requests库
安装
使用pip进行安装
要安装 requests,最方便快捷的方法是使用 pip 进行安装。
pip install requests
如果还没有安装pip,这个链接 Properly Installing Python 详细介绍了在各种平台下如何安装 python 以及 setuptools,pip,virtualenv 等常用的 python 工具,可以参考其中的步骤来进行安装。
发送请求与传递参数
使用 Requests 发送网络请求非常简单。
一开始要导入 Requests 模块:
>>> import requests
然后,尝试获取某个网页。本例子中,我们来获取 Github 的公共时间线:
>>> r = requests.get('https://api.github.com/events')
现在,我们有一个名为 r 的 Response 对象。我们可以从这个对象中获取所有我们想要的信息。
Requests 简便的 API 意味着所有 HTTP 请求类型都是显而易见的。例如,你可以这样发送一个 HTTP POST 请求:
>>> r = requests.post('http://httpbin.org/post', data = {'key':'value'})
漂亮,对吧?那么其他 HTTP 请求类型:PUT,DELETE,HEAD 以及 OPTIONS 又是如何的呢?都是一样的简单:
>>> r = requests.put('http://httpbin.org/put', data = {'key':'value'})
>>> r = requests.delete('http://httpbin.org/delete')
>>> r = requests.head('http://httpbin.org/get')
>>> r = requests.options('http://httpbin.org/get')
都很不错吧,但这也仅是 Requests 的冰山一角呢。
传递 URL 参数
你也许经常想为 URL 的查询字符串(query string)传递某种数据。如果你是手工构建 URL,那么数据会以键/值对的形式置于 URL 中,跟在一个问号的后面。例如, httpbin.org/get?key=val。 Requests 允许你使用 params 关键字参数,以一个字符串字典来提供这些参数。举例来说,如果你想传递 key1=value1 和 key2=value2 到 httpbin.org/get ,那么你可以使用如下代码:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.get("http://httpbin.org/get", params=payload)
通过打印输出该 URL,你能看到 URL 已被正确编码:
>>> print(r.url)
http://httpbin.org/get?key2=value2&key1=value1
注意字典里值为 None 的键都不会被添加到 URL 的查询字符串里。
你还可以将一个列表作为值传入:
>>> payload = {'key1': 'value1', 'key2': ['value2', 'value3']}
>>> r = requests.get('http://httpbin.org/get', params=payload)
>>> print(r.url)
http://httpbin.org/get?key1=value1&key2=value2&key2=value3
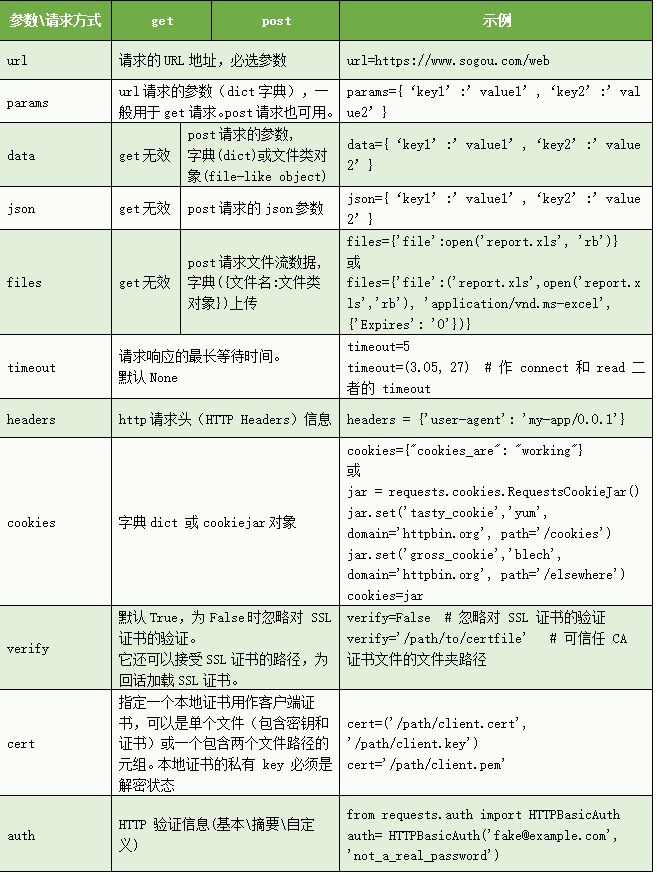
参数说明
http 请求 get 与 post 是最常用的,url 为必选参数,常用常用参数有params、data、json、files、timeout、headers、cookies;其他基本用不到的有verify,cert,auth,allow_redirects,proxies,hooks,stream。
下面列表对具体的参数说明:
