XGBoost
xgboost库
有两种方式可以来使用我们的xgboost库。第一种方式,是直接使用xgboost库自己的建模流程

其中最核心的,是DMtarix这个读取数据的类,以及train()这个用于训练的类。与sklearn把所有的参数都写在类中的方式不同,xgboost库中必须先使用字典设定参数集,再使用train来将参数及输入,然后进行训练。会这样设计的原因,是因为XGB所涉及到的参数实在太多,全部写在xgb.train()中太长也容易出错。在这里,准备了params可能的取值以及xgboost.train的列表
params {eta, gamma, max_depth,
min_child_weight, max_delta_step, subsample,
colsample_bytree,colsample_bylevel,
colsample_bynode, lambda, alpha,
tree_method string, sketch_eps, scale_pos_weight,
updater,refresh_leaf, process_type, grow_policy,
max_leaves, max_bin, predictor, num_parallel_tree}
xgboost.train (params, dtrain, num_boost_round=10,
evals=(), obj=None, feval=None,
maximize=False,early_stopping_rounds=None,
evals_result=None, verbose_eval=True,
xgb_model=None, callbacks=None,
learning_rates=None)
class xgboost.DMatrix(data,
label=None,
weight=None,
base_margin=None,
missing=None,
silent=False,
feature_names=None,
feature_types=None,
nthread=None)
property feature_names¶
Get feature names (column labels).
property feature_types¶
Get feature types (column types).
get_label()¶
Get the label of the DMatrix.
Returns
label
Return type
array
num_col()¶
Get the number of columns (features) in the DMatrix.
Returns
number of columns
Return type
predict(data, output_margin=False, ntree_limit=0, pred_leaf=False, pred_contribs=False, approx_contribs=False, pred_interactions=False, validate_features=True, training=False)¶
Predict with data.
Returns
- prediction
Return type
- numpy array
Plotting
您可以使用绘图模块来绘制重要性和输出树。
To plot importance, use xgboost.plot_importance(). This function requires matplotlib to be installed.
num_round = 10
bst = xgb.train(param, dtrain, num_round, evallist)
xgb.plot_importance(bst)
To plot the output tree via matplotlib, use xgboost.plot_tree(), specifying the ordinal number of the target tree. This function requires graphviz and matplotlib.
xgb.plot_tree(bst, num_trees=2)
When you use IPython, you can use the xgboost.to_graphviz() function, which converts the target tree to a graphviz instance. The graphviz instance is automatically rendered in IPython.
xgb.to_graphviz(bst, num_trees=2)
Scikit-Learn API
class xgboost.XGBRegressor(objective='reg:squarederror'
, **kwargs)
Parameters :
提升集成算法:重要参数
n_estimators,n_estimators(int) : 集成中弱评估器的数量,或则弱学习器的最大迭代次数,默认 100,| 参数含义 | xgb.train() | xgb.XGBRegressor() | | ---------------------------- | ----------------- | --------------------- | | 集成中弱评估器的数量 | num_round,默认10 | n_estimators,默认100 | | 训练中是否打印每次训练的结果 | slient,默认False | slient,默认True |
有放回随机抽样:重要参数
subsample,subsample(float) : 随机抽样的时候抽取的样本比例,默认1, 范围(0,1] 。(数据量小时,取默认值即可)| 参数含义 | xgb.train() | xgb.XGBRegressor() | | --------------------------------------- | ---------------- | ------------------ | | 随机抽样的时候抽取的样本比例,范围(0,1] | subsample,默认1 | subsample,默认1 |
迭代决策树:重要参数
eta, 使用参数learning_rate来干涉我们的学习速率:| 参数含义 | xgb.train() | xgb.XGBRegressor() | | ----------------------------------------------------------- | -------------------------- | ------------------------------------ | | 集成中的学习率,又称为步长 以控制迭代速率,常用于防止过拟合 | eta,默认0.3 取值范围[0,1] | learning_rate,默认0.1 取值范围[0,1] |
