Scrapy介绍
写一个爬虫,需要做很多的事情。比如:发送网络请求、数据解析、数据存储、反反爬虫机制(更换ip代理、设置请求头等)、异步请求等。这些工作如果每次都要自己从零开始写的话,比较浪费时间。因此Scrapy 把一些基础的东西封装好了,在他上面写爬虫可以变的更加的高效(爬取效率和开发效率)。因此真正在公司里,一些上了量的爬虫,都是使用Scrapy框架来解决。
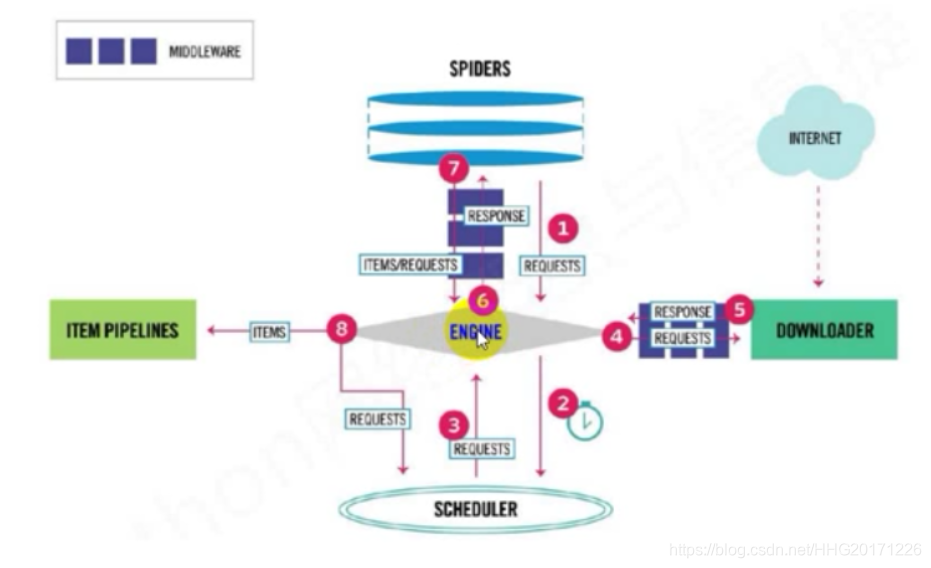
Scrapy框架模块功能
- Scrapy Engine(引擎): Scrapy框架的核心部分。负责在Spider和 ItemPipeline、Downloader、Scheduler中间通信、传递数据等。
- Spider(爬虫):发送需要爬取的链接给引擎,最后引擎把其他模块请求回来的数据再发送给爬虫,爬虫就去解析想要的数据。这个部分是我们开发者自己写的,因为要爬取哪些链接,页面中的哪些数据是我们需要的,都是由程序员自己决定。
- Scheduler(调度器):负责接收引擎发送过来的请求,并按照一定的方式进行排列和整理,负责调度请求的顺序等。
- Downloader(下载器):负责接收引擎传过来的下载请求,然后去网络上下载对应的数据再交还给引擎。
- Item Pipeline(管道):负责将Spider(爬虫)传递过来的数据进行保存。具体保存在哪里,应该看开发者自己的需求。
- Downloader Middlewares(下载中间件):可以扩展下载器和引擎之间通信功能的中间件。
- Spider Middlewares(Spider中间件):可以扩展引擎和爬虫之间通信功能的中间件。
安装和文档
- 安装
pip install scrapy
"""
注意:如果在windows系统下,提示这个错误
ModuleNotFoundError: No module named ‘win32api’,
那么使用以下命令可以解决:pip install pypiwin32。
"""
创建项目
要使用Scrapy框架创建项目,需要通过命令来创建。首先进入到你想把这个项目存放的目录。然后使用以下命令创建:
#scrapy startproject [项目名称]
scrapy startproject qss
目录结构介绍:
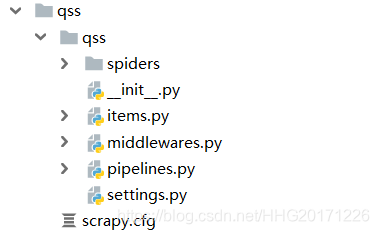
以下介绍下主要文件的作用:
- items.py:用来存放爬虫爬取下来数据的模型。
- middlewares.py:用来存放各种中间件的文件。
- pipelines.py:用来将items的模型存储到本地磁盘中。
- settings.py:本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)。
- scrapy.cfg:项目的配置文件。
- spiders包:以后所有的爬虫,都是存放到这个里面。
定义Item
Item 是保存爬取到的数据的容器;其使用方法和python字典类似, 并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field 的类属性来定义一个Item。
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
编写第一个爬虫(Spider)
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类
其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。
为了创建一个Spider,您必须继承 scrapy.Spider 类, 且定义以下三个属性:
name: 用于区别Spider。 该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls: 包含了Spider在启动时进行爬取的url列表。 因此,第一个被获取到的页面将是其中之一。 后续的URL则从初始的URL获取到的数据中提取。parse()是spider的一个方法。 被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。 该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
使用命令创建一个爬虫
首先进入项目的文件夹 cd spider
scrapy genspider qsbk "qiushibaike.com"
创建了一个名字叫做 qsbk 的爬虫,并且能爬取的网页只会限制在 qiushibaike.com 这个域名下。
创建项目和爬虫:
- 创建项目:
scrapy startproject [爬虫的名字]。- 创建爬虫:进入到项目所在的路径,执行命令:
scrapy genspider [爬虫名字] [爬虫的域名]。注意,爬虫名字不能和项目名称一致。
运行scrapy项目
进入项目的根目录,执行下列命令启动spider:
# scrapy crawl [爬虫名字]
scrapy crawl qsbk
如果不想每次都在命令行中运行,那么可以把这个命令写在一个文件中。以后就在pycharm中执行运行这个文件就可以了。比如现在新创建一个文件叫做start.py,然后在这个文件中填入以下代码:
from scrapy import cmdline
cmdline.execute("scrapy crawl qsbk".split())