数据集划分K折交叉验证StratifiedKFold
StratifiedKFold 用法类似Kfold,但是它是分层采样,确保训练集,验证集中各类别样本的比例与原始数据集中相同。因此一般使用 StratifiedKFold。保证训练集中每一类的比例是相同的
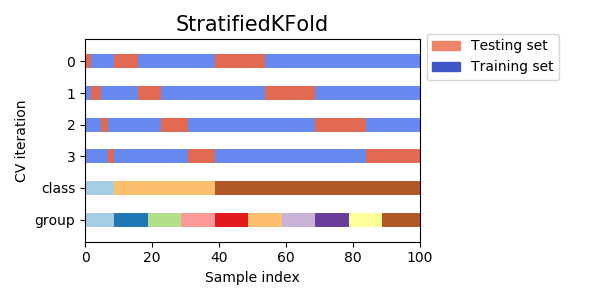
class sklearn.model_selection.StratifiedKFold(n_splits=5,
*,
shuffle=False,
random_state=None)
参数
n_splits:折叠次数,默认为3,至少为2。shuffle: 是否在每次分割之前打乱顺序。random_state: 随机种子,在shuffle==True时使用,默认使用np.random。
Methods
get_n_splits(self, X=None, y=None, groups=None)StratifiedKFold.split(X, y, groups=None)
参数:
X:array-like,shape(n_sample,n_features),训练数据集。y:array-like,shape(n_sample),标签。返回值:训练集数据的 index 与验证集数据的 index。
from sklearn.model_selection import StratifiedKFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [5, 6], [7, 8]])
y = np.array([0, 0, 0, 1, 1, 1]) # 1的个数和0的个数要大于3,3也就是n_splits
skf = StratifiedKFold(n_splits=3)
for train_index, test_index in skf.split(X, y):
print("TRAIN:", train_index, "TEST:", test_index)
结果:
TRAIN: [1 2 4 5] TEST: [0 3]
TRAIN: [0 2 3 5] TEST: [1 4]
TRAIN: [0 1 3 4] TEST: [2 5]
案例
# 加载数据
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv(
"http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data", header=None)
# 做基本的数据预处理
X = df.iloc[:, 2:].values
y = df.iloc[:, 1].values
le = LabelEncoder() # 将M-B等字符串编码成计算机能识别的0-1
y = le.fit_transform(y)
le.transform(['M', 'B'])
# 数据切分8:2
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, stratify=y, random_state=1)
# 分层 k折交叉验证
from sklearn.model_selection import StratifiedKFold
kfold = StratifiedKFold(n_splits=10, random_state=1).split(X_train, y_train)
scores2 = []
for k, (train, test) in enumerate(kfold):
pipe_lr1.fit(X_train[train], y_train[train])
score = pipe_lr1.score(X_train[test], y_train[test])
scores2.append(score)
print('Fold:%2d,Class dist.:%s,Acc:%.3f' %
(k+1, np.bincount(y_train[train]), score))
print('\nCV accuracy :%.3f +/-%.3f' % (np.mean(scores2), np.std(scores2)))
结果:
Fold: 1,Class dist.:[256 153],Acc:0.935
Fold: 2,Class dist.:[256 153],Acc:0.935
Fold: 3,Class dist.:[256 153],Acc:0.957
Fold: 4,Class dist.:[256 153],Acc:0.957
Fold: 5,Class dist.:[256 153],Acc:0.935
Fold: 6,Class dist.:[257 153],Acc:0.956
Fold: 7,Class dist.:[257 153],Acc:0.978
Fold: 8,Class dist.:[257 153],Acc:0.933
Fold: 9,Class dist.:[257 153],Acc:0.956
Fold:10,Class dist.:[257 153],Acc:0.956
CV accuracy :0.950 +/-0.014