爬取网易云音乐评论
网站分析
右键检查网页,可以看到
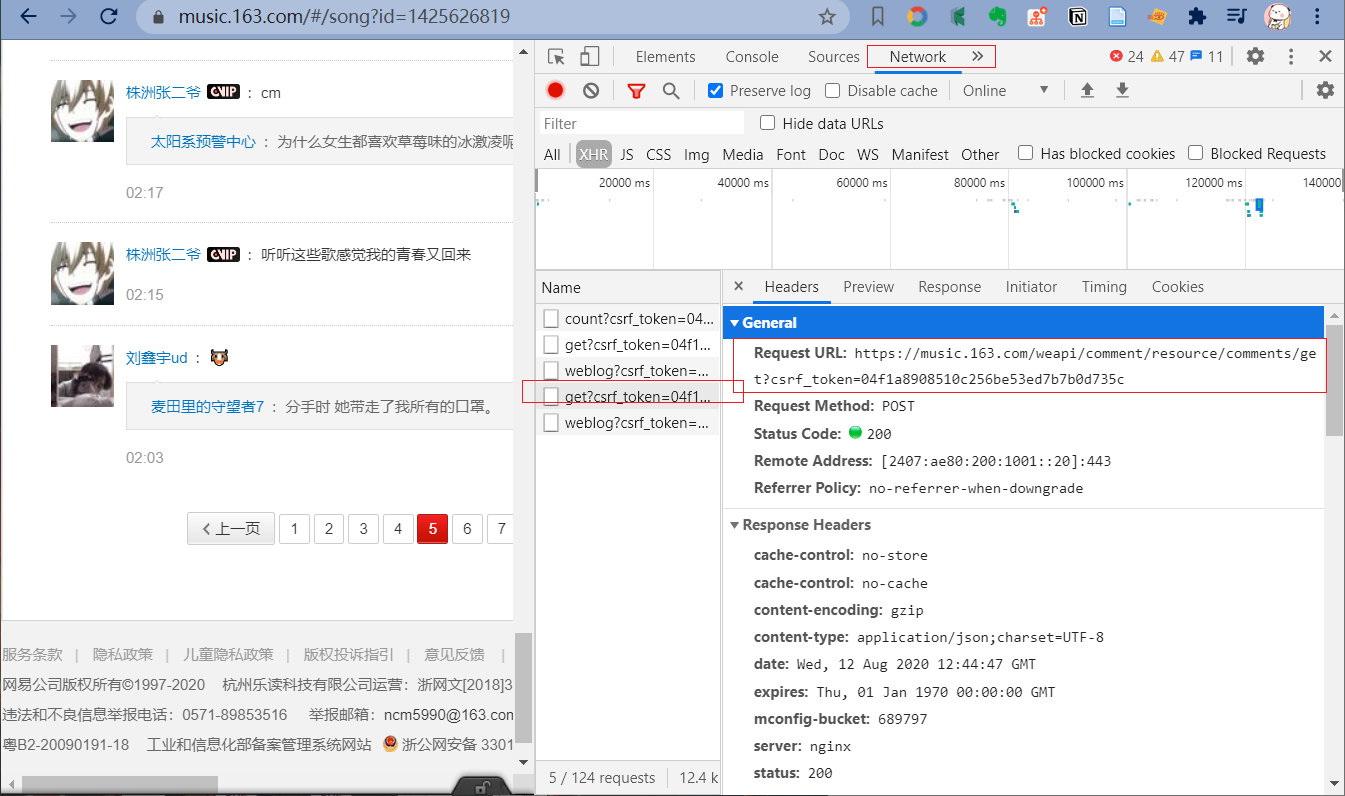
发送的是 post 请求;
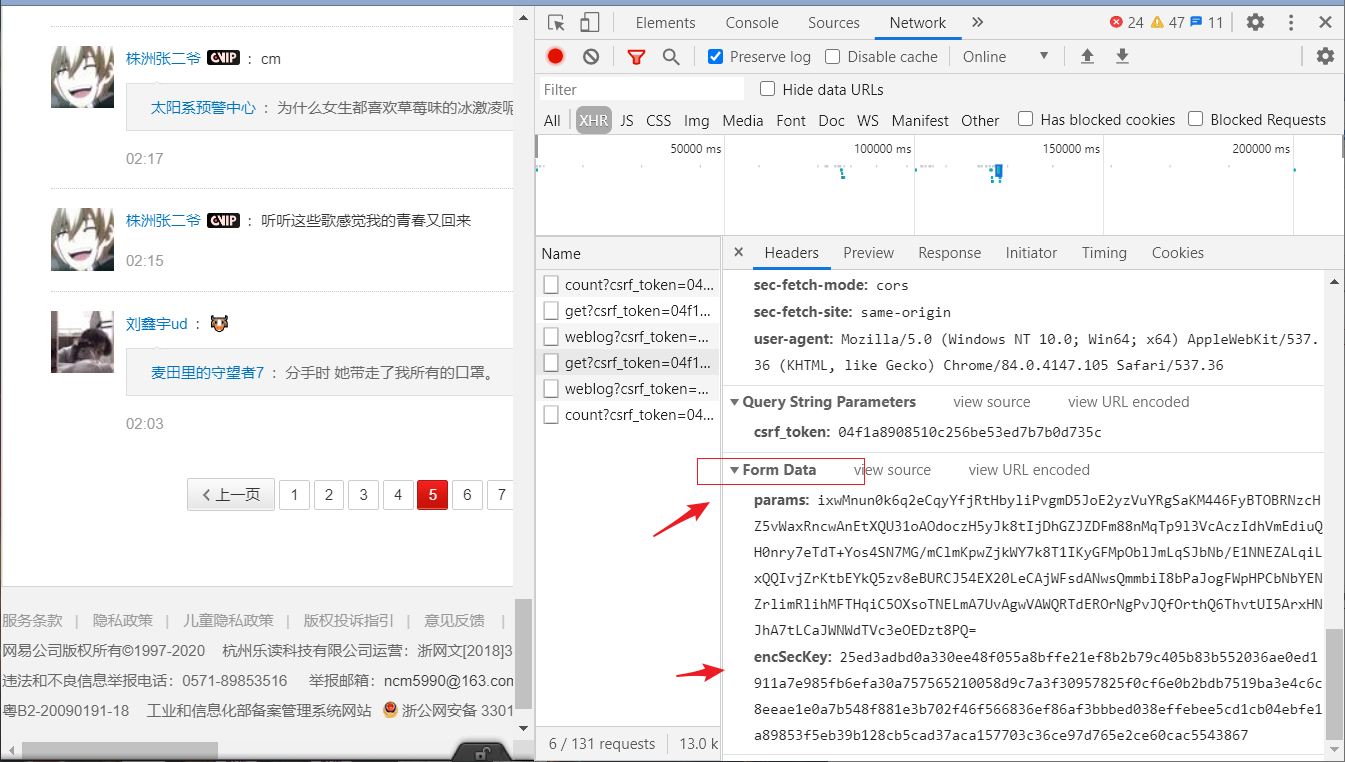
所传递的参数是经过加密的。
当进行翻页的时候
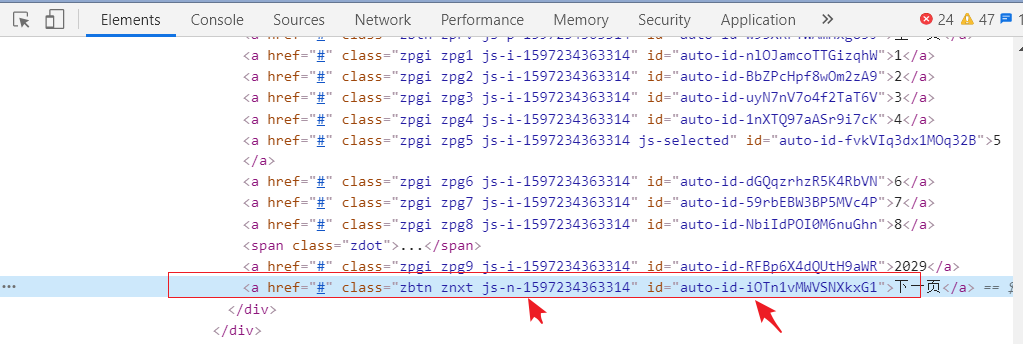
下一页的标签的 class 和 id 每次刷新的时候是会发生变化的。模拟浏览器的点击进行翻页爬取不太可取。
解决方案:利用 api 接口:
API 集合
简单介绍一下它们:
评论
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit=20&offset=0
这应该是最最最常见的了,毕竟80%的网易云音乐的爬虫/数据分析文章都是关于评论数据~
使用技巧:
limit:返回数据条数(每页获取的数量),默认为20,可以自行更改offset:偏移量(翻页),offset需要是limit的倍数type:搜索的类型
举例,比如limit设置为10,则第一页,第二页分别为:
http://music.163.com/api/v1/resource/comments/R_SO_4_483671599?limit=10&offset=0
http://music.163.com/api/v1/resource/comments/R_SO_4_483671599?limit=10&offset=10
PS:返回的数据格式为 json,需要注意的是通过此接口获取的评论数量最多2万条。
歌单
https://music.163.com/api/playlist/detail?id={歌单ID}
网易云音乐每日推荐各种神奇歌单也是它的一大特色,我们可以利用这个api获取歌单里的所有歌曲信息。
https://music.163.com/api/playlist/detail?id=2557908184
同时歌单api还可以应用于各种榜单上,例如:
id=19723756,云音乐飙升榜
id=3779629,云音乐新歌榜
id=3778678,云音乐热歌榜
id=2250011882,抖音排行榜
具体id可以按需求自己查找。
歌曲下载
外链:
https://link.hhtjim.com/163/{歌曲ID}.mp3
用户信息
https://music.163.com/api/v1/user/detail/{用户ID}
大家在获取到了评论之后,也会同时得到该条评论的用户id。
那么利用他的id和这个用户信息api来获取用户的信息。
汇总之后,我们就可以得到一个歌手在网易云的粉丝用户画像。
歌词
https://music.163.com/api/song/lyric?id={歌曲ID}&lv=1&kv=1&tv=-1
歌词用来做什么呢?
