爬取淘宝商品评论
流程
这里,我们以一个随机商品为例,流程如下:
- 根据商品详情页链接获取真实的评论请求url
- 请求评论 url,接收响应
- 解析数据,获取评论总数和评论数据
- 存储数据到本地
- 根据评论总数构造循环翻页
淘宝的评论是通过 JS 动态渲染出来的,并没有在初始请求的网页源码中,所以我们要找到发送新请求的 url,这个并不难找。
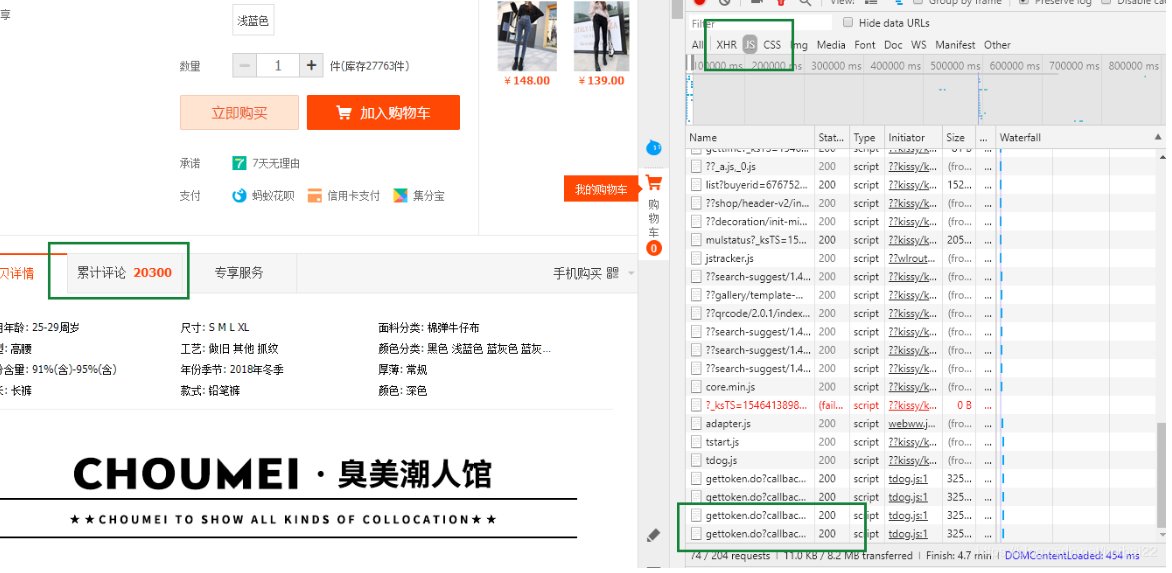
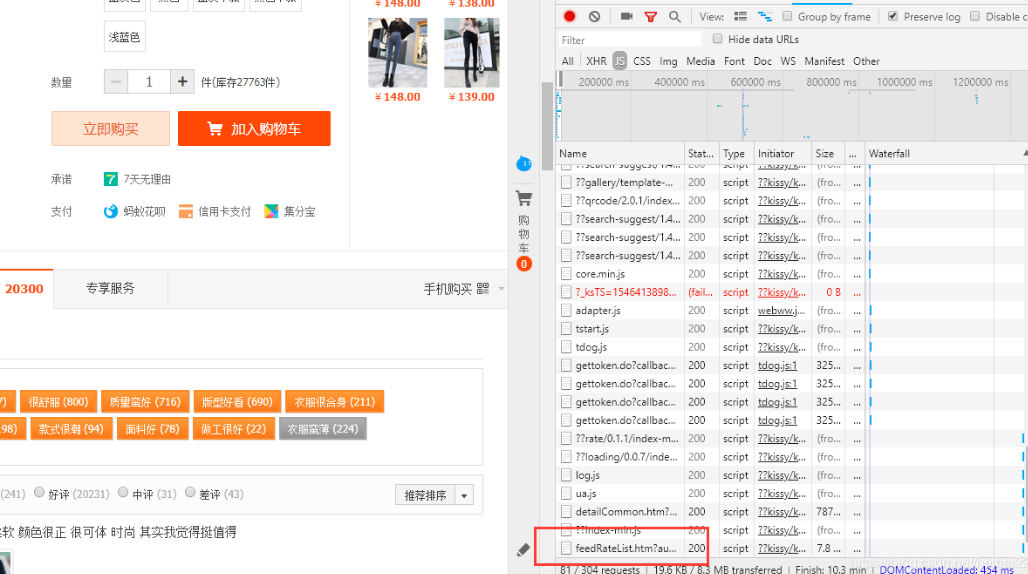
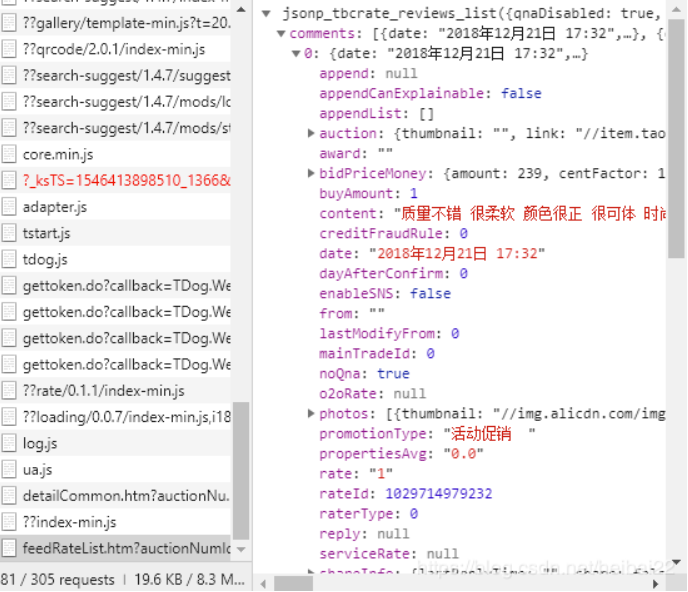
