模型融合stacking
算法原理
集成学习方法主要分成三种:bagging,boosting 和 Stacking。这里主要介绍Stacking。
Stacking严格来说并不是一种算法,而是精美而又复杂的,对模型集成的一种策略。
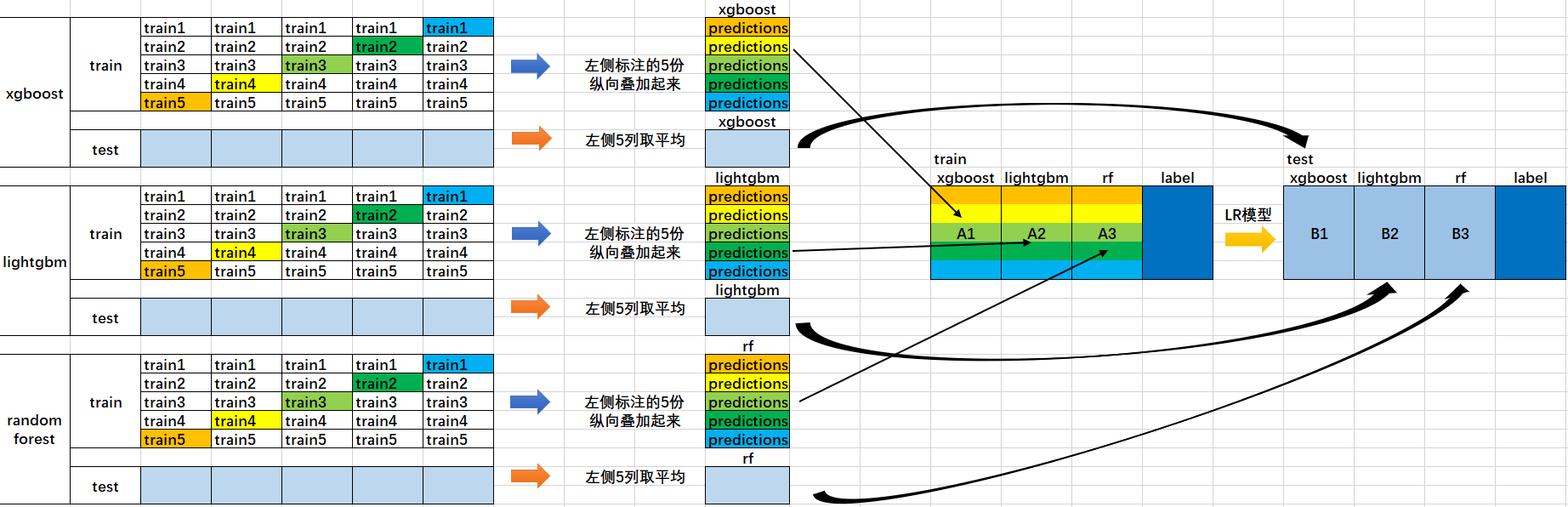
首先我们会得到两组数据:训练集和测试集。将训练集分成5份:train1, train2, train3, train4, train5。
选定基模型。这里假定我们选择了
xgboost,lightgbm和randomforest这三种作为基模型。比如
xgboost模型部分:依次用train1,train2,train3,train4,train5作为验证集,其余4份作为训练集,进行5折交叉验证进行模型训练;再在测试集上进行预测。这样会得到在训练集上由xgboost模型训练出来的5份predictions,和在测试集上的1份预测值B1(五次交叉验证在测试集上得到的预测值的平均值)。将这五份纵向重叠合并起来得到A1。lightgbm和randomforest模型部分同理。三个基模型训练完毕后,将三个模型在训练集上的预测值作为分别作为3个"特征"A1,A2,A3,使用LR模型进行训练,建立LR模型。
使用训练好的LR模型,在三个基模型之前在测试集上的预测值所构建的三个"特征"的值(B1,B2,B3)上,进行预测,得出最终的预测类别或概率。
以一个模型以为具体分析:
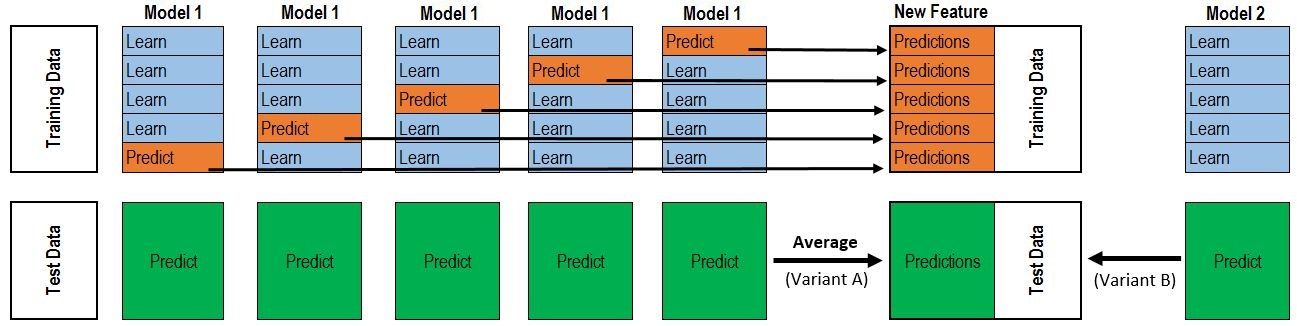
对于每一轮的 5-fold,Model 1都要做满5次的训练和预测。
Titanic 栗子:
Train Data有890行。(请对应图中的上层部分)
每1次的fold,都会生成 713行 小train, 178行 小test。我们用Model 1来训练 713行的小train,然后预测 178行 小test。预测的结果是长度为 178 的预测值。
这样的动作走5次! 长度为178 的预测值 X 5 = 890 预测值,刚好和Train data长度吻合。这个890预测值是Model 1产生的,我们先存着,因为,一会让它将是第二层模型的训练来源。
重点:这一步产生的预测值我们可以转成 890 X 1 (890 行,1列),记作 P1 (大写P)
接着说 Test Data 有 418 行。(请对应图中的下层部分,对对对,绿绿的那些框框)
每1次的fold,713行 小train训练出来的Model 1要去预测我们全部的Test Data(全部!因为Test Data没有加入5-fold,所以每次都是全部!)。此时,Model 1的预测结果是长度为418的预测值。
这样的动作走5次!我们可以得到一个 5 X 418 的预测值矩阵。然后我们根据行来就平均值,最后得到一个 1 X 418 的平均预测值。
重点:这一步产生的预测值我们可以转成 418 X 1 (418行,1列),记作 p1 (小写p)
走到这里,你的第一层的Model 1完成了它的使命。
第一层还会有其他Model的,比如Model 2,同样的走一遍, 我们又可以得到 890 X 1 (P2) 和 418 X 1 (p2) 列预测值。
这样吧,假设你第一层有3个模型,这样你就会得到:
来自5-fold的预测值矩阵 890 X 3,(P1,P2, P3) 和 来自Test Data预测值矩阵 418 X 3, (p1, p2, p3)。
到第二层了..................
