preprocessing.OneHotEncoder用法
在 sklearn 包中,OneHotEncoder 函数非常实用,它可以实现将分类特征的每个元素转化为一个可以用来计算的值。
class sklearn.preprocessing.OneHotEncoder(categories='auto',
drop=None,
sparse=True,
dtype=<class 'numpy.float64'>,
handle_unknown='error'
)
Parameters
sparse=True 、
表示编码的格式,默认为 True,即为稀疏的格式,指定 False 则就不用 toarray() 了
handle_unknown=’error’
其值可以指定为 "error" 或者 "ignore",即如果碰到未知的类别,是返回一个错误还是忽略它。
Attributes
categories_
查看特征中的类别
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,如下面的例子:
- 性别:["male","female"]
- 地区:["Europe","US","Asia"]
- 浏览器:["Firefox","Chrome","Safari","Internet Explorer"]
对于某一个样本,如["male","US","Internet Explorer"],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是这样的特征处理并不能直接放入机器学习算法中。
对于上述的问题,性别的属性是二维的,同理,地区是三维的,浏览器则是思维的,这样,我们可以采用One-Hot编码的方式对上述的样本“["male","US","Internet Explorer"]”编码,“male”则对应着[1,0],同理“US”对应着[0,1,0],“Internet Explorer”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。这样导致的一个结果就是数据会变得非常的稀疏。
Examples
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse = False)
ans = enc.fit_transform([[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]])
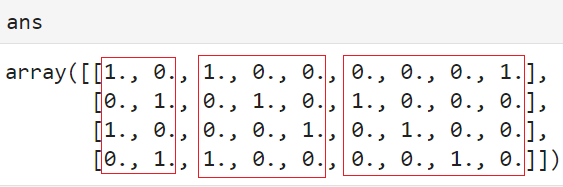
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(sparse = False)
ans = enc.fit([[0, 0, 3],
[1, 1, 0],
[0, 2, 1],
[1, 0, 2]])
enc.categories_
# [array([0., 1.]), array([0., 1., 2.]), array([0., 1., 2., 3.])]
编码与哑变量