右键 f12 进入检查,此时没有发送评论请求,评论并没有加载;当点击网页的评论按钮时,有新的请求被发送了,“feedRateList”开头的新请求就是我们要找的。从preview中可以看出,这是一个json,里面包含了评论和其它的数据。这里可以把整个json拿出来,但里面有很多其它keys,很多我并不知道含义,所以我只提取了自己感兴趣的数据。
分析完毕,开始爬虫:
获取评论的 url:
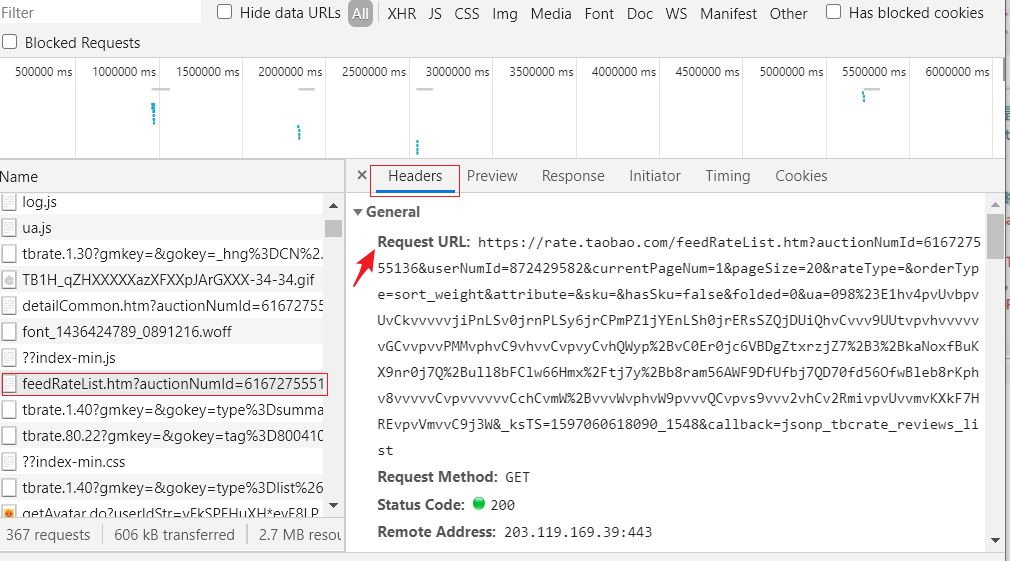
我们只需要获取 Request URL 的前面一部分。
页面的 url
https://rate.taobao.com/feedRateList.htm?