learning_rate(float) :集成学习中的学习率,又称为步长以控制迭代速率,防止过拟合,也称之为每个弱学习器的权重缩减系数,取值范围 (0,1] , 取较小的值意味着达到一定的学习效果,需要更多的迭代次数和更多的弱学习器,默认为 0.1。通常,不调整 ,即便调整,一般它也会在[0.01,0.2]之间变动
通常用学习率和弱学习器的最大迭代次数一起来决定算法的拟合效果,所以这两个参数
n_estimators和learning_rate要一起调参。
选择弱评估器:重要参数
booster参数“booster"来控制我们究竟使用怎样的弱评估器| xgb.train() & params | xgb.XGBRegressor() | | ------------------------------------------------------------ | ------------------------------------------------------------ | | xgb_model | booster | | 使用哪种弱评估器。可以输入
gbtree, gblinear或dart。输入的评估器不同,使用 的params参数也不同,每种评估器都有自 己的params列表。评估器必须于param参 数相匹配,否则报错。 | 使用哪种弱评估器。可以输入gbtree,gblinear或dart。 gbtree代表梯度提升树,dart是Dropouts meet Multiple Additive Regression Trees,可译为抛弃提升树,在建树的过 程中会抛弃一部分树,比梯度提升树有更好的防过拟合功能。 输入gblinear使用线性模型。 |XGB的目标函数:重要参数
objective,objective(string or callable) : 指定要使用的学习任务和相应的学习目标或自定义目标函数 。使用参数“objective"来确定我们目标函数的第一部分中的 ,也就是衡量损失的部分
| xgb.train() | xgb.XGBRegressor() | xgb.XGBClassifier() | | ------------------------ | ------------------------- | ------------------------------ | | obj:默认binary:logistic | objective:默认reg:linear | objective:默认binary:logistic |
常用的选择有:
| 输入 | 选用的损失函数 | | ------------------ | ------------------------------------------------------ | |
reg:linear| 使用线性回归的损失函数,均方误差,回归时使用 | |binary:logistic| 使用逻辑回归的损失函数,对数损失log_loss,二分类时使用 | |binary:hinge| 使用支持向量机的损失函数,Hinge Loss,二分类时使用 | |multi:softmax| 使用 softmax 损失函数,多分类时使用 |
对于每一个样本而言的叶子权重,然而在一个叶子节点上的所有样本所对应的叶子权重是相同的。设一棵树上总共包含了 个叶子节点,其中每个叶子节点的索引为 ,则这个叶子节点上的样本权重是 。依据这个,我们定义模型的复杂度 为(注意这不是唯一可能的定义,我们当然还可以使用其他的定义,只要满足叶子越多/深度越大,复杂度越大的理论,我们可以自己决定我们的 要是一个怎样的式子):
如 果 使 用 正 则 项 :
如 果 使 用 正 则 项 :
还 可 以 两 个 一 起 使 用 :
这个结构中有两部分内容,一部分是控制树结构的 ,另一部分则是我们的正则项。叶子数量 可以代表整个树结构,这是因为在XGBoost中所有的树都是CART树(二叉树),所以我们可以根据叶子的数量 判断出树的深度, 而是我们自定的控制叶子数量的参数 。
根据我们以往的经验,我们往往认为两种正则化达到的效果是相似的,只不过细节不同 。
参数化决策树 (复杂度函数):参数alpha,lambda 正则化系数分别对应的参数:
reg_alpha(float (xgb's alpha)) : L1正则项的参数 , 默认0,取值范围[0, +∞]reg_lambda(float (xgb's lambda)) : L2正则项的参数 , 默认1,取值范围[0, +∞]
(可以使用其中的一个,也可以两个同时使用)正则化系数分别对应的参数:
| 参数含义 | xgb.train() | xgb.XGBRegressor() | | :--------------------- | :----------------------------- | :--------------------------------- | | L1正则项的参数 \alpha | alpha,默认0,取值范围[0, +∞] | reg_alpha,默认0,取值范围[0, +∞] | | L2正则项的参数 \lambda | lambda,默认1,取值范围[0, +∞] | reg_lambda,默认1,取值范围[0, +∞] |
让树停止生长:重要参数
gamma,gamma(float) : 复杂度的惩罚项 , 默认0,取值范围[0, +∞]。又被称之为是“复杂性控制”(complexity control),所以 是我们用来防止过拟合的重要参数。实践证明, 是对梯度提升树影响最大的参数之一,其效果丝毫不逊色于
n_estimators和防止过拟合的神器max_depth。同时, 还是我们让树停止生长的重要参数.| 参数含义 | xgb.train() | xgb.XGBRegressor() | | -------------- | ----------------------------- | ----------------------------- | | 复杂度的惩罚项 | gamma,默认0,取值范围[0, +∞] | gamma,默认0,取值范围[0, +∞] |
大于0的,即只要目标函数还能够继续减小,我们就允许树继续进行分枝 , 设定越大,算法就越保守,树的叶子数量就越少,模型的复杂度就越低
max_depth(int) : 树的最大深度,默认值为 6 . Maximum tree depth for base learners
过拟合:剪枝参数与回归模型调参
| 参数含义 | xgb.train() | xgb.XGBRegressor() |
|---|---|---|
| 树的最大深度 | max_depth,默认6 | max_depth,默认6 |
| 每次生成树时随机抽样特征的比例 | colsample_bytree,默认1 | colsample_bytree,默认1 |
| 每次生成树的一层时 随机抽样特征的比例 | colsample_bylevel,默认1 | colsample_bylevel,默认1 |
| 每次生成一个叶子节点时 随机抽样特征的比例 | colsample_bynode,默认1 | N.A. |
| 一个叶子节点上所需要的最小 即叶子节点上的二阶导数之和 类似于样本权重 | min_child_weight,默认1 | min_child_weight,默认 1 |
这些参数中,树的最大深度是决策树中的剪枝法宝,算是最常用的剪枝参数 .
三个随机抽样特征的参数中,前两个比较常用 。
参数 min_child_weight不太常用 。
通常当我们获得了一个数据集后,我们先使用网格搜索找出比较合适的 n_estimators和 eta组合,然后使用gamma或者 max_depth观察模型处于什么样的状态(过拟合还是欠拟合,处于方差-偏差图像的左边还是右边?),最后再决定是否要进行剪枝。通常来说,对于XGB模型,大多数时候都是需要剪枝的。接下来我们就来看看使用 xgb.cv这个类来进行剪枝调参,以调整出一组泛化能力很强的参数 。
xgboost 交叉验函数
xgboost 库中的类 xgboost.cv()
xgboost.cv (params,
dtrain,
num_boost_round=10,
nfold=3,
stratified=False,
folds=None,
metrics=(),
obj=None,
feval=None,
maximize=False,
early_stopping_rounds=None,
fpreproc=None, as_pandas=True,
verbose_eval=None,
show_stdv=True,
seed=0,
callbacks=None,
shuffle=True)
自带的交叉验证函数对 进行调参。
Returns
- evaluation history
Return type
- list(string)
from sklearn.datasets import load_boston
import xgboost as xgb
import time
import datetime
data = load_boston()
X = data.data
y = data.target
#为了便捷,使用全数据
dfull = xgb.DMatrix(X,y)
#设定参数
param1 = {'silent':True,'obj':'reg:linear',"gamma":0}
num_round = 180
n_fold=5
#使用类xgb.cv
time0 = time.time()
cvresult1 = xgb.cv(param1, dfull, num_round,n_fold)
#看看类xgb.cv生成了什么结果?
cvresult1
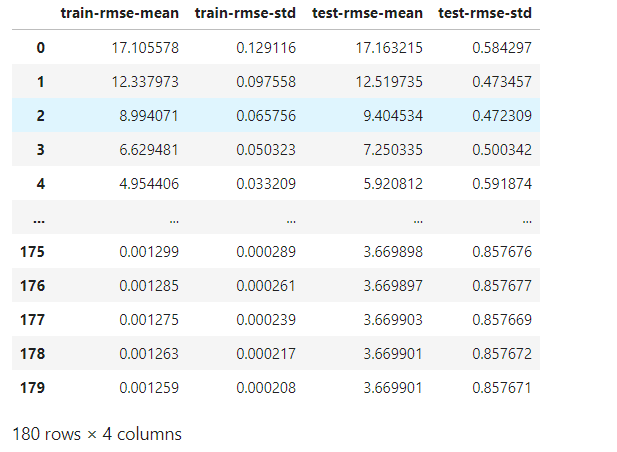
import matplotlib.pyplot as plt
plt.figure(figsize=(10,6))
plt.grid()
plt.plot(range(1,181),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,181),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.legend()
plt.show()
xgboost 中回归模型的默认模型评估指标是什么?