重点在 params、data、json、files、timeout,其次headers、cookies,其他略过就可以。
Response对象
get请求是最简单的、发送的数据量比较小。
使用 requests方法后,会返回一个response对象,其存储了服务器响应的内容,如上实例中已经提到的 r.text、r.status_code…… 获取文本方式的响应体实例:当你访问 r.text 之时,会使用其响应的文本编码进行解码,并且你可以修改其编码让 r.text 使用自定义的编码进行解码。
r = requests.get('http://www.itwhy.org')
print(r.text, '\n{}\n'.format('*'*79), r.encoding)
r.encoding = 'GBK'
print(r.text, '\n{}\n'.format('*'*79), r.encoding)
其他响应:
r.status_code # 响应状态码
r.encoding # 获取网页编码
r.raw #返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read() 读取
r.content #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩
r.text #字符串方式的响应体,会自动根据响应头部的字符编码进行解码
r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
#*特殊方法*#
r.json() #Requests中内置的JSON解码器
r.raise_for_status() #失败请求(非200响应)抛出异常
- 示例2.1: 带多个参数的请求,返回文本数据
import requests
# 带参数的GET请求,timeout请求超时时间
params = {'key1': 'python', 'key2': 'java'}
r = requests.get(url='http://httpbin.org/get', params=params, timeout=3)
# 注意观察url地址,它已经将参数拼接起来
print('URL地址:', r.url)
# 响应状态码,成功返回200,失败40x或50x
print('请求状态码:', r.status_code)
print('header信息:', r.headers)
print('cookie信息:', r.cookies)
print('响应的数据:', r.text)
# 如响应是json数据 ,可以使用 r.json()自动转换为dict
print('响应json数据', r.json())
- 示例2.2:get 返回二进制数据,如图片。
from PIL import Image
from io import BytesIO
import requests
# 请求获取图片并保存
r = requests.get('https://pic3.zhimg.com/247d9814fec770e2c85cc858525208b2_is.jpg')
i = Image.open(BytesIO(r.content))
# i.show() # 查看图片
# 将图片保存
with open('img.jpg', 'wb') as fd:
for chunk in r.iter_content():
fd.write(chunk)
post请求,上传表单,文本,文件\图片
post 请求比 get 复杂,请求的数据有多种多样,有表单(form-data),文本(json\xml等),文件流(图片\文件)等。
要发送POST请求,只需要把get()方法变成post(),然后传入data参数作为POST请求的数据:
表单形式提交的post请求,只需要将数据传递给post()方法的data参数。见示例3.1.
json文本形式提交的post请求,一种方式是将json数据dumps后传递给data参数,另一种方式就是直接将json数据传递给post()方法的json参数。见示例3.2.
单个文件提交的post请求,将文件流给post()方法的files参数。见示例3.3。
多个文件提交的post请求,将文件设到一个元组的列表中,其中元组结构为 (form_field_name, file_info);然后将数据传递给post()方法的files。见示例3.4
- 示例3.1:post 表单请求
import requests, json
# 带参数表单类型post请求
data={'custname': 'woodman','custtel':'13012345678','custemail':'woodman@11.com',
'size':'small'}
r = requests.post('http://httpbin.org/post', data=data)
print('响应数据:', r.text)
- 示例3.2:post json请求
# json数据请求
url = 'https://api.github.com/some/endpoint'
payload = {'some': 'data'}
# 可以使用json.dumps(dict) 对编码进行编译
r = requests.post(url, data=json.dumps(payload))
print('响应数据:', r.text)
# 可以直接使用json参数传递json数据
r = requests.post(url, json=payload)
print('响应数据:', r.text)
- 示例3.3:post提交单个文件
# 上传单个文件
url = 'http://httpbin.org/post'
# 注意文件打开的模式,使用二进制模式不容易发生错误
files = {'file': open('report.txt', 'rb')}
# 也可以显式地设置文件名,文件类型和请求头
# files = {'file': ('report.xls', open('report.xls', 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}
r = requests.post(url, files=files)
r.encoding = 'utf-8'
print(r.text)
注意:文件的上传使用二进制打开不容易报错。
- 示例3.4:上传多个文件
url = 'http://httpbin.org/post'
multiple_files = [
('images', ('foo.png', open('foo.png', 'rb'), 'image/png')),
('images', ('bar.png', open('bar.png', 'rb'), 'image/png'))]
r = requests.post(url, files=multiple_files)
print(r.text)
定制请求头
获取 get 与 post 请求响应的 header 与 cookie 分别使用 r.headers 与r.cookies 。如果提交请求数据是对 header 与 cookie 有修改,需要在get()与post()方法中加入 headers 或 cookies 参数,它们值的类型都是字典
- 示例4.1:定制请求头header
import requests
url = 'https://api.github.com/some/endpoint'
headers = {'user-agent': 'my-app/0.0.1'}
r = requests.get(url, headers=headers)
print(r.headers) # 获取响应数据的header信息
注意:requests自带headers管理,一般情况下不需要设置header信息。Requests 不会基于定制 header 的具体情况改变自己的行为。只不过在最后的请求中,所有的 header 信息都会被传递进去。
- 示例4.2:定制cookie信息
# 直接以字典型时传递cookie
url = 'http://httpbin.org/cookies'
cookies = {"cookies_are":'working'}
r = requests.get(url, cookies=cookies)
# 获取响应的cookie信息,返回结果是RequestsCookieJar对象
print(r.cookies)
print(r.text)
session与cookie存储
会话对象requests.Session能够跨请求地保持某些参数,比如cookies,即在同一个Session实例发出的所有请求都保持同一个cookies,而requests模块每次会自动处理cookies,这样就很方便地处理登录时的cookies问题。
如果你向同一主机发送多个请求,每个请求对象让你能够跨请求保持session和cookie信息,这时我们要使用到requests的Session()来保持回话请求的cookie和session与服务器的相一致。
import requests
url = "http://www.renren.com/PLogin.do"
data = {"email":"970138074@qq.com",'password':"pythonspider"}
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"
}
# 登录
session = requests.session()
session.post(url,data=data,headers=headers)
# 访问大鹏个人中心
resp = session.get('http://www.renren.com/880151247/profile')
print(resp.text)
requests请求返回对象Response的常用方法
requests.get(url) 与 requests.post(url) 的返回对象为Response 类对象。
Response响应类常用属性与方法:
Response.url 请求url,[见示例2.1]
Response.status_code 响应状态码,[见示例2.1]
Response.text 获取响应内容,[见示例2.1]
Response.content 以字节形式获取响应提,多用于非文本请求,[见示例2.2]
Response.json() 活动响应的JSON内容,[见示例2.1]
Response.ok 请求是否成功,status_code<400 返回True
Response.headers 响应header信息,[见示例2.1]
Response.cookies 响应的cookie,[见示例2.1]
Response.elapsed 请求响应的时间。
Response.links 返回响应头部的links连接,相当于Response.headers.get('link')
Response.raw 获取原始套接字响应,需要将初始请求参数stream=True
Response.encoding 查看响应头部字符编码
Response.iter_content() 迭代获取响应数据,[见示例2.2]
Response.history 重定向请求历史记录
Response.reason 响应状态的文本原因,如:"Not Found" or "OK"
Response.close() 关闭并释放链接,释放后不能再次访问’raw’对象。一般不会调用。