问号后面的部分,我们可以作为参数进行传递;
params = {
'auctionNumId': 616727555136, #商品的 DI
'currentPageNum': 1 # 评论的页数,通过改变这个参数值,我们可以获取多页的评论
}
设置 请求头:
headers = {
# 从哪个页面发出的数据申请,每个网站可能略有不同
'referer':'https://item.taobao.com/item.htm?id=616727555136&ali_trackid=2:mm_12238993_43806065_714972723:1597052770_255_1467045357&spm=a231o.7712113%2Fg.1004.35&pvid=200_11.27.93.104_284878_1597052761050&bxsign=tbk159705277066145c815046b62c30a7b16b4c95524bc36',
# 用的哪个浏览器
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
# 用户的账号、密码等信息,主要用来反爬虫,用户登录后可以获取自己的cookie数据
'cookie':"cna=b/D8FYOTMVUCATrwJ8wV3AAV; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; miid=1525554089483641014; tracknick=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; tg=0; _samesite_flag_=true; cookie2=1b33c97adb02c7a77f9b89cfd5b171c4; t=0189b94436cd684bd44103b442e690f0; _tb_token_=38113a95557b8; v=0; UM_distinctid=173d7c2723922c-03c43fa2475c66-3323765-144000-173d7c2723a615; sgcookie=E2HGXmd4MlsLL6HyGk0KJ; uc3=vt3=F8dBxG2m6DG9ZRDBCCM%3D&id2=UUjXbEBZkN7mJw%3D%3D&lg2=Vq8l%2BKCLz3%2F65A%3D%3D&nk2=1TxKfiqLL2jq2i9bmfnbrTmayVA%3D; csg=84f3fcd6; lgc=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; dnk=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; skt=dfc81f3d58f5b26e; existShop=MTU5NzA1MjczMQ%3D%3D; uc4=id4=0%40U2o1ZOW2sQbQakAQ5T12awSrkm3p&nk4=0%401%2BCc9B0f4Q5M%2F%2BMtI%2FU07r71QIM2V4fqLr0KgI3bXg%3D%3D; _cc_=W5iHLLyFfA%3D%3D; lLtC1_=1; enc=4tzEh0tXDSIEBX1SFap7WowBYIv7XkkJzvG9nbq9RshD9LloBqEnF9xLJhJiDTYADhWncQtfr4F5XQH1KsK%2FGQ%3D%3D; mt=ci=-1_0; uc1=cookie14=UoTV6ymGDU%2BQ%2FQ%3D%3D&pas=0&existShop=false&cookie21=W5iHLLyFeYZ1WM9hVnmS&cookie15=URm48syIIVrSKA%3D%3D&cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D; tfstk=cX-VBuGytmn4JcjsJisacWBGduEAatCGOuWFoehGk99TM-IVTsq_6TcYHTWN90bc.; l=eBSQWiJnqBSbB8NFBO5Zourza77tBIRb8sPzaNbMiInca6tP6UIYhNQqlbfkJdtjgtfAoeKPT3lYXREJ8c4