SequentialFeatureSelector
feature_selection
SequentialFeatureSelector
SequentialFeatureSelector(estimator,
k_features=1,
forward=True,
floating=False,
verbose=0,
scoring=None,
cv=5,
n_jobs=1,
pre_dispatch='2n_jobs',
clone_estimator=True,
fixed_features=None)
用于分类和回归的序列特征选择
Parameters :
estimator: scikit-learn classifier or regressork_features: int or tuple or str (default: 1)Number of features to select, where k_features < the full feature set. New in 0.4.2: A tuple containing a min and max value can be provided, and the SFS will consider return any feature combination between min and max that scored highest in cross-validtion. For example, the tuple (1, 4) will return any combination from 1 up to 4 features instead of a fixed number of features k. New in 0.8.0: A string argument "best" or "parsimonious". If "best" is provided, the feature selector will return the feature subset with the best cross-validation performance. If "parsimonious" is provided as an argument, the smallest feature subset that is within one standard error of the cross-validation performance will be selected.
forward: bool (default: True)如果为True,则为正向选择,否则为反向选择
verbose: int (default: 0), 日志记录中使用的详细级别。如果0,则无输出;如果1当前集合中的特征数;如果2,详细记录,包括步骤中的时间戳和cv分数。
scoring: str, callable, or None (default: None)If None (default), uses 'accuracy' for sklearn classifiers and 'r2' for sklearn regressors. If str, uses a sklearn scoring metric string identifier, for example {accuracy, f1, precision, recall, roc_auc} for classifiers, {'mean_absolute_error', 'mean_squared_error'/'neg_mean_squared_error', 'median_absolute_error', 'r2'} for regressors.
cv: int (default: 5)Integer or iterable yielding train, test splits. If cv is an integer and
estimatoris a classifier (or y consists of integer class labels) stratified k-fold. Otherwise regular k-fold cross-validation is performed. No cross-validation if cv is None, False, or 0.fixed_features: tuple (default: None)If not
None, the feature indices provided as a tuple will be regarded as fixed by the feature selector. For example, iffixed_features=(1, 3, 7), the 2nd, 4th, and 8th feature are guaranteed to be present in the solution. Note that iffixed_featuresis notNone, make sure that the number of features to be selected is greater thanlen(fixed_features). In other words, ensure thatk_features > len(fixed_features).
属性:
k_feature_idx_: array-like, shape = [n_predictions]所选特征子集的特征索引。
k_feature_names_: array-like, shape = [n_predictions]所选特征的名称,
k_score_: float所选子集的交叉验证平均分数。
subsets_: dict在穷举选择过程中选择的特征子集的字典,其中字典键是这些特征子集的长度k。字典值是字典本身,具有以下键:“feature_idx”(特征子集的索引元组)“feature_names”(特征名称的元组)。subset)“cv_scores”(列出单个交叉验证得分)“avg_score”(平均交叉验证得分)
Methods:
fit(X, y, custom_feature_names=None, groups=None,* *fit_params)
参数
进行特征选择并从训练数据中训练模型
X: {array-like, sparse matrix}, shape = [n_samples, n_features]Training vectors
y: array-like, shape = [n_samples]Target values
fit_transform(X, y, groups=None, fit_params)
对训练数据进行拟合,然后将X缩减为其最重要的特征。
返回值:
Returns
保留下的特征:shape={n个样本,k个特征}
get_metric_dict(confidence_interval=0.95)
Return metric dictionary
案例
加载数据集
#加载数据集
from mlxtend.feature_selection import SequentialFeatureSelector as SFS #SFS
from mlxtend.data import wine_data #dataset
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X, y = wine_data()
X.shape #(178, 13)
数据预处理
#数据预处理
X_train, X_test, y_train, y_test= train_test_split(X, y, stratify=y, test_size=0.3, random_state=1)
std = StandardScaler()
X_train_std = std.fit_transform(X_train)
循序向前特征选择
#循序向前特征选择
knn = KNeighborsClassifier(n_neighbors=3)
sfs = SFS(estimator=knn,
k_features=4,
forward=True,
floating=False,
verbose=2,
scoring='accuracy',
cv=0)
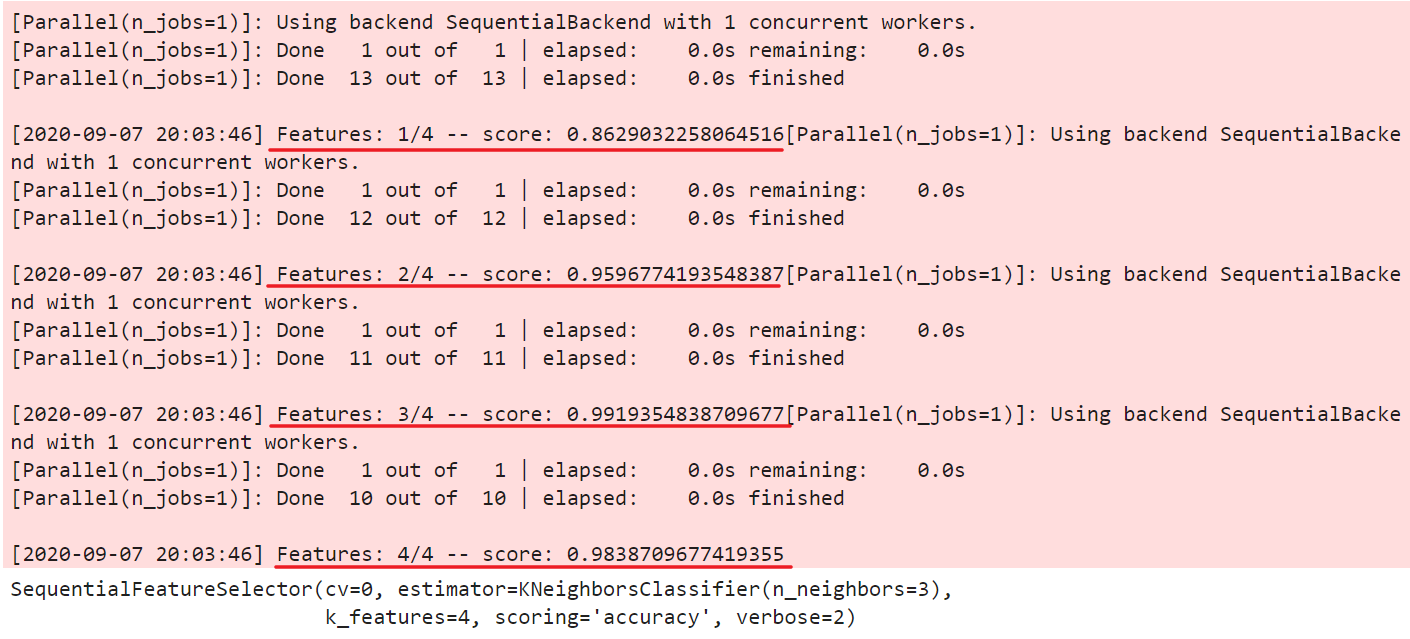
sfs.fit(X_train_std, y_train) #xy不能是df
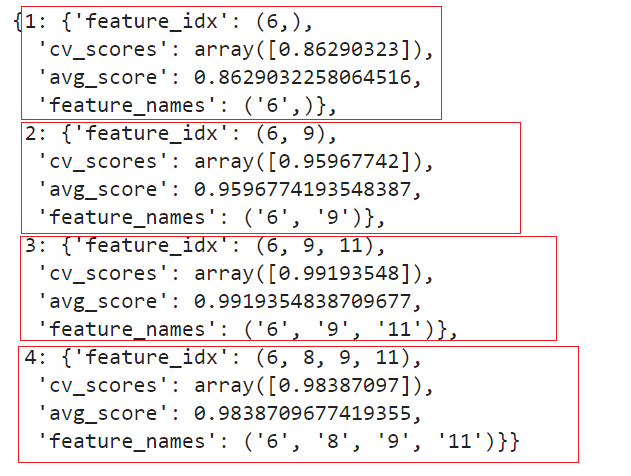
查看特征索引
#查看特征索引
sfs.subsets_
可视化#1 Plotting the results
%matplotlib inline
from mlxtend.plotting import plot_sequential_feature_selection as plot_sfs
fig = plot_sfs(sfs.get_metric_dict(), kind='std_err')
.png)
其中 sfs.get_metric_dict()的结果如下:
sfs.get_metric_dict()

可视化#2 Selecting the “best” feature combination in a k-range
knn = KNeighborsClassifier(n_neighbors=3)
sfs2 = SFS(estimator=knn,
k_features=(3, 10), # 特征的数量 in (3,10)
forward=True,
floating=True,
verbose=0,
scoring='accuracy',
cv=5) # 5 Fold
sfs2.fit(X_train_std, y_train)
fig = plot_sfs(sfs2.get_metric_dict(), kind='std_err')
.png)
此时带交叉验证的 get_metric_dict() 返回的结果:
sfs2.get_metric_dict()
结果:
{1: {'feature_idx': (6,),
'cv_scores': array([0.8 , 0.72 , 0.84 , 0.76 , 0.79166667]),
'avg_score': 0.7823333333333333,
'feature_names': ('6',),
'ci_bound': 0.05176033893650721,
'std_dev': 0.04027130216143722,
'std_err': 0.02013565108071861},
2: {'feature_idx': (6, 9),