为了使用xgboost.cv,我们必须要熟悉xgboost自带的模型评估指标。xgboost在建库的时候本着大而全的目标,和sklearn类似,包括了大约20个模型评估指标,然而用于回归和分类的其实只有几个,大部分是用于一些更加高级的 功能比如ranking。来看用于回归和分类的评估指标都有哪些
| 指标 | 含义 |
|---|---|
| rmse | 回归用,调整后的均方误差 |
| mae | 回归用,绝对平均误差 |
| logloss | 二分类用,对数损失 |
| mlogloss | 多分类用,对数损失 |
| error | 分类用,分类误差,等于1-准确率 |
| auc | 分类用,AUC面积 |
若需要修改评价指标,可以修改 param 中的 eval_metric 参数。
param1 = {'silent':True,'obj':'reg:linear',"gamma":0,"eval_metric":"mae"}
cvresult1 = xgb.cv(param1, dfull, num_round,n_fold)
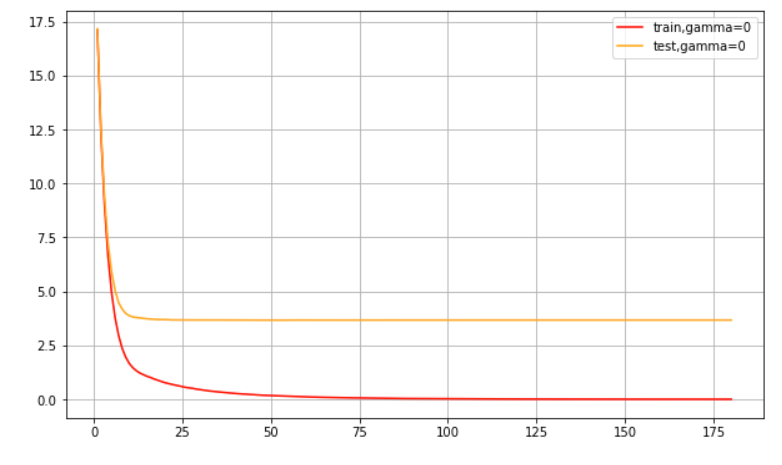
自带的交叉验证调整 的值:
param1 = {'silent':True,'obj':'reg:linear',"gamma":0}
param2 = {'silent':True,'obj':'reg:linear',"gamma":20}
num_round = 180
n_fold=5
cvresult1 = xgb.cv(param1, dfull, num_round,n_fold)
cvresult2 = xgb.cv(param2, dfull, num_round,n_fold)
plt.figure(figsize=(10,6))
plt.grid()
plt.plot(range(1,181),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,181),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.plot(range(1,181),cvresult2.iloc[:,0],c="green",label="train,gamma=20")
plt.plot(range(1,181),cvresult2.iloc[:,2],c="blue",label="test,gamma=20")
plt.legend()
plt.show()
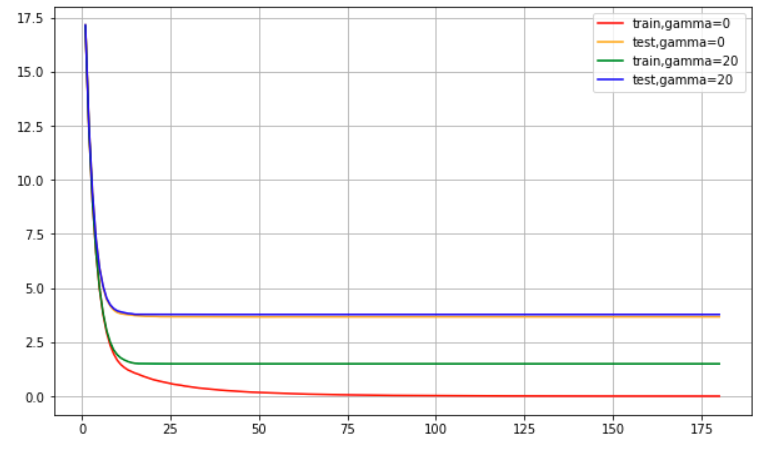
从这里,你看出gamma是如何控制过拟合了吗?