LRETjGO0qOC0eQxv9-; isg=BFhY8mH9swr4n50_CEdVCJGAKYbqQbzL7c1_CJJJURNkLfkXO1AXW6NLZWUdPXSjcna=b/D8FYOTMVUCATrwJ8wV3AAV; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; miid=1525554089483641014; tracknick=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; tg=0; _samesite_flag_=true; cookie2=1b33c97adb02c7a77f9b89cfd5b171c4; t=0189b94436cd684bd44103b442e690f0; _tb_token_=38113a95557b8; v=0; UM_distinctid=173d7c2723922c-03c43fa2475c66-3323765-144000-173d7c2723a615; sgcookie=E2HGXmd4MlsLL6HyGk0KJ; uc3=vt3=F8dBxG2m6DG9ZRDBCCM%3D&id2=UUjXbEBZkN7mJw%3D%3D&lg2=Vq8l%2BKCLz3%2F65A%3D%3D&nk2=1TxKfiqLL2jq2i9bmfnbrTmayVA%3D; csg=84f3fcd6; lgc=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; dnk=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; skt=dfc81f3d58f5b26e; existShop=MTU5NzA1MjczMQ%3D%3D; uc4=id4=0%40U2o1ZOW2sQbQakAQ5T12awSrkm3p&nk4=0%401%2BCc9B0f4Q5M%2F%2BMtI%2FU07r71QIM2V4fqLr0KgI3bXg%3D%3D; _cc_=W5iHLLyFfA%3D%3D; lLtC1_=1; enc=4tzEh0tXDSIEBX1SFap7WowBYIv7XkkJzvG9nbq9RshD9LloBqEnF9xLJhJiDTYADhWncQtfr4F5XQH1KsK%2FGQ%3D%3D; mt=ci=-1_0; uc1=cookie14=UoTV6ymGDU%2BQ%2FQ%3D%3D&pas=0&existShop=false&cookie21=W5iHLLyFeYZ1WM9hVnmS&cookie15=URm48syIIVrSKA%3D%3D&cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D; tfstk=cX-VBuGytmn4JcjsJisacWBGduEAatCGOuWFoehGk99TM-IVTsq_6TcYHTWN90bc.; l=eBSQWiJnqBSbB8NFBO5Zourza77tBIRb8sPzaNbMiInca6tP6UIYhNQqlbfkJdtjgtfAoeKPT3lYXREJ8c4LRETjGO0qOC0eQxv9-; isg=BFhY8mH9swr4n50_CEdVCJGAKYbqQbzL7c1_CJJJURNkLfkXO1AXW6NLZWUdPXSj"
}
看一下效果:
import requests
import re
url = 'https://rate.taobao.com/feedRateList.htm?'
headers = {
'referer':'https://item.taobao.com/item.htm?id=616727555136&ali_trackid=2:mm_12238993_43806065_714972723:1597052770_255_1467045357&spm=a231o.7712113%2Fg.1004.35&pvid=200_11.27.93.104_284878_1597052761050&bxsign=tbk159705277066145c815046b62c30a7b16b4c95524bc36',