随便举例几个标题:
《周杰伦14张专辑歌词,里面是19年的岁月》
《华语歌坛30年,大家都在唱些什么?》
搜索结果
http://music.163.com/api/search/get/web?csrf_token=hlpretag=&hlposttag=&s={搜索内容}&type=1&offset=0&total=true&limit=20
使用技巧:
limit:返回数据条数(每页获取的数量),默认为20,可以自行更改
offset:偏移量(翻页),offset需要是limit的倍数
type:搜索的类型
type=1 单曲
type=10 专辑
type=100 歌手
type=1000 歌单
type=1002 用户
type=1004 MV
type=1006 歌词
type=1009 主播电台
其它
最后推荐一些冷门的接口:
歌手专辑
http://music.163.com/api/artist/albums/{歌手ID}?id={歌手ID}&offset=0&total=true&limit=10
专辑信息
http://music.163.com/api/album/{专辑ID}?ext=true&id={专辑ID}&offset=0&total=true&limit=10
歌曲信息
http://music.163.com/api/song/detail/?id={歌曲ID}&ids=%5B{歌曲ID}%5D
MV
http://music.163.com/api/mv/detail?id={MV的ID}&type=mp4
测试抓取评论
import pandas as pd
import requests
import json
import time
song_id = 1425626819
offset = ''
headers = {
'content-type': 'application/x-www-form-urlencoded',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'cookie': '_iuqxldmzr_=32; _ntes_nnid=1b13c21d3407623f34a2b5cfc6f5fcba,1569725214357; _ntes_nuid=1b13c21d3407623f34a2b5cfc6f5fcba; WM_TID=DpS97TOR3gFBRRUBAUJ5pmrJrNwUZA8r; mail_psc_fingerprint=8bb6306983fdc5e6fa2e5c561ac169eb; usertrack=ezq0ZV3IzClwXAVSGNFXAg==; _ga=GA1.2.208351822.1573440559; P_INFO=hugg20171226@163.com|1594624326|0|mail163|00&99|jis&1594622860&mail163#jis&320100#10#0#0|&0|mail163_qrcode&mailmasterpro|hugg20171226@163.com; _antanalysis_s_id=1597020289916; playerid=46996488; JSESSIONID-WYYY=Mc68a9vEj1SCScO8P5YG%2BCiFzkdeE877wZIMk3Fq2FbhFfxaR81TuoeQbUmU%2FHpOQMEoYECEbynlYfPwc1iwFac3uCJFJX5Czwq60TZN3rEVfKYokuvDx1R6UWM7pBckqjqmMHHhX7dxNgORFOziOeTKNMOHjoFsYV7e3%2FEHRyBA7YYX%3A1597234685255; WM_NI=o6ItRe8GXmBTCymtZL1cklzEOOnUDNjObyRlUwHaDrSSTlP9HBf0lCDqrwFA1R2nVCz54LQl4%2FEeWEn1iJQYxxV0ziQuTdVXanG8Qcu5%2BPQB0WM00RcnWMhOAnCIAlKqZEs%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eeafee74af91aaabae53b0968fb2d15b828a9a84b54db3b8acadb67bb090bedad52af0fea7c3b92aadea8795d16ffc99988ec16081a7a395d948f3bda58df94f8d91a2b6c746aa91ae9ad16897a98882c77a918d9c8dd3338c9eaad1ef4988afbe98c54bf38efe8fd549baebfcadd468f8f18b86d64faeefa7abd453bca89ad1f96393ab9c85d554a3b289d9d469b7ebe5b1d44af48983d1b35aa1b299aeeb4583b28daac46889af96a6f237e2a3; MUSIC_U=dec0269e7e4782a307d0d827a242f6d08afbbb3220811feaddbf82666042164a33a649814e309366; __csrf=04f1a8908510c256be53ed7b7b0d735c; ntes_kaola_ad=1'
}
for offset in range(200):
# 关键 url
url = f'http://music.163.com/api/v1/resource/comments/R_SO_4_{song_id}?limit=20&offset={offset * 20}'
print(url)
html = requests.post(url, headers=headers)
# print(html.text)
j = json.loads(html.text)
# print(j.keys())
for num in range(len(j['comments'])):
# num 第几条评论
comment = [(j['comments'][num]['user']['nickname']
, j['comments'][num]['content']
, j['comments'][num]['likedCount']
, j['comments'][num]['time']
)]
comment = pd.DataFrame(comment)
comment.to_csv('wyyl.csv', header=False, index=False, mode='a+')
time.sleep(2)
print('page ' + str(1 + offset) + " has done")
结果:

参考