来自5-fold的预测值矩阵 890 X 3 作为你的Train Data,训练第二层的模型 来自Test Data预测值矩阵 418 X 3 就是你的Test Data,用训练好的模型来预测他们吧。
python 实现
单个模型:
ntrain = train.shape[0] # 训练集样本数量 891
ntest = test.shape[0] # 测试集样本数量 418
fk = KFold(n_splits=5, random_state=21)
def get_oof(clf, Xtrain, y_train, X_test):
oof_train = np.zeros((ntrain,)) # 1*891
oof_test = np.zeros((ntest,)) # 1*418
off_test_skf = np.empty((5, ntest)) # 5*418
for j, (train_index, test_index) in enumerate(fk.split(X_train)):
fk_X_train = X_train[train_index] # 712*7 ex:712 instance for each folf
fk_y_train = y_train[train_index] # 712*1 ex:712 instance for each fold
fk_X_test = X_train[test_index] # 179*7 ex:179 instance for each fold
clf.train(fk.X_train, fk_y_train)
oof_train[test_index] = clf.predict(fk_X_test) # 1*179 ==> will be 1*891 after 5 fold
off_test_skf[i, :] = clf.predict(X_test) # oof_test_sfk[i,:] : 1*418
off_test[:] = off_test_skf.mean(axis=0) # off_test[:] 1*418
return oof_train.reshape(-1, 1), oof_test.reshape(-1, 1)
# oof_train.reshape(-1,1):891*1, oof_test.reshape(-1,1):418*1
使用mlxtend库
做stacking,首先需要安装mlxtend库。安装方法:进入Anaconda Prompt,输入命令 pip install mlxtend即可。
StackingClassifier使用API和参数说明:
StackingClassifier(classifiers,
meta_classifier,
use_probas=False,
average_probas=False,
verbose=0,
use_features_in_secondary=False)
参数:
classifiers: 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性self.clfs_.meta_classifier: 目标分类器,即将前面分类器合起来的分类器use_probas: bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签average_probas: bool (default: False),当上一个参数use_probas = True时需设置,average_probas=True表示所有基分类器输出的概率值需被平均,否则拼接。verbose: int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.use_features_in_secondary: bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
属性:
clfs_: 每个基分类器的属性,list, shape 为 [n_classifiers]。meta_clf_: 最终目标分类器的属性
方法:
fit(X, y)fit_transform(X, y=None, fit_params)get_params(deep=True),如果是使用sklearn的GridSearch方法,那么返回分类器的各项参数。predict(X)predict_proba(X)score(X, y, sample_weight=None), 对于给定数据集和给定label,返回评价accuracyset_params(params),设置分类器的参数,params的设置方法和sklearn的格式一样
备注:Stacking一般多是两层就够了,多层也是可以的。
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
from sklearn.cross_validation import train_test_split
from sklearn.cross_validation import StratifiedKFold
import numpy as np
from sklearn.metrics import roc_auc_score
from sklearn.datasets.samples_generator import make_blobs
'''创建训练的数据集'''
data, target = make_blobs(n_samples=50000, centers=2, random_state=0, cluster_std=0.60)
'''模型融合中使用到的各个单模型'''
clfs = [RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
'''切分一部分数据作为测试集'''
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.33, random_state=2017)
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs)))
'''5折stacking'''
n_folds = 5
skf = list(StratifiedKFold(y, n_folds))
for j, clf in enumerate(clfs):
'''依次训练各个单模型'''
# print(j, clf)
dataset_blend_test_j = np.zeros((X_predict.shape[0], len(skf)))
for i, (train, test) in enumerate(skf):
'''使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。'''
# print("Fold", i)
X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:, 1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_predict)[:, 1]
'''对于测试集,直接用这k个模型的预测值均值作为新的特征。'''
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_blend_test[:, j]))
# clf = LogisticRegression()
clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30)
clf.fit(dataset_blend_train, y)
y_submission = clf.predict_proba(dataset_blend_test)[:, 1]
print("Linear stretch of predictions to [0,1]")
y_submission = (y_submission - y_submission.min()) / (y_submission.max() - y_submission.min())
print("blend result")
print("val auc Score: %f" % (roc_auc_score(y_predict, y_submission)))
参考: