交叉验证cross_val_score
k折交叉验证评估模型性能

cross_val_score
交叉验证优点:
- 交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
- 还可以从有限的数据中获取尽可能多的有效信息
model_selection.cross_val_score(estimator,
X, y=None,
groups=None,
scoring=None,
cv=None,
n_jobs=None,
verbose=0,
fit_params=None,
pre_dispatch='2*n_jobs',
error_score=nan
)
参数:
estimator: 估计方法对象(分类器, 建立好的模型)X:数据特征(Features)y:数据标签(Labels)soring:调用方法(包括accuracy和mean_squared_error等等)cv:几折交叉验证n_jobs:同时工作的cpu个数(-1代表全部)fit_params:字典,将估计器中fit方法的参数通过字典传
返回值:
每次进行验证的分数列表
scoring参数值解析
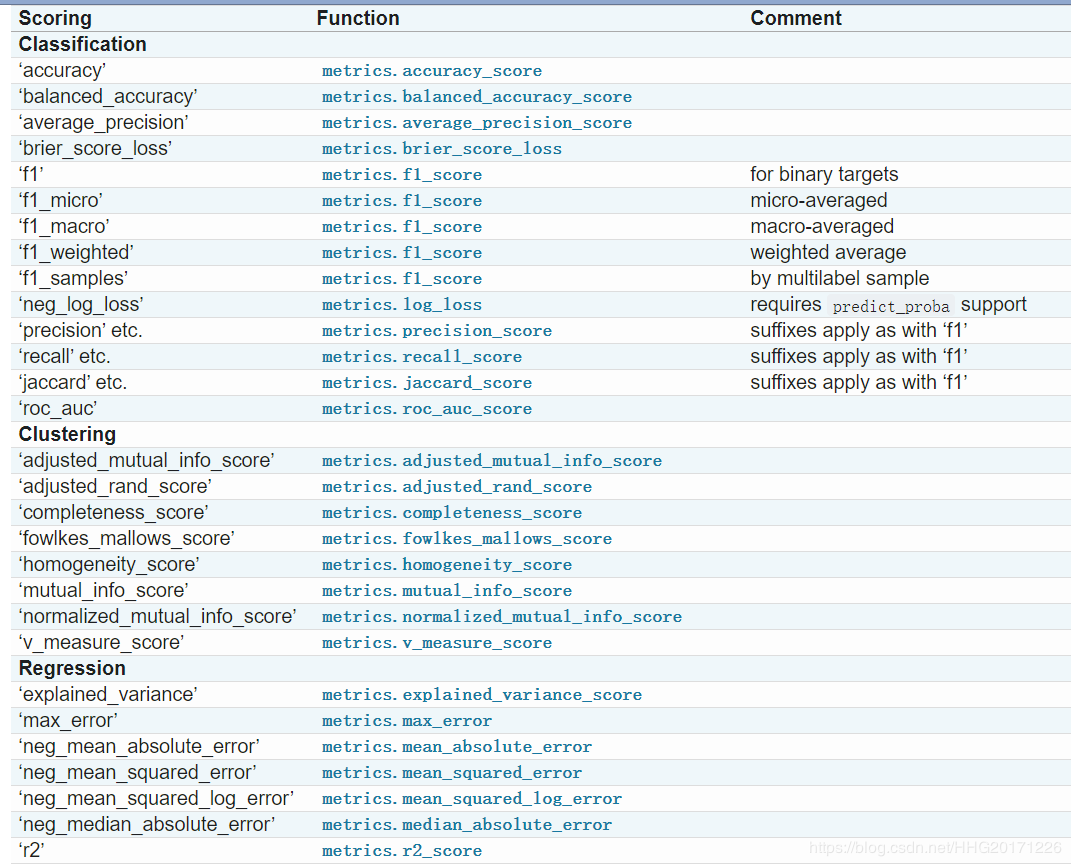
sklearn 中的参数 scoring下,均方误差作为评判标准时,却是计算”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中,所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差 MSE 的数值,其实就是 neg_mean_squared_error 去掉负号的数字。
案例
from sklearn import datasets, linear_model
from sklearn.model_selection import cross_val_score
import numpy as np
diabetes = datasets.load_diabetes()
X = diabetes.data[:150]
y = diabetes.target[:150]
lasso = linear_model.Lasso()
scores = cross_val_score(lasso, X, y, cv=3)
print("CV accuracy scores:%s" % scores)
print("CV accuracy:%.3f +/-%.3f" % (np.mean(scores), np.std(scores)))
结果:
CV accuracy scores:[0.33150734 0.08022311 0.03531764]
CV accuracy:0.149 +/-0.130