'cv_scores': array([0.92 , 0.92 , 0.92 , 1. , 0.91666667]),
'avg_score': 0.9353333333333333,
'feature_names': ('6', '9'),
'ci_bound': 0.04159085255450659,
'std_dev': 0.03235909626536425,
'std_err': 0.016179548132682124},
3: {'feature_idx': (6, 9, 12),
'cv_scores': array([0.96, 0.92, 0.96, 1. , 1. ]),
'avg_score': 0.968,
'feature_names': ('6', '9', '12'),
'ci_bound': 0.03847294606910585,
'std_dev': 0.029933259094191523,
'std_err': 0.01496662954709576},
4: {'feature_idx': (3, 6, 9, 12),
'cv_scores': array([1. , 0.96 , 1. , 1. , 0.95833333]),
'avg_score': 0.9836666666666666,
'feature_names': ('3', '6', '9', '12'),
'ci_bound': 0.025720095411605862,
'std_dev': 0.020011108026404847,
'std_err': 0.010005554013202423},
5: {'feature_idx': (3, 6, 9, 10, 12),
'cv_scores': array([0.96, 0.96, 1. , 1. , 1. ]),
'avg_score': 0.984,
'feature_names': ('3', '6', '9', '10', '12'),
'ci_bound': 0.025186455367090216,
'std_dev': 0.019595917942265444,
'std_err': 0.009797958971132722},
6: {'feature_idx': (0, 3, 6, 9, 10, 12),
'cv_scores': array([0.96, 1. , 1. , 1. , 1. ]),
'avg_score': 0.992,
'feature_names': ('0', '3', '6', '9', '10', '12'),
'ci_bound': 0.020564654692917933,
'std_dev': 0.016000000000000014,
'std_err': 0.008000000000000007},
7: {'feature_idx': (0, 2, 3, 6, 9, 10, 12),
'cv_scores': array([0.96, 0.96, 1. , 1. , 1. ]),
'avg_score': 0.984,
'feature_names': ('0', '2', '3', '6', '9', '10', '12'),
'ci_bound': 0.025186455367090216,
'std_dev': 0.019595917942265444,
'std_err': 0.009797958971132722},
8: {'feature_idx': (0, 2, 3, 6, 7, 9, 10, 12),
'cv_scores': array([0.96, 0.96, 1. , 1. , 1. ]),
'avg_score': 0.984,
'feature_names': ('0', '2', '3', '6', '7', '9', '10', '12'),
'ci_bound': 0.025186455367090216,
'std_dev': 0.019595917942265444,
'std_err': 0.009797958971132722},
9: {'feature_idx': (0, 2, 3, 5, 6, 7, 9, 10, 12),
'cv_scores': array([0.96, 0.96, 1. , 1. , 1. ]),
'avg_score': 0.984,
'feature_names': ('0', '2', '3', '5', '6', '7', '9', '10', '12'),
'ci_bound': 0.025186455367090216,
'std_dev': 0.019595917942265444,
'std_err': 0.009797958971132722},
10: {'feature_idx': (0, 2, 3, 5, 6, 7, 8, 9, 10, 12),
'cv_scores': array([0.96 , 0.96 , 1. , 1. , 0.95833333]),
'avg_score': 0.9756666666666666,
'feature_names': ('0', '2', '3', '5', '6', '7', '8', '9', '10', '12'),
'ci_bound': 0.025548244297351058,
'std_dev': 0.019877402021167435,
'std_err': 0.009938701010583717}}
参考: