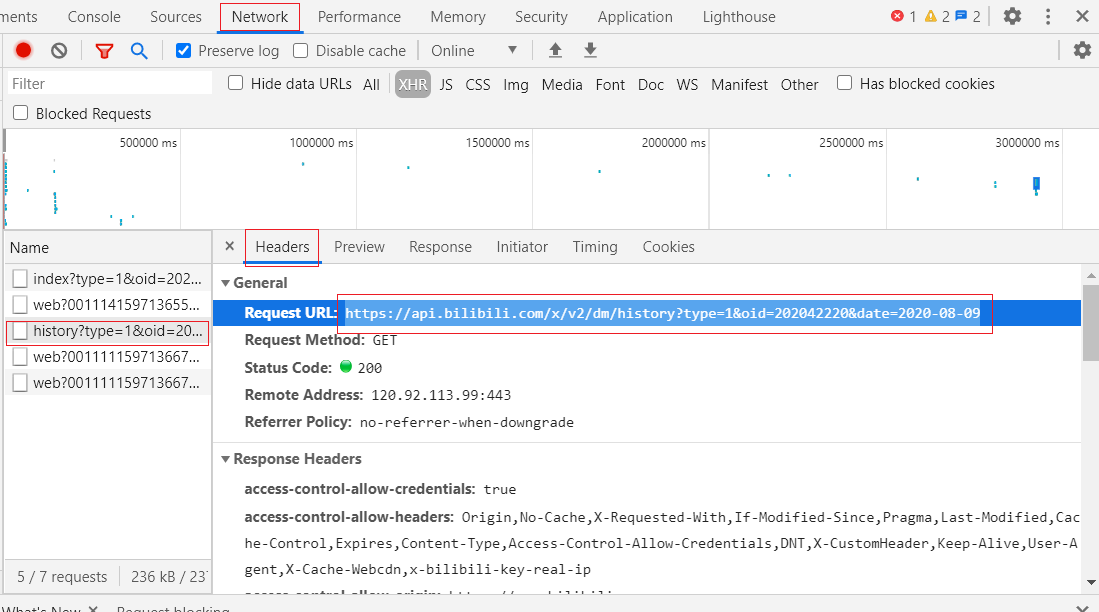
点击这文件 ,复制 Request URL 到浏览器:https://api.bilibili.com/x/v2/dm/history?type=1&oid=202042220&date=2020-08-09
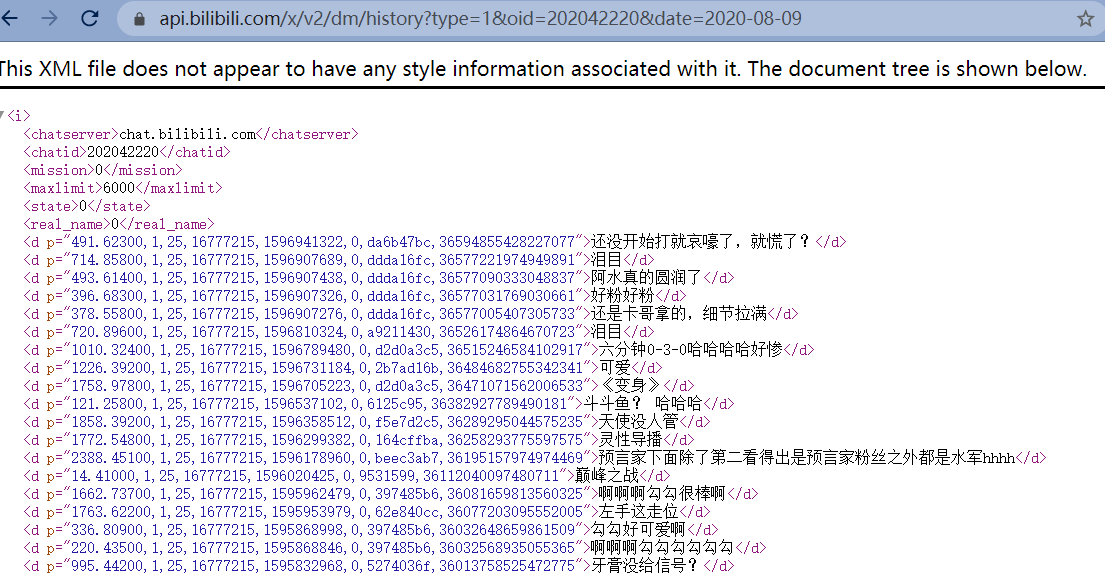
可以看到是存储弹幕的 xml 文件。当前文件有 6000 条弹幕。
分析这个 url :https://api.bilibili.com/x/v2/dm/history?type=1&oid=202042220&date=2020-08-09
后面主要有两个参数:cid(oid) 和 date ; 通过调整后面的日期我们就可以获取当前视频不同时间的弹幕。
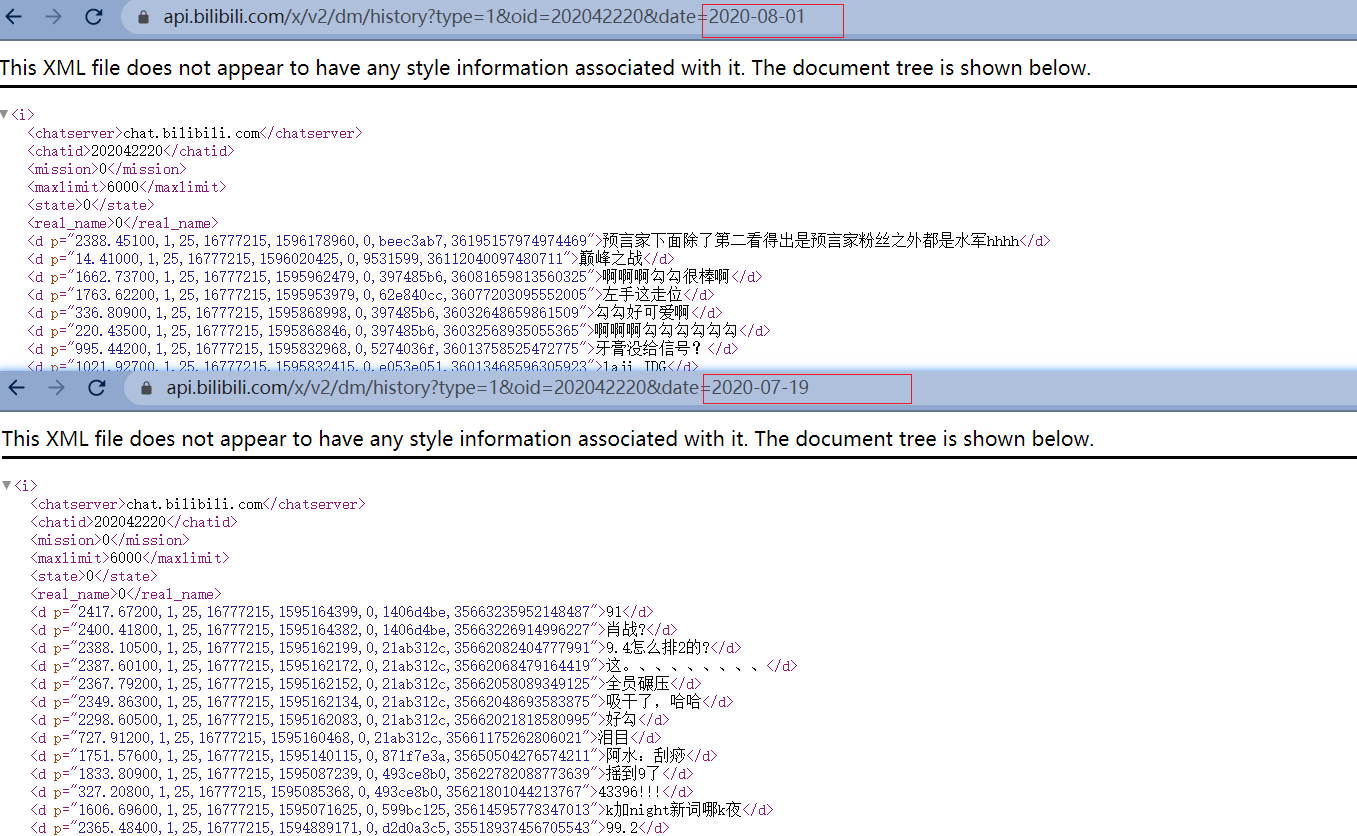
可以看到不同时间的弹幕是有重复的
对于重的 可以通过 p 标签的内容进行过滤。
也可以根据请求到的数据获取含有弹幕的日期:
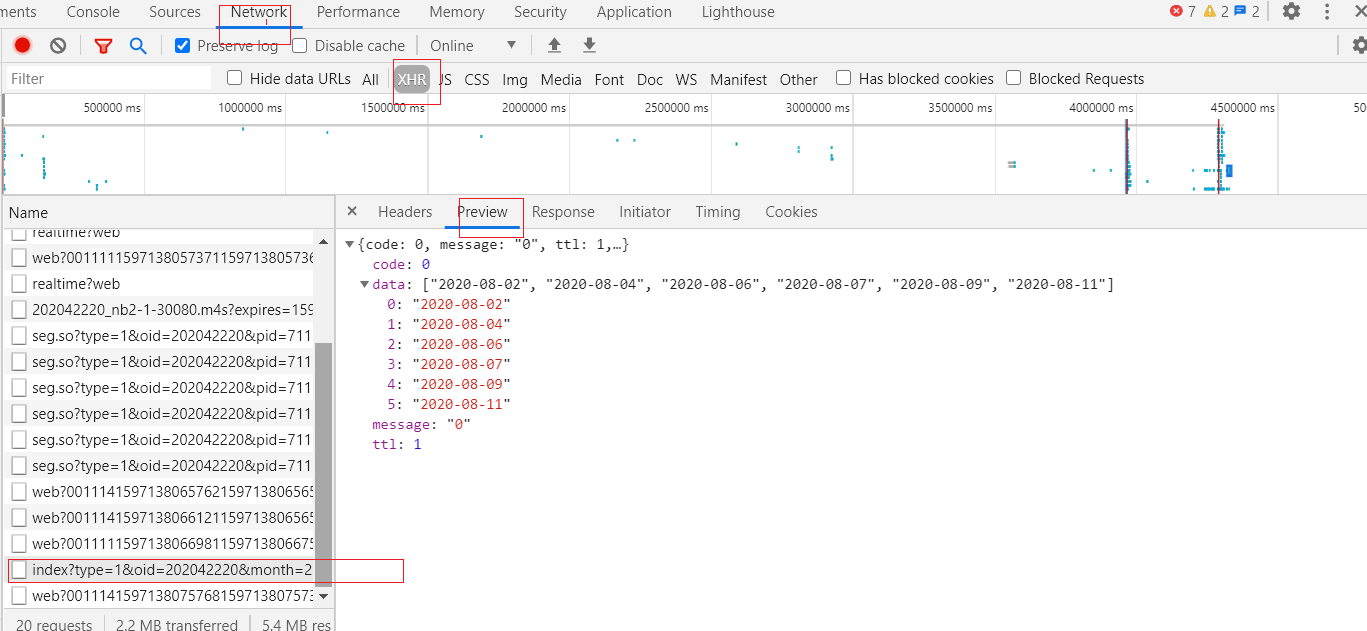
这个文件会返回一个日期列表:当前月份几号是有弹幕的。例如:https://api.bilibili.com/x/v2/dm/history/index?type=1&oid=202042220&month=2020-08
表示今年 8 月份。将上面的 url 复制到浏览器:

可以看到这些天数是有弹幕的,改变月份:
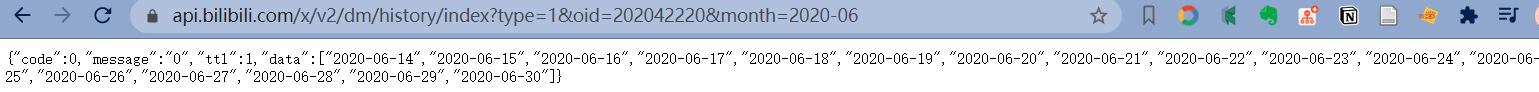
但是利用获取到的日期去查询弹幕,好像也不能解决后面时间段,不同文件含有弹幕重复的问题。
一种解决方法就是根据弹幕文件中的 p 标签的内容进行过滤:
可以百度 B 站 弹幕文件参数