随机分层数据集划分StratifiedShuffleSplit
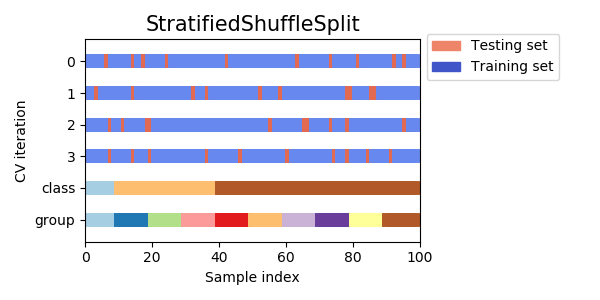
StratifiedShuffleSplit是ShuffleSplit的一个变体,返回分层划分,也就是在创建划分的时候要保证每一个划分中类的样本比例与整体数据集中的原始比例保持一致
StratifiedShuffleSplit 把数据集打乱顺序,然后划分测试集和训练集,训练集额和测试集的比例随机选定,训练集和测试集的比例的和可以小于1,但是还要保证训练集中各类所占的比例是一样的
函数
class sklearn.model_selection.StratifiedShuffleSplit(n_splits=10,
*,
test_size=None,
train_size=None,
random_state=None)
Methods
get_n_splits(self, X=None, y=None, groups=None)split(self, X, y, groups=None)
案例
import numpy as np
from sklearn.model_selection import StratifiedShuffleSplit
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2], [3, 4]])
y = np.array([0, 0, 0, 1, 1, 1])
sss = StratifiedShuffleSplit(n_splits=5, test_size=0.5, random_state=0)
sss.get_n_splits(X, y)
划分的次数
结果:5
print(sss)
# StratifiedShuffleSplit(n_splits=5, random_state=0, test_size=0.5,
train_size=None)
获取 训练/测试数据集
for train_index, test_index in sss.split(X, y):
# 打印划分后的索引
print("TRAIN:", train_index, "TEST:", test_index)
# 根据索引 获取对应的 训练集和测试集及对应的标签
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
结果:
TRAIN: [5 2 3] TEST: [4 1 0]
TRAIN: [5 1 4] TEST: [0 2 3]
TRAIN: [5 0 2] TEST: [4 3 1]
TRAIN: [4 1 0] TEST: [2 3 5]
TRAIN: [0 5 1] TEST: [3 4 2]