随机数据集划分ShuffleSplit
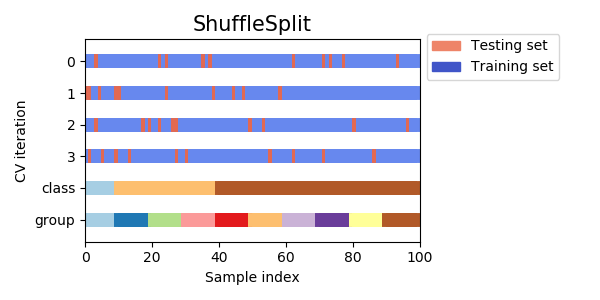
ShuffleSplit() 随机排列交叉验证,生成一个用户给定数量的独立的训练/测试数据划分。样例首先被打散然后划分为一对训练测试集合。
ShuffleSplit为一个迭代器,ShuffleSplit迭代器产生指定数量的独立的train/test数据集划分,首先对样本全体随机打乱,然后再划分出train/test对,可以使用随机数种子random_state来控制数字序列发生器使得讯算结果可重现
ShuffleSplit是KFlod交叉验证的比较好的替代,他允许更好的控制迭代次数和train/test的样本比例
函数
class sklearn.model_selection.ShuffleSplit(n_splits=10,
*,
test_size=None,
train_size=None,
random_state=None)
参数
n_splits:划分训练集、测试集的次数,默认为10test_size: 测试集比例或样本数量, 如果是float类型的数据, 这个数应该介于0-1.0之间,代表test集所占比例. 如果是int类型, 代表test集的数量. 如果为None, 值将自动设置为train集大小的补集train_size: float, int, or None (default is None) 如果是float类型的数据 应该介于0和1之间,并表示数据集在train集分割中所占的比例 如果是int类型, 代表train集的样本数量. 如果为None, 值将自动设置为test集大小的补集random_state:随机种子值,默认为None,可以通过设定明确的random_state,使得伪随机生成器的结果可以重复。
Methods
get_n_splits(self[, X, y, groups]) 返回交叉验证程序中拆分迭代的次数split(self, X[, y, groups]) 生成索引,将数据拆分为训练集和测试集。 参数:X训练数据,其中n_samples是样本数,n_features是特征数。y有监督学习问题的目标变量。groups将数据集拆分为列车/测试集时使用的样本的分组标签。
返回值:
trainndarrayThe training set indices for that split.
testndarrayThe testing set indices for that split.
案例
import numpy as np
from sklearn.model_selection import ShuffleSplit
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [3, 4], [5, 6]])
y = np.array([1, 2, 1, 2, 1, 2])
rs = ShuffleSplit(n_splits=5, test_size=.25, random_state=0)
rs.get_n_splits(X)
结果:5
print(rs)
#结果:
ShuffleSplit(n_splits=5, random_state=0, test_size=0.25, train_size=None)
使用 split() 获取划分后的索引值
for train_index, test_index in rs.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
结果
TRAIN: [1 3 0 4] TEST: [5 2]
TRAIN: [4 0 2 5] TEST: [1 3]
TRAIN: [1 2 4 0] TEST: [3 5]
TRAIN: [3 4 1 0] TEST: [5 2]
TRAIN: [3 5 1 0] TEST: [2 4]
指定不同的训练和测试数据集的比例
rs = ShuffleSplit(n_splits=5, train_size=0.5, test_size=.25,
random_state=0)
for train_index, test_index in rs.split(X):
print("TRAIN:", train_index, "TEST:", test_index)
结果
TRAIN: [1 3 0] TEST: [5 2]
TRAIN: [4 0 2] TEST: [1 3]
TRAIN: [1 2 4] TEST: [3 5]
TRAIN: [3 4 1] TEST: [5 2]
TRAIN: [3 5 1] TEST: [2 4]