feature_selection.SelectKBest用法
根据评分,选取的评分较高的 k 个特征。
class sklearn.feature_selection.SelectKBest(score_func=<function f_classif>,
k=10
)
Parameters
score_func
callable
函数接受两个数组X和y,并返回一对数组(分数,pvalue)或带分数的单个数组。
k
int or “all”, optional, default=10
Number of top features to select
Attributes
scores_
array-like of shape (n_features,)
Scores of features.
pvalues_
array-like of shape (n_features,)
p-values of feature scores, None if score_func returned only scores.
Methods
fit(self, X, y) |
Run score function on (X, y) and get the appropriate features. |
|---|---|
fit_transform(self, X[, y]) |
Fit to data, then transform it. |
get_params(self[, deep]) |
Get parameters for this estimator. |
get_support(self[, indices]) |
Get a mask, or integer index, of the features selected |
inverse_transform(self, X) |
Reverse the transformation operation |
set_params(self, **params) |
Set the parameters of this estimator. |
transform(self, X) |
Reduce X to the selected features. |
案例
import pandas as pd
#load sklearn built-in Boston dataset
from sklearn.datasets import load_boston
#Loading the dataset
x = load_boston()
data = pd.DataFrame(x.data, columns = x.feature_names)
data["MEDV"] = x.target
X = data.drop("MEDV",1) #Remove Target Variable to Get Feature Matrix
y = data["MEDV"] #Target Variable
data.head()
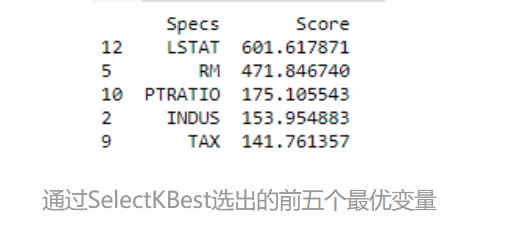
以下通过线性回归的F值来对各输入变量进行排序,并选出前五个预测效果最好的变量。我们可以看出,LSTAT分数最高,预测能力最好:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import f_regression
#apply SelectKBest class to extract top 5 best features
bestfeatures = SelectKBest(score_func=f_regression, k=5)
fit = bestfeatures.fit(X,y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X.columns)
#concat two dataframes for better visualization
featureScores = pd.concat([dfcolumns,dfscores],axis=1)
featureScores.columns = ['Specs','Score'] #naming the dataframe columns
print(featureScores.nlargest(5,'Score')) #print 5 best features