控制训练集上的数据集 - 降低训练集的表现。提高了模型的泛化能力。
下图中的第三种。
训练集上的表现展示了模型的学习能力,测试集上的表现展示了模型的泛化能力,通常模型在测试集上的表现不太可能超过训练集,因此我们希望我们的测试集的学习曲线能够努力逼近我们的训练集的学习曲线 。
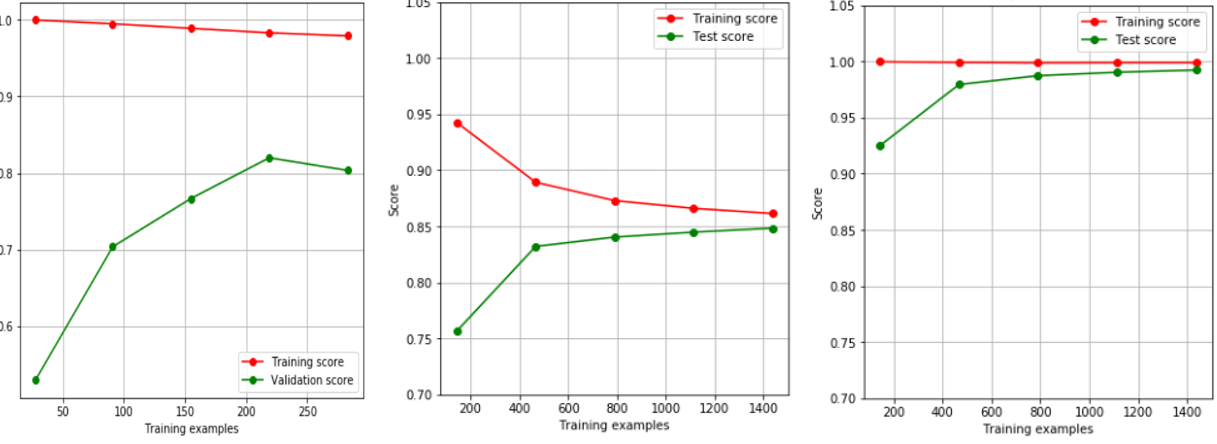
案例
param1 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"max_depth":6
,"eta":0.3
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":1
,"colsample_bynode":1
,"nfold":5}
num_round = 200
cvresult1 = xgb.cv(param1, dfull, num_round)
#调参结果1
param2 = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"eta":0.05
,"gamma":20
,"lambda":3.5
,"alpha":0.2
,"max_depth":4
,"colsample_bytree":0.4
,"colsample_bylevel":0.6
,"colsample_bynode":1
,"nfold":5}
#调参结果2
param3 = {'silent':True
,'obj':'reg:linear'
,"max_depth":2
,"eta":0.05
,"gamma":0
,"lambda":1
,"alpha":0
,"colsample_bytree":1
,"colsample_bylevel":0.4
,"colsample_bynode":1
,"nfold":5}
cvresult2 = xgb.cv(param2, dfull, num_round)
ax.plot(range(1,201),cvresult2.iloc[:,0],c="green",label="train,final")
ax.plot(range(1,201),cvresult2.iloc[:,2],c="blue",label="test,final")
ax.legend(fontsize="xx-large")
plt.show()
调参的时候参数的顺序会影响调参结果吗?
会影响,因此在现实中,我们会优先调整那些对模型影响巨大的参数。在这里,建议的剪枝上的调参顺序是:n_estimators与 eta共同调节,gamma或者max_depth,采样和抽样参数(纵向抽样影响更大),最后才是正则化
的两个参数。当然,可以根据自己的需求来进行调整
调参之后测试集上的效果还没有原始设定上的效果好怎么办?
如果调参之后,交叉验证曲线确实显示测试集和训练集上的模型评估效果是更加接近的,推荐使用调参之后的效果。我们希望增强模型的泛化能力,然而泛化能力的增强并不代表着在新数据集上模型的结果一定优秀,因为未知数据集 并非一定符合全数据的分布,在一组未知数据上表现十分优秀,也不一定就能够在其他的未知数据集上表现优秀。因此不必过于纠结在现有的测试集上是否表现优秀。当然了,在现有数据上如果能够实现训练集和测试集都非常优秀, 那模型的泛化能力自然也会是很强的
property coef_
Coefficients property
Returns
- coef_
Return type
- array of shape
[n_features]or[n_classes, n_features]
property feature_importances_
Feature importances property
Returns
- featureimportances
Return type
- array of shape
[n_features]
XGBoost模型的保存和调用
在使用Python进行编程时,我们可能会需要编写较为复杂的程序或者建立复杂的模型。比如XGBoost模型,这个模型的参数复杂繁多,并且调参过程不是太容易,一旦训练完毕,我们往往希望将训练完毕后的模型保存下来,以便日后用于新的数据集。在Python中,保存模型的方法有许多种 。
使用Pickle保存和调用模型
pickle 是python编程中比较标准的一个保存和调用模型的库,我们可以使用pickle 和 open 函数的连用,来将我们的模型保存到本地。以刚才我们已经调整好的参数和训练好的模型为例,我们可以这样来使用pickle
import pickle
dtrain = xgb.DMatrix(Xtrain,Ytrain)
#设定参数,对模型进行训练
param = {'silent':True
,'obj':'reg:linear'
,"subsample":1
,"eta":0.05
,"gamma":20
,"lambda":3.5
,"alpha":0.2
,"max_depth":4
,"colsample_bytree":0.4
,"colsample_bylevel":0.6
,"colsample_bynode":1}
num_round = 180
bst = xgb.train(param, dtrain, num_round)
#保存模型
pickle.dump(bst, open("xgboostonboston.dat","wb"))
#注意,open中我们往往使用w或者r作为读取的模式,但其实w与r只能用于文本文件,当我们希望导入的不是文本文件,而
是模型本身的时候,我们使用"wb"和"rb"作为读取的模式。其中wb表示以二进制写入,rb表示以二进制读入
#看看模型被保存到了哪里?
import sys
sys.path
#重新打开jupyter lab
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import mean_squared_error as MSE
import pickle
import xgboost as xgb
data = load_boston()
X = data.data
y = data.target
Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)
#注意,如果我们保存的模型是xgboost库中建立的模型,则导入的数据类型也必须是xgboost库中的数据类型
dtest = xgb.DMatrix(Xtest,Ytest)
#导入模型
loaded_model = pickle.load(open("xgboostonboston.dat", "rb"))
print("Loaded model from: xgboostonboston.dat")
#做预测
ypreds = loaded_model.predict(dtest)
from sklearn.metrics import mean_squared_error as MSE, r2_score
MSE(Ytest,ypreds)
r2_score(Ytest,ypreds)
使用Joblib保存和调用模型
Joblib是SciPy生态系统中的一部分,它为Python提供保存和调用管道和对象的功能,处理NumPy结构的数据尤其高效,对于很大的数据集和巨大的模型非常有用。Joblib与pickle API非常相似,来看看代码:
bst = xgb.train(param, dtrain, num_round)
import joblib
#同样可以看看模型被保存到了哪里
joblib.dump(bst,"xgboost-boston.dat")
loaded_model = joblib.load("xgboost-boston.dat")
ypreds = loaded_model.predict(dtest)
MSE(Ytest, ypreds)
r2_score(Ytest,ypreds)
#使用sklearn中的模型
from xgboost import XGBRegressor as XGBR
bst = XGBR(n_estimators=200
,eta=0.05,gamma=20
,reg_lambda=3.5
,reg_alpha=0.2
,max_depth=4
,colsample_bytree=0.4
,colsample_bylevel=0.6).fit(Xtrain,Ytrain)
joblib.dump(bst,"xgboost-boston.dat")
loaded_model = joblib.load("xgboost-boston.dat")
#则这里可以直接导入Xtest
ypreds = loaded_model.predict(Xtest)
MSE(Ytest, ypreds)
分类案例:XGB中的样本不均衡问题
存在分类,就会存在样本不平衡问题带来的影响,XGB中存在着调节样本不平衡的参数 scale_pos_weight,这个参数非常类似于之前随机森林和支持向量机中我们都使用到过的class_weight参数,通常我们在参数中输入的是负样本量与正样本量之比
| 参数含义 | xgb.train() | xgb.XGBClassifier() |
|---|---|---|
| 控制正负样本比例,表示为负/正样本比例 在样本不平衡问题中使用 | scale_pos_weight,默认1 | scale_pos_weight,默认1 |
导库,创建样本不均衡的数据集
import numpy as np
import xgboost as xgb
import matplotlib.pyplot as plt
from xgboost import XGBClassifier as XGBC
from sklearn.datasets import make_blobs
from sklearn.model_selection import train_test_split as TTS
from sklearn.metrics import confusion_matrix as cm, recall_score as recall, roc_auc_score
as auc
class_1 = 500 #类别1有500个样本
class_2 = 50 #类别2只有50个
centers = [[0.0, 0.0], [2.0, 2.0]] #设定两个类别的中心
clusters_std = [1.5, 0.5] #设定两个类别的方差,通常来说,样本量比较大的类别会更加松散
X, y = make_blobs(n_samples=[class_1, class_2],
centers=centers,
cluster_std=clusters_std,
random_state=0, shuffle=False)
Xtrain, Xtest, Ytrain, Ytest = TTS(X,y,test_size=0.3,random_state=420)
(y == 1).sum() / y.shape[0] #不平衡样本的比率
在数据集上建模:sklearn模式
#在sklearn下建模#
clf = XGBC().fit(Xtrain,Ytrain)
ypred = clf.predict(Xtest)
clf.score(Xtest,Ytest)
cm(Ytest,ypred,labels=[1,0])
recall(Ytest,ypred)
auc(Ytest,clf.predict_proba(Xtest)[:,1])
#负/正样本比例
clf_ = XGBC(scale_pos_weight=10).fit(Xtrain,Ytrain)
ypred_ = clf_.predict(Xtest)
clf_.score(Xtest,Ytest)
cm(Ytest,ypred_,labels=[1,0])
recall(Ytest,ypred_)
auc(Ytest,clf_.predict_proba(Xtest)[:,1])
#随着样本权重逐渐增加,模型的recall,auc和准确率如何变化?
for i in [1,5,10,20,30]:
clf_ = XGBC(scale_pos_weight=i).fit(Xtrain,Ytrain)
ypred_ = clf_.predict(Xtest)
print(i)
print("\tAccuracy:{}".format(clf_.score(Xtest,Ytest)))
print("\tRecall:{}".format(recall(Ytest,ypred_)))
print("\tAUC:{}".format(auc(Ytest,clf_.predict_proba(Xtest)[:,1])))
在数据集上建模:xgboost模式
dtrain = xgb.DMatrix(Xtrain,Ytrain)
dtest = xgb.DMatrix(Xtest,Ytest)
#看看xgboost库自带的predict接口
param= {'silent':True,'objective':'binary:logistic',"eta":0.1,"scale_pos_weight":1}
num_round = 100
bst = xgb.train(param, dtrain, num_round)
preds = bst.predict(dtest)
#看看preds返回了什么?
preds
#自己设定阈值
ypred = preds.copy()
ypred[preds > 0.5] = 1
ypred[ypred != 1] = 0
#写明参数
scale_pos_weight = [1,5,10]
names = ["negative vs positive: 1"
,"negative vs positive: 5"
,"negative vs positive: 10"]
#导入模型评估指标
from sklearn.metrics import accuracy_score as accuracy, recall_score as recall,
roc_auc_score as auc
for name,i in zip(names,scale_pos_weight):
param= {'silent':True,'objective':'binary:logistic'
,"eta":0.1,"scale_pos_weight":i}
clf = xgb.train(param, dtrain, num_round)
preds = clf.predict(dtest) #返回的时样本的概率
ypred = preds.copy()
ypred[preds > 0.5] = 1 #采用布尔索引,为不同概率的样本添加对应的标签
ypred[ypred != 1] = 0
print(name)
print("\tAccuracy:{}".format(accuracy(Ytest,ypred)))
print("\tRecall:{}".format(recall(Ytest,ypred)))
print("\tAUC:{}".format(auc(Ytest,preds)))
#当然我们也可以尝试不同的阈值
for name,i in zip(names,scale_pos_weight):
for thres in [0.3,0.5,0.7,0.9]:
param= {'silent':True,'objective':'binary:logistic'
,"eta":0.1,"scale_pos_weight":i}
clf = xgb.train(param, dtrain, num_round)
preds = clf.predict(dtest)
ypred = preds.copy()
ypred[preds > thres] = 1
ypred[ypred != 1] = 0
print("{},thresholds:{}".format(name,thres))
print("\tAccuracy:{}".format(accuracy(Ytest,ypred)))
print("\tRecall:{}".format(recall(Ytest,ypred)))
print("\tAUC:{}".format(auc(Ytest,preds)))
XGBoost类中的其他参数和功能
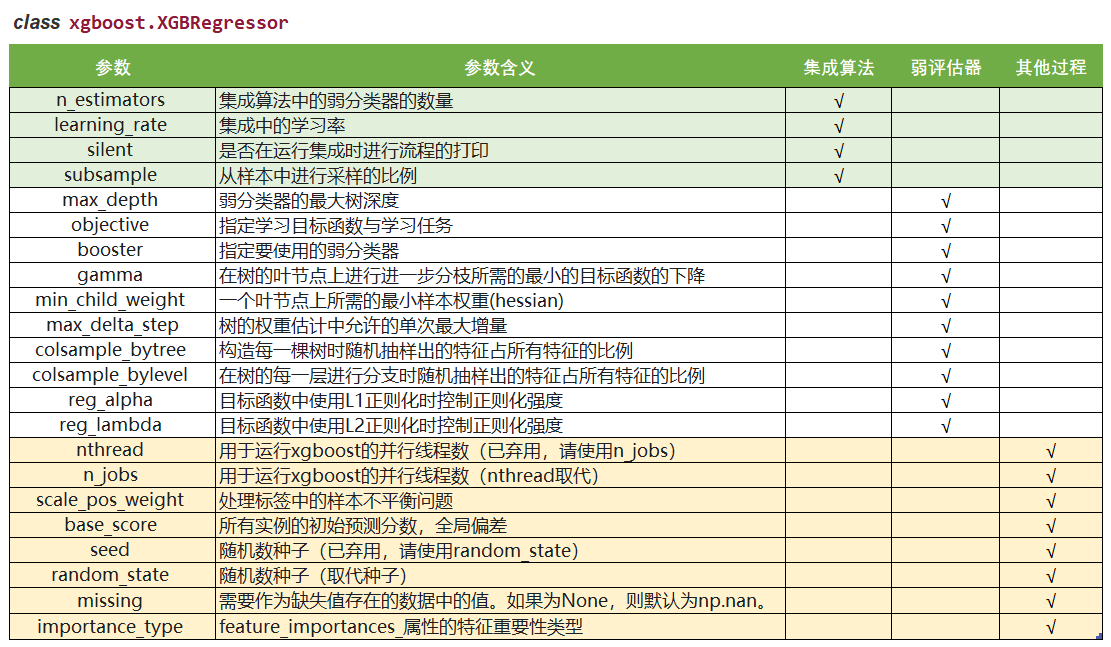
更多计算资源:
n_jobsnthread和n_jobs都是算法运行所使用的线程,与sklearn中规则一样,输入整数表示使用的线程,输入-1表示使用计算机全部的计算资源。如果我们的数据量很大,则我们可能需要这个参数来为我们调用更多线程降低学习难度:
base_scorebase_score是一个比较容易被混淆的参数,它被叫做全局偏差,在分类问题中,它是我们希望关注的分类的先验概率。比如说,如果我们有1000个样本,其中300个正样本,700个负样本,则base_score就是0.3。对于回归来说,这个分数默认0.5,但其实这个分数在这种情况下并不有效。许多使用XGBoost的人已经提出,当使用回归的时候base_score的默认应该是标签的均值,不过现在xgboost库尚未对此做出改进。使用这个参数,我们便是在告诉模型一些我们了解但模型不一定能够从数据中学习到的信息。通常我们不会使用这个参数,但对于严重的样本不均衡问题,设置一个正确的base_score取值是很有必要的。生成树的随机模式:
random_state在xgb库和sklearn中,都存在空值生成树的随机模式的参数random_state。在之前的剪枝中,我们提到可以通过随 机抽样样本,随机抽样特征来减轻过拟合的影响,我们可以通过其他参数来影响随机抽样的比例,却无法对随机抽样 干涉更多,因此,真正的随机性还是由模型自己生成的。如果希望控制这种随机性,可以在random_state参数中输 入固定整数。需要注意的是,xgb库和sklearn库中,在random_state参数中输入同一个整数未必表示同一个随机模 式,不一定会得到相同的结果,因此导致模型的feature_importances也会不一致。自动处理缺失值:
missingXGBoost被设计成是能够自动处理缺失值的模型,这个设计的初衷其实是为了让XGBoost能够处理稀疏矩阵。我们可以在参数missing中输入一个对象,比如np.nan,或数据的任意取值,表示将所有含有这个对象的数据作为空值处理。XGBoost会将所有的空值当作稀疏矩阵中的0来进行处理,因此在使用XGBoost的时候,我们也可以不处理缺失值。当然,通常来说,如果我们了解业务并且了解缺失值的来源,我们还是希望手动填补缺失值。