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36',
'cookie':"cna=b/D8FYOTMVUCATrwJ8wV3AAV; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; miid=1525554089483641014; tracknick=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; tg=0; _samesite_flag_=true; cookie2=1b33c97adb02c7a77f9b89cfd5b171c4; t=0189b94436cd684bd44103b442e690f0; _tb_token_=38113a95557b8; v=0; UM_distinctid=173d7c2723922c-03c43fa2475c66-3323765-144000-173d7c2723a615; sgcookie=E2HGXmd4MlsLL6HyGk0KJ; uc3=vt3=F8dBxG2m6DG9ZRDBCCM%3D&id2=UUjXbEBZkN7mJw%3D%3D&lg2=Vq8l%2BKCLz3%2F65A%3D%3D&nk2=1TxKfiqLL2jq2i9bmfnbrTmayVA%3D; csg=84f3fcd6; lgc=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; dnk=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; skt=dfc81f3d58f5b26e; existShop=MTU5NzA1MjczMQ%3D%3D; uc4=id4=0%40U2o1ZOW2sQbQakAQ5T12awSrkm3p&nk4=0%401%2BCc9B0f4Q5M%2F%2BMtI%2FU07r71QIM2V4fqLr0KgI3bXg%3D%3D; _cc_=W5iHLLyFfA%3D%3D; lLtC1_=1; enc=4tzEh0tXDSIEBX1SFap7WowBYIv7XkkJzvG9nbq9RshD9LloBqEnF9xLJhJiDTYADhWncQtfr4F5XQH1KsK%2FGQ%3D%3D; mt=ci=-1_0; uc1=cookie14=UoTV6ymGDU%2BQ%2FQ%3D%3D&pas=0&existShop=false&cookie21=W5iHLLyFeYZ1WM9hVnmS&cookie15=URm48syIIVrSKA%3D%3D&cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D; tfstk=cX-VBuGytmn4JcjsJisacWBGduEAatCGOuWFoehGk99TM-IVTsq_6TcYHTWN90bc.; l=eBSQWiJnqBSbB8NFBO5Zourza77tBIRb8sPzaNbMiInca6tP6UIYhNQqlbfkJdtjgtfAoeKPT3lYXREJ8c4LRETjGO0qOC0eQxv9-; isg=BFhY8mH9swr4n50_CEdVCJGAKYbqQbzL7c1_CJJJURNkLfkXO1AXW6NLZWUdPXSjcna=b/D8FYOTMVUCATrwJ8wV3AAV; thw=cn; hng=CN%7Czh-CN%7CCNY%7C156; miid=1525554089483641014; tracknick=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; tg=0; _samesite_flag_=true; cookie2=1b33c97adb02c7a77f9b89cfd5b171c4; t=0189b94436cd684bd44103b442e690f0; _tb_token_=38113a95557b8; v=0; UM_distinctid=173d7c2723922c-03c43fa2475c66-3323765-144000-173d7c2723a615; sgcookie=E2HGXmd4MlsLL6HyGk0KJ; uc3=vt3=F8dBxG2m6DG9ZRDBCCM%3D&id2=UUjXbEBZkN7mJw%3D%3D&lg2=Vq8l%2BKCLz3%2F65A%3D%3D&nk2=1TxKfiqLL2jq2i9bmfnbrTmayVA%3D; csg=84f3fcd6; lgc=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; dnk=%5Cu8BFB%5Cu4F60%5Cu7684%5Cu611F%5Cu89C9%5Cu50CF%5Cu6625%5Cu5929%5Cu5684%5Cu5416; skt=dfc81f3d58f5b26e; existShop=MTU5NzA1MjczMQ%3D%3D; uc4=id4=0%40U2o1ZOW2sQbQakAQ5T12awSrkm3p&nk4=0%401%2BCc9B0f4Q5M%2F%2BMtI%2FU07r71QIM2V4fqLr0KgI3bXg%3D%3D; _cc_=W5iHLLyFfA%3D%3D; lLtC1_=1; enc=4tzEh0tXDSIEBX1SFap7WowBYIv7XkkJzvG9nbq9RshD9LloBqEnF9xLJhJiDTYADhWncQtfr4F5XQH1KsK%2FGQ%3D%3D; mt=ci=-1_0; uc1=cookie14=UoTV6ymGDU%2BQ%2FQ%3D%3D&pas=0&existShop=false&cookie21=W5iHLLyFeYZ1WM9hVnmS&cookie15=URm48syIIVrSKA%3D%3D&cookie16=U%2BGCWk%2F74Mx5tgzv3dWpnhjPaQ%3D%3D; tfstk=cX-VBuGytmn4JcjsJisacWBGduEAatCGOuWFoehGk99TM-IVTsq_6TcYHTWN90bc.; l=eBSQWiJnqBSbB8NFBO5Zourza77tBIRb8sPzaNbMiInca6tP6UIYhNQqlbfkJdtjgtfAoeKPT3lYXREJ8c4LRETjGO0qOC0eQxv9-; isg=BFhY8mH9swr4n50_CEdVCJGAKYbqQbzL7c1_CJJJURNkLfkXO1AXW6NLZWUdPXSj"
}
params = {
'auctionNumId': 616727555136,
'currentPageNum': 1
}
page = requests.get(url,params=params, headers=headers).text
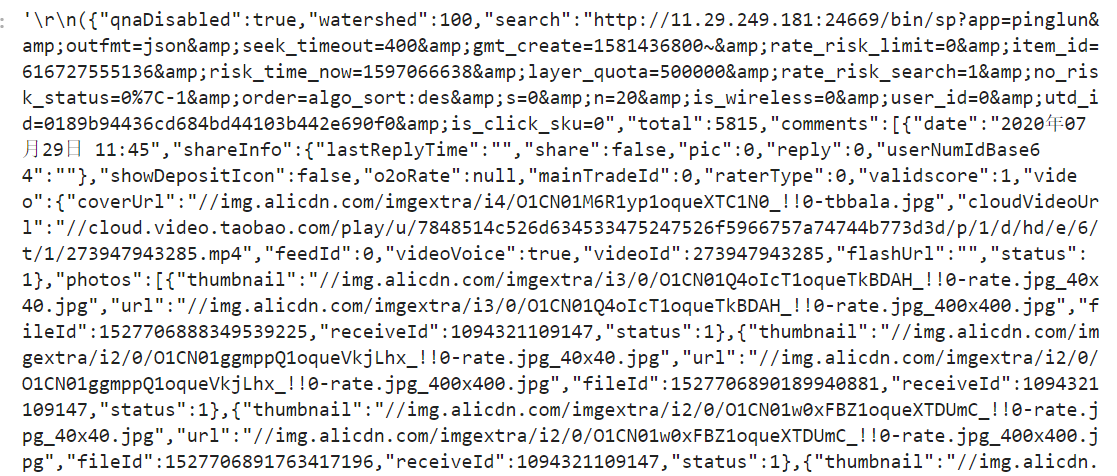
将开头的 \r\n 替换掉后,可以其转化为 json 格式的文件。
page = re.sub(r'[\n\r()]', '', page)
page=json.loads(content)
# 或者一步到位
# page=json.loads(re.sub(r'[\n\r()]', '', page))
转化后的文件内容为 json 格式的文件;
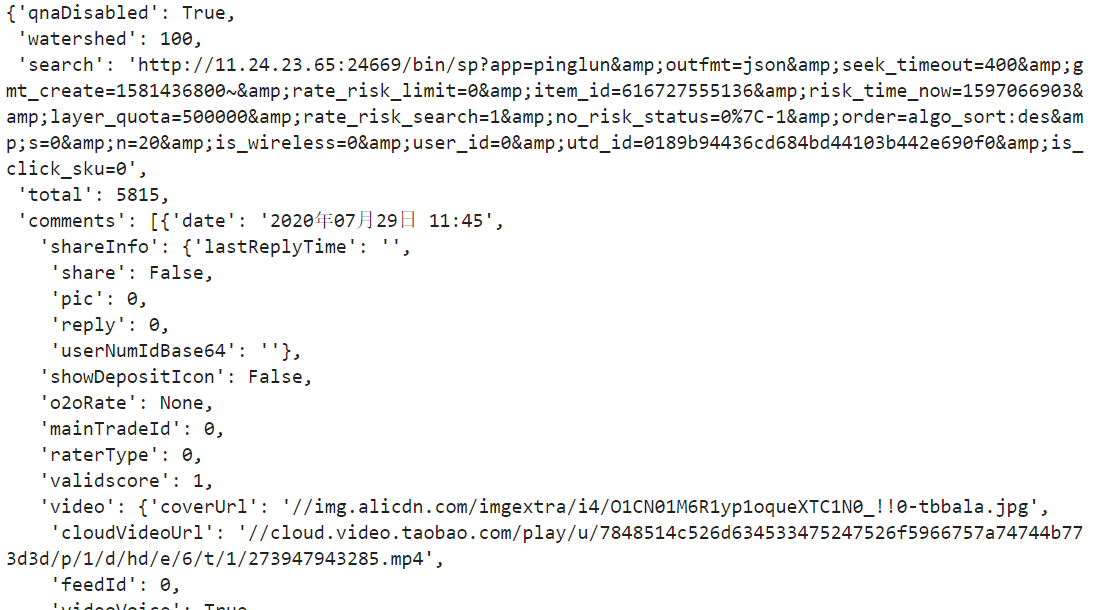
如果这里不将获取到的页面转为 json 格式的文件,我们可以用正则表达式获取我们所需要的内容。
查看原网页我们可以知道,商品的评论在 comments 下的 content 对应的内容;
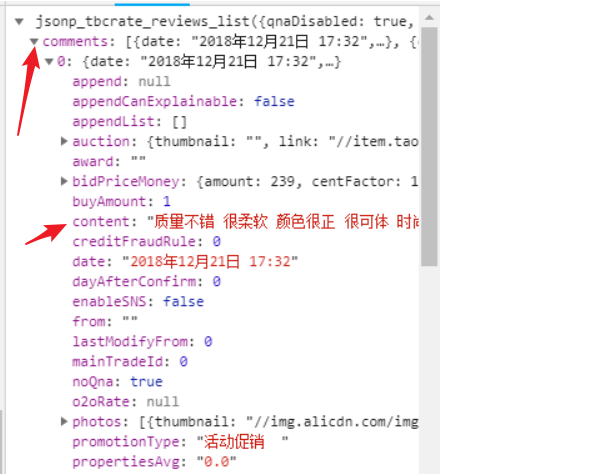
查看 都有哪些关键字:
page.keys()
# dict_keys(['qnaDisabled', 'watershed', 'search', 'total', 'comments', 'currentPageNum', 'maxPage'])
我们可以利用关键字获取我们所需的参数:
# 总共有多少评论
page['total']
# 用户的评论,为一个字典组成的列表
page['comments']
len(page['comments']) # 当前页多少评论
# 20
# 获取每一条评论
for item in page['comments']:
print(item['content'])

这部分只是获取了用户的评论内容。同样的我们也可以获取其它内